python数据分析5 数据转换
1数据转换
数据转换时数据准备的重要环节,它通过数据平滑,数据聚集,数据概化,规范化等凡是将数据转换成适用于数据挖掘的形式
1.1 数据平滑
去除数据中的噪声,将连续数据离散化。这里可以采用分箱、聚类和回归的方式进行数据平滑
1,2 数据聚集
对数据进行汇总,在sql中也有一些聚集函数比如Max求最大值
1.3 数据概化
将数据由较低的概念抽象成较高的概念。比如重庆成都概化为中国
1.4 数据规范化
将原来的数值映射到新的特定区域中。比如最大规范化
1.5 属性构造
通过属性与属性的连接构造新的属性,其实就是特征工程。比如数据表中统计每个人的英语、语文和数学成绩,你可以构造一个“总和”这个属性,来作为新属性
2 规范化方法
(1) Min-max规范化
将原始数据变换到[0,1]区间
新数值=(原数值-极小值)/极大值-极小值
(2)Z-Score规范化
比如A同学满分150,B同学满分100,但是两者都得了60分。
数值=(原数值-均值)/ 标准差。
(3)小数制定规范化
通过移动小数点的位置来进行规范化,小数点移动多少位取决于属性A的取值中的最大绝对值。
3 Scikit-Learn使用
(1)官网
(2)Min-max规范化使用
# coding:utf-8
from sklearn import preprocessing
import numpy as np
# 初始化数据,每一行表示一个样本,每一列表示一个特征
x = np.array([[ 0., -4., 1.],
[ 20., 1., 2.],
[ 0., 1., -1.]])
# 将数据进行[0,1]规范化
min_max_scaler = preprocessing.MinMaxScaler()
minmax_x = min_max_scaler.fit_transform(x)
print(minmax_x)
(3)Z_Score使用
from sklearn import preprocessing
import numpy as np
# 初始化数据
x = np.array([[ 0., -4., 1.],
[ 20., 1., 2.],
[ 0., 1., -1.]])
# 将数据进行Z-Score规范化
scaled_x = preprocessing.scale(x)
print(scaled_x)
(4)小数点规范化
# coding:utf-8
from sklearn import preprocessing
import numpy as np
# 初始化数据
x = np.array([[ 0., -4., 1.],
[ 20., 1., 2.],
[ 0., 1., -1.]])
# 标准差标准化
j = np.ceil(np.log10(np.max(abs(x))))
scaled_x = x/(10**j)
print(scaled_x)
4 思维导图
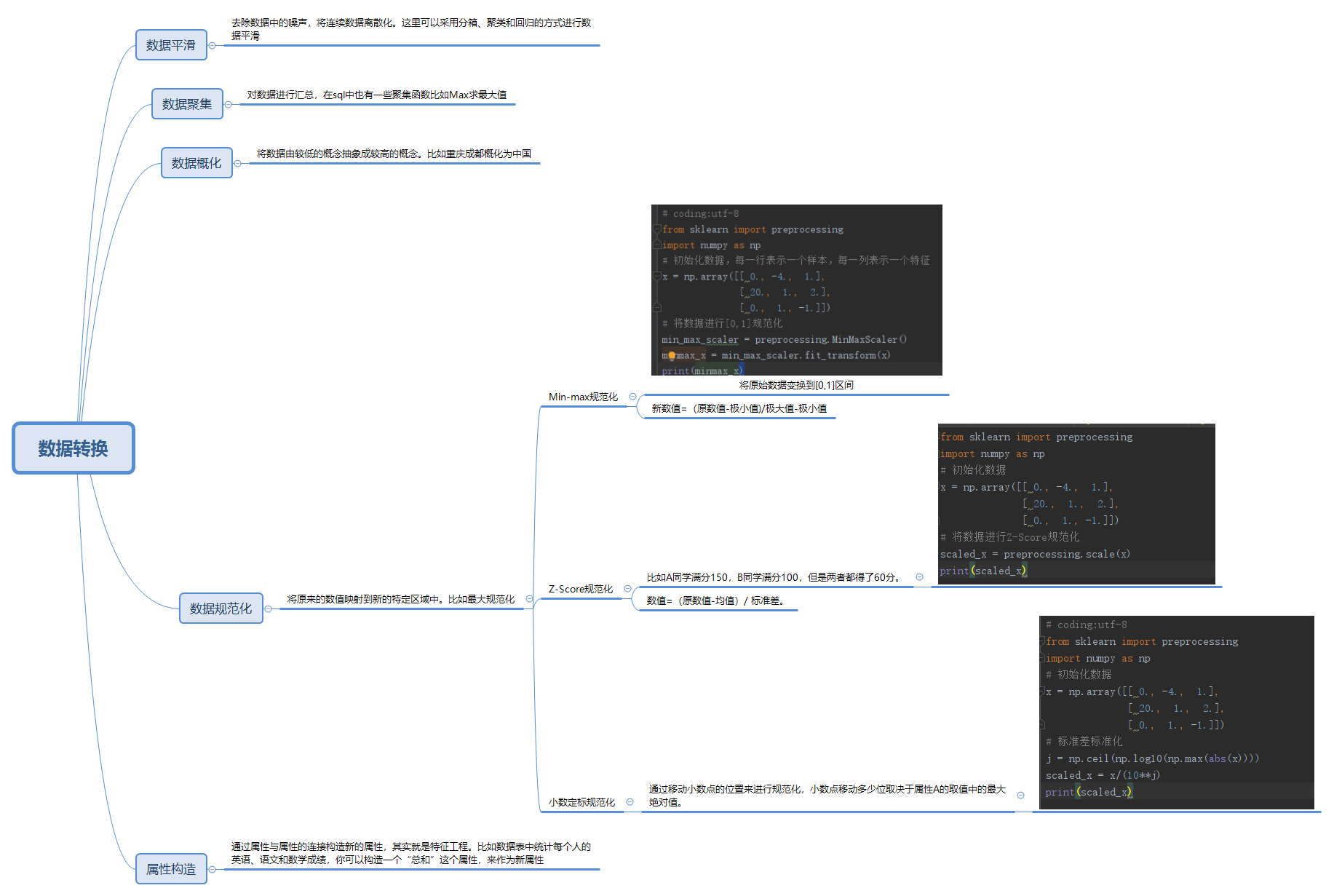
5 总结
为了寻找数据的规律,需要将其规范化。那么目前知道有三种方法,分别为Min-max规范化,Z-Score规范化,小数制定规定化等。
python数据分析5 数据转换的更多相关文章
- (python数据分析)第03章 Python的数据结构、函数和文件
本章讨论Python的内置功能,这些功能本书会用到很多.虽然扩展库,比如pandas和Numpy,使处理大数据集很方便,但它们是和Python的内置数据处理工具一同使用的. 我们会从Python最基础 ...
