如何解决数据类别不平衡问题(Data with Imbalanced Class)
类别不平衡问题是指:在分类任务中,数据集中来自不同类别的样本数目相差悬殊。
类别不平衡问题会造成这样的后果:在数据分布不平衡时,其往往会导致分类器的输出倾向于在数据集中占多数的类别:输出多数类会带来更高的分类准确率,但在我们所关注的少数类中表现不佳。
处理这个问题通常有3种方法:
1. 欠采样
假设数据集中反例占大多数,那么去除一些反例使得正、反例数目接近,然后再进行学习。由于丢弃了很多反例,分类器训练集会远小于初始训练集。欠采样的缺点是可能会丢失一些重要信息。因此通常利用集成学习机制,将反例划分为若干个集合供不同的学习器使用,这样就相当于对每个学习器都进行了欠采样,并且从全局来看不会丢掉重要信息。
代表算法:EasyEnsemble
利用集成学习机制,将反例划分为若干个集合供不同学习器使用,这样对每个学习器来看都进行了欠采样,但在全局来看却不会丢失重要信息。
算法原理:
- 首先通过从多数类中独立随机抽取出若干子集。
- 将每个子集与少数类数据联合起来训练生成多个基分类器。
- 最终将这些基分类器组合形成一个集成学习系统。
EasyEnsemble 算法被认为是非监督学习算法,因此它每次都独立利用可放回随机抽样机制来提取多数类样本。
2. 过采样
假设数据集中反例占大多数,那么对训练集里的正类样例进行“过采样”,增加一些正例使得正、反例数目接近,然后再进行学习。但是不能直接对正例进行复制,这样容易引起过拟合。一般采用代表性算法SMOTE算法。它是通过对训练集里的正例进行插值来产生额外的正例。过采样的缺点是由于增加了很多正例,使得其训练集远大于初始训练集,时间开销远大于欠采样。
代表算法:SMOTE(Synthetic Minority Oversampling Technique)
通过对训练集里的正例进行插值来产生额外的正例。它利用 k 近邻算法来分析已有的少数类样本,从而合成在特征空间内的新的少数类样本。
算法原理:
SMOTE 算法是建立在相距较近的少数类样本之间的样本仍然是少数类的假设基础上的,它是利用特征空间中现存少数类样本之间的相似性来建立人工数据的。这里我们简单的介绍 SMOTE 算法的思想。
下图表示一个数据集: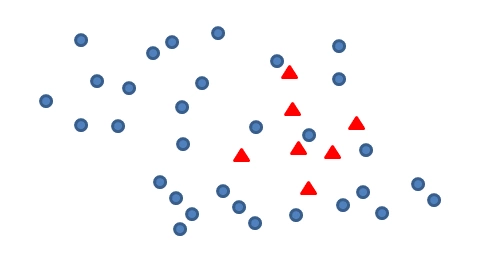
可以看出,蓝色样本数量远远大于红色样本,在常规调用分类模型去判断的时候可能会导致之间忽视掉红色样本带了的影响,只强调蓝色样本的分类准确性,因此需要增加红色样本来平衡数据集。
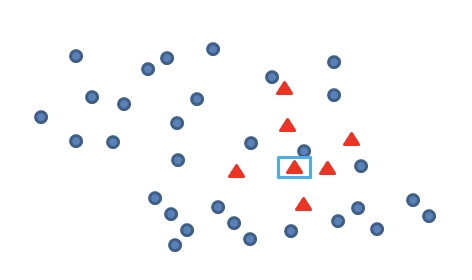
先随机选定 n 个少类的样本:
再找出最靠近它的 m 个少类样本: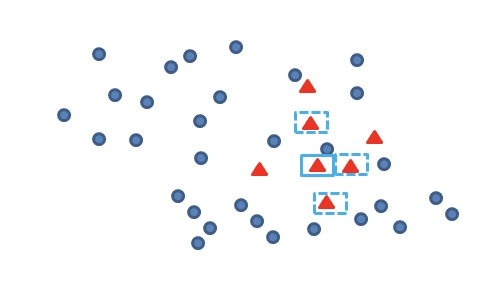
再任选最临近的 m 个少类样本中的任意一点:
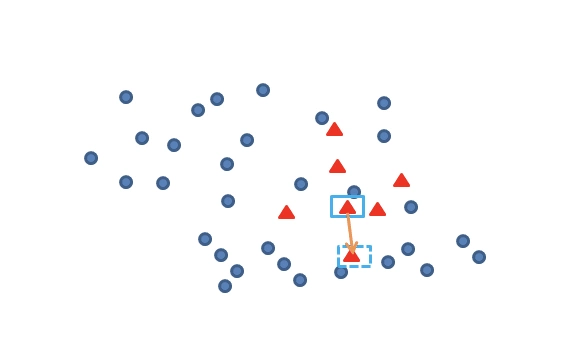
在这两点上任选一点,这点就是新增的数据样本。
3. 阈值移动
基于原始训练集进行学习,但在用训练好的分类器进行预测时,将再缩放的公式嵌入到决策过程中,称为“阈值移动”。
在二分类任务中,我们将样本属于正类的概率记为p,因此样本属于负类的概率就是1-p。当p/(1-p)>1时,我们把样本分为正类。但这是在样本均衡的情况下,也就是说正负样本的比例接近于1,此时分类阈值为0.5。如果样本不均衡,那么我们需要在预测时修改分类阈值。
假设在数据集中有m个正样本,n个负样本,那么正负样本的观测几率为m/n(样本均衡的情况下观测几率为1)。在进行分类时,如果此时的几率p'/(1-p')大于实际的观测几率m/n,我们才把样本分为正类。此时m/(m+n) 取代0.5成为新的分类阈值。
如何解决数据类别不平衡问题(Data with Imbalanced Class)的更多相关文章
- 机器学习之类别不平衡问题 (2) —— ROC和PR曲线
机器学习之类别不平衡问题 (1) -- 各种评估指标 机器学习之类别不平衡问题 (2) -- ROC和PR曲线 完整代码 ROC曲线和PR(Precision - Recall)曲线皆为类别不平衡问题 ...
