HADOOP HDFS BALANCER介绍及经验总结(转)
1.集群执行balancer命令,依旧不平衡的原因是什么?该如何解决?
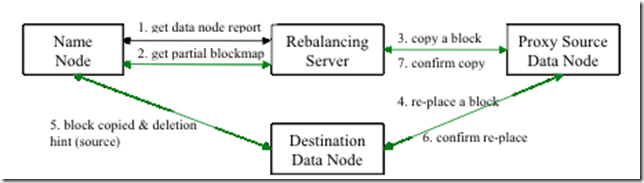
2.尽量不在NameNode上执行start-balancer.sh的原因是什么?
- sh $HADOOP_HOME/bin/start-balancer.sh –t 10%
复制代码
这个命令中-t参数后面跟的是HDFS达到平衡状态的磁盘使用率偏差值。如果机器与机器之间磁盘使用率偏差小于10%,那么我们就认为HDFS集群已经达到了平衡的状态。
HADOOP HDFS BALANCER介绍及经验总结(转)的更多相关文章
- 【转】HADOOP HDFS BALANCER介绍及经验总结
转自:http://www.aboutyun.com/thread-7354-1-1.html 集群平衡介绍 Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,比如集群中添加 ...
- 【转载】漫谈HADOOP HDFS BALANCER
Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,比如集群中添加新的数据节点.当HDFS出现不平衡状况的时候,将引发很多问题,比如MR程序无法很好地利用本地计算的优势,机器之 ...
- 【Hadoop离线基础总结】HDFS入门介绍
HDFS入门介绍 概述 HDFS全称为Hadoop Distribute File System,也就是Hadoop分布式文件系统,是Hadoop的核心组件之一. 分布式文件系统是横跨在多台计算机上的 ...
- Hadoop记录-HDFS balancer配置
HDFS balancer配置(可通过CM配置)dfs.datanode.balance.max.concurrent.moves 并行移动的block数量,默认5 dfs.datanode.bala ...
- 【Hadoop离线基础总结】HDFS详细介绍
HDFS详细介绍 分布式文件系统设计思路 概述 只有一台机器时的文件查找:hello.txt /export/servers/hello.txt 如果有多台机器时的文件查找:hello.txt nod ...
- Hadoop HDFS分布式文件系统 常用命令汇总
引言:我们维护hadoop系统的时候,必不可少需要对HDFS分布式文件系统做操作,例如拷贝一个文件/目录,查看HDFS文件系统目录下的内容,删除HDFS文件系统中的内容(文件/目录),还有HDFS管理 ...
- Hadoop HDFS 用户指南
This document is a starting point for users working with Hadoop Distributed File System (HDFS) eithe ...
- Hadoop HDFS负载均衡
Hadoop HDFS负载均衡 转载请注明出处:http://www.cnblogs.com/BYRans/ Hadoop HDFS Hadoop 分布式文件系统(Hadoop Distributed ...
- sudo -u hdfs hdfs balancer出现异常 No lease on /system/balancer.id
16/06/02 20:34:05 INFO balancer.Balancer: namenodes = [hdfs://dlhtHadoop101:8022, hdfs://dlhtHadoop1 ...
随机推荐
- java读取Oracle的BFile文件
/** * * @author Jasmine */public class GetBlob{ public static void main(String[] args) { Connection ...
- Spring分布式事务
[如何实现XA式.非XA式Spring分布式事务] [http://www.importnew.com/15812.html] 在JavaWorld大会上,来自SpringSource的David S ...
- sql处理数据库锁的存储过程
/*--处理死锁 查看当前进程,或死锁进程,并能自动杀掉死进程 因为是针对死的,所以如果有死锁进程,只能查看死锁进程 当然,你可以通过参数控制,不管有没有死锁,都只查看死锁进程 --邹建 2004.4 ...
- java数组类Arrays:比较,填充,排序
int i1[] = {1,2,3,4,5,6}; int i2[] = {6,5,4,3,2,1}; //排序 Arrays.sort(i2); System.out.println(i1.equa ...
- 【LABVIEW到C#】2》database的操作(一)之 创建access和创建表单
namespace添加如下 using System; using System.Collections.Generic; using System.Linq; using System.Text; ...
- jenkins自动发送邮件配置
一. 前提:确保插件存在 在一切开始之前,必须得确保任务配置里有两个插件:E-mail Notification(邮件通知) 和 Editable Email Notification(可编辑的邮件通 ...
- AI探索(一)基础知识储备
AI的定义 凡是通过机器学习,实现机器替代人力的技术,就是AI.机器学习是什么呢?机器学习是由AI科学家研发的算法模型,通过数据灌输,学习数据中的规律并总结,即模型内自动生成能表达(输入.输出)数据之 ...
- boost开发指南
C++确实很复杂,神一样的0x不知道能否使C++变得纯粹和干爽? boost很复杂,感觉某些地方有过度设计和太过于就事论事的嫌疑,对实际开发工作的考虑太过于理想化.学习boost本身就是一个复杂度,有 ...
- DP 问题
什么时候使用DP: 最优化原理:如果问题的最优解所包含的子问题的解也是最优的,就称该问题具有最优子结构,即满足最优化原理.(这句话可理解为先将复杂的问题简单化, 达到最简后的解题公式同样可以解复杂情况 ...
- 使用sort&awk实现文件内容块排序
源文件为: [root@luo5 wangxx]# cat -v luo.txt J LuoSoutth jfsaNanjing,china Y ZhangVictory UniversityNejf ...