- 《谁说菜鸟不会数据分析》高清PDF全彩版|百度网盘免费下载|Python数据分析
<谁说菜鸟不会数据分析>高清PDF全彩版|百度网盘免费下载|Python数据分析 提取码:p7uo 内容简介 <谁说菜鸟不会数据分析(全彩)>内容简介:很多人看到数据分析就望而 ...
- [Python数据分析]新股破板买入,赚钱几率如何?
这是本人一直比较好奇的问题,网上没搜到,最近在看python数据分析,正好自己动手做一下试试.作者对于python是零基础,需要从头学起. 在写本文时,作者也没有完成这个小分析目标,边学边做吧. == ...
- 【Python数据分析】Python3多线程并发网络爬虫-以豆瓣图书Top250为例
基于上两篇文章的工作 [Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 [Python数据分析]Python3操作Excel(二) 一些问题的解决与优化 已经正确地实现 ...
- 【Python数据分析】Python3操作Excel(二) 一些问题的解决与优化
继上一篇[Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 对豆瓣图书Top250进行爬取以后,鉴于还有一些问题没有解决,所以进行了进一步的交流讨论,这期间得到了一只尼玛 ...
- 【搬砖】【Python数据分析】Pycharm中plot绘图不能显示出来
最近在看<Python数据分析>这本书,而自己写代码一直用的是Pycharm,在练习的时候就碰到了plot()绘图不能显示出来的问题.网上翻了一下找到知乎上一篇回答,试了一下好像不行,而且 ...
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
Python 数据分析(二) 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识 第1节 groupby 技术 第2节 数据聚合 第3节 分组级运算和转换 第4 ...
- Python数据分析(二): Numpy技巧 (1/4)
In [1]: import numpy numpy.__version__ Out[1]: '1.13.1' In [2]: import numpy as np
- Python数据分析(二): Numpy技巧 (2/4)
numpy.pandas.matplotlib(+seaborn)是python数据分析/机器学习的基本工具. numpy的内容特别丰富,我这里只能介绍一下比较常见的方法和属性. 昨天晚上发了第一 ...
随机推荐
- 基于Custom-metrics-apiserver实现Kubernetes的HPA(内含踩坑)
前言 这里要说一下Prometheus的检控指标从哪里来,它有3个渠道: 主机监控,也就是部署了Node Exporter组件的主机,它以DaemonSet或者系统进程的形式运行,Prometheus ...
- 各主流摄像头的rtsp地址格式
海康威视rtsp://[username]:[password]@[ip]:[port]/[codec]/[channel]/[subtype]/av_stream说明:username: 用户名.例 ...
- Android源码分析(十五)----GPS冷启动实现原理分析
一:原理分析 主要sendExtraCommand方法中传递两个参数, 根据如下源码可以知道第一个参数传递delete_aiding_data,第二个参数传递null即可. @Override pub ...
- Fundebug前端JavaScript插件更新至1.8.0,兼容低版本的Android浏览器
摘要: 兼容低版本Android浏览器,请大家及时更新. Fundebug前端BUG监控服务 Fundebug是专业的程序BUG监控平台,我们JavaScript插件可以提供全方位的BUG监控,可以帮 ...
- MySQL基础SQL命令---增删改查
1.表操作: create table tableName (id int(6) not null primary key auto_increatment,name varchar(10) not ...
- [转]【jsp】
建立时间:6.30 &7.12& 7.24& 7.27 7月心比较浮躁,几乎没怎么学习编程 一.JSP技术 1.jsp脚本和注释 jsp脚本: 1)<%java代码%&g ...
- python 解决粘包问题的例子(ftp文件的上传与下载)简单版本
服务端 ! /user/bin/env python3 -- coding:utf_8 -- """ Author:Markli # 2019/9/9,16:41 &qu ...
- RF元素定位的例子
Execute Javascript $("input[type='button']").click() Comment Click Button css=input.login_ ...
- CMD窗口恢复默认设置
CMD全称Command,是Windows系统下自带的类DOS系统,在日常工作中,有时候设置会损害CMD窗口的默认,导致浏览效果不佳,这时候需要有办法恢复到默认设置.在注册表中删除以下文件夹即可:HK ...
- jQuery对象和DOM对象转换,解决jQuery对象不能使用js方法的问题
有时候想要jQuery对象使用js方法,但是jQuery对象是什么js方法都不能用,怎么办呢?方法其实很简单,只要转换jQuery和DOM对象就可以了. 方法一: var $cr = $(" ...