- 不平衡数据下的机器学习方法简介 imbalanced time series classification
imbalanced time series classification http://www.vipzhuanli.com/pat/books/201510229367.5/2.html?page ...
- 机器学习类别不平衡处理之欠采样(undersampling)
类别不平衡就是指分类任务中不同类别的训练样例数目差别很大的情况 常用的做法有三种,分别是1.欠采样, 2.过采样, 3.阈值移动 由于这几天做的project的target为正值的概率不到4%,且数据 ...
- [ML] 解决样本类别分布不均衡的问题
转自:3.4 解决样本类别分布不均衡的问题 | 数据常青藤 (组织排版上稍有修改) 3.4 解决样本类别分布不均衡的问题 说明:本文是<Python数据分析与数据化运营>中的“3.4 解决 ...
- 类别不平衡问题之SMOTE算法(Python imblearn极简实现)
类别不平衡问题类别不平衡问题,顾名思义,即数据集中存在某一类样本,其数量远多于或远少于其他类样本,从而导致一些机器学习模型失效的问题.例如逻辑回归即不适合处理类别不平衡问题,例如逻辑回归在欺诈检测问题 ...
- 随想:目标识别中,自适应样本均衡设计,自适应模型结构(参数可变自适应,模型结构自适应,数据类别or分布自适应)
在现在的机器学习中,很多人都在研究自适应的参数,不需要人工调参,但是仅仅是自动调参就不能根本上解决 ai识别准确度达不到实际生产的要求和落地困难的问题吗?结论可想而知.如果不改变参数,那就得从算法的结 ...
- [MapReduce_add_3] MapReduce 通过分区解决数据倾斜
0. 说明 数据倾斜及解决方法的介绍与代码实现 1. 介绍 [1.1 数据倾斜的含义] 大量数据发送到同一个节点进行处理,造成此节点繁忙甚至瘫痪,而其他节点资源空闲 [1.2 解决数据倾斜的方式] 重 ...
- 压缩Sqlite数据文件大小,解决数据删除后占用空间不变的问题
最近有一网站使用Sqlite数据库作为数据临时性的缓存,对多片区进行划分 Sqlite数据库文件,每天大概新增近1万的数据量,起初效率有明显的提高,但历经一个多月后数据库文件从几K也上升到了近160M ...
- 试图使用未在此报表服务器中注册或此版 Reporting Services 不支持的数据扩展插件“Devart.Data.PostgreSql”
数据源用的是Postgresql 我在Deploy Report的时候出现这条ErrorMessage Error 2 试图使用未在此报表服务器中注册或此版 Reporting Services 不支 ...
随机推荐
- .NET 使用 ILRepack 合并多个程序集(替代 ILMerge),避免引入额外的依赖
原文:.NET 使用 ILRepack 合并多个程序集(替代 ILMerge),避免引入额外的依赖 我们有多种工具可以将程序集合并成为一个.比如 ILMerge.Mono.Merge.前者不可定制.运 ...
- springcolud 的学习(四)服务治理. Eureka
什么是服务治理在传统rpc远程调用中,服务与服务依赖关系,管理比较复杂,所以需要使用服务治理,管理服务与服务之间依赖关系,可以实现服务调用.负载均衡.容错等,实现服务发现与注册.服务注册与发现 在服务 ...
- Outlook 邮件助手
Outlook 邮件助手 1 Overview 2 C# 编程 3 Outlook 设置 3.1 Outlook 2013 3.2 Outlook 2010 1 Overview 本章将示例如何开发一 ...
- python关于try except的使用方法
一.常见错误总结 AttributeError 试图访问一个对象没有的树形,比如foo.x,但是foo没有属性x IOError 输入/输出异常;基本上是无法打开文件 ImportError 无法引入 ...
- Fluxay流光使用
扫描IPC主机 填写扫描地址.扫描类型为NT/98 显示如下,扫描成功 扫描用户列表 显示如下,扫描成功 下面想怎么做就怎么做 IPC连接失败原因 对方未打开IPC共享 对方未开启139或445端口 ...
- Load Balancing in gRPC
背景 基于每次调用的负载均衡 需要注意的是,gRPC的负载均衡发生在每次调用时,而不是每次连接时.换句话说,就算所有的请求来自于同一个客户,我们也希望可以将它们负载均衡到所有的服务器. 负载均衡的方法 ...
- centos7.6在线yum安装docker-ce
概述: 利用阿里的mirrror的docker-ce仓库,在线安装docker-ce 部署环境: CentOS Linux release 7.6.1810 (Core) 01.添加docker-ce ...
- cookie删除失效问题
在一个yii2的项目中使用了cookie,设置.获取都没有问题,但是在删除时候失败了. 要想删除cookie成功,只是设置cookie值为null,或设置时间为过期时间是不行的,还需要设置path,一 ...
- 嵌入式开发之移植OpenCv可执行程序到arm平台
0. 序言 PC操作系统:Ubuntu 16.04 OpenCv版本:4.0 交叉工具链:arm-linux-gnueabihf,gcc version 5.4.0 目标平台:arm 编译时间:201 ...
- Linux操作系统之更改启动菜单的背景图实战案例
Linux操作系统之更改启动菜单的背景图实战案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.制作图像并上传到服务器 1>.使用window 10操作系统自带的画图工具 ...