python大战机器学习——半监督学习
半监督学习:综合利用有类标的数据和没有类标的数据,来生成合适的分类函数。它是一类可以自动地利用未标记的数据来提升学习性能的算法
1、生成式半监督学习
优点:方法简单,容易实现。通常在有标记数据极少时,生成式半监督学习方法比其他方法性能更好
缺点:假设的生成式模型必须与真实数据分布吻合。如果不吻合则可能效果很差。而如何给出与真实数据分布吻合的生成式模型,这就需要对问题领域的充分了解
2、图半监督学习
(1)标记传播算法:
优点:概念清晰
缺点:存储开销大,难以直接处理大规模数据;而且对于新的样本加入,需要对原图重构并进行标记传播
(2)迭代式标记传播算法:
输入:有标记样本集Dl,未标记样本集Du,构图参数δ,折中参数α
输出:未标记样本的预测结果y
步骤:
1)计算W
2)基于W构造标记传播矩阵S
3)根据公式初始化F<0>
4)t=0
5)迭代,迭代终止条件是F收敛至F*:
F<t+1>=αSF<t>+(1-α)Y
t=t+1
6)构造未标记样本的预测结果yi
7)输出结果y
LabelPropagation实验代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import metrics
from sklearn import datasets
from sklearn.semi_supervised import LabelPropagation def load_data():
digits=datasets.load_digits()
rng=np.random.RandomState(0)
index=np.arange(len(digits.data))
rng.shuffle(index)
X=digits.data[index]
Y=digits.target[index]
n_labeled_points=int(len(Y)/10)
unlabeled_index=np.arange(len(Y))[n_labeled_points:] return X,Y,unlabeled_index def test_LabelPropagation(*data):
X,Y,unlabeled_index=data
Y_train=np.copy(Y)
Y_train[unlabeled_index]=-1
cls=LabelPropagation(max_iter=100,kernel='rbf',gamma=0.1)
cls.fit(X,Y_train)
print("Accuracy:%f"%cls.score(X[unlabeled_index],Y[unlabeled_index])) X,Y,unlabeled_index=load_data()
test_LabelPropagation(X,Y,unlabeled_index)
实验结果:
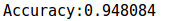 可见预测的准确率还是挺高的
可见预测的准确率还是挺高的
LabelSpreading实验代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import metrics
from sklearn import datasets
from sklearn.semi_supervised import LabelPropagation,LabelSpreading def load_data():
digits=datasets.load_digits()
rng=np.random.RandomState(0)
index=np.arange(len(digits.data))
rng.shuffle(index)
X=digits.data[index]
Y=digits.target[index]
n_labeled_points=int(len(Y)/10)
unlabeled_index=np.arange(len(Y))[n_labeled_points:] return X,Y,unlabeled_index def test_LabelPropagation(*data):
X,Y,unlabeled_index=data
Y_train=np.copy(Y)
Y_train[unlabeled_index]=-1
cls=LabelPropagation(max_iter=100,kernel='rbf',gamma=0.1)
cls.fit(X,Y_train)
print("Accuracy:%f"%cls.score(X[unlabeled_index],Y[unlabeled_index])) def test_LabelSpreading(*data):
X,Y,unlabeled_index=data
Y_train=np.copy(Y)
Y_train[unlabeled_index]=-1
cls=LabelSpreading(max_iter=100,kernel='rbf',gamma=0.1)
cls.fit(X,Y_train)
predicted_labels=cls.transduction_[unlabeled_index]
true_labels=Y[unlabeled_index]
print("Accuracy:%f"%metrics.accuracy_score(true_labels,predicted_labels)) X,Y,unlabeled_index=load_data()
#test_LabelPropagation(X,Y,unlabeled_index)
test_LabelSpreading(X,Y,unlabeled_index)
注:LabelSpreading类似于LabelPropagation,但是使用基于normalized graph Laplacian and soft clamping的距离矩阵
实验结果:
 预测效果也很不错
预测效果也很不错
3、总结
半监督学习在利用未标记样本后并非必然提升泛化性能,在有些情况下甚至会导致性能下降。对生成式方法,原因通常是模型假设不准确。因此需要依赖充分可靠的领域知识来设计模型。更一般的安全半监督学习仍然是未加解决的难题。安全是指:利用未标记样本后,能确保返回性能至少不差于仅利用有标记样本
python大战机器学习——半监督学习的更多相关文章
- 吴裕雄 python 机器学习——半监督学习LabelSpreading模型
import numpy as np import matplotlib.pyplot as plt from sklearn import metrics from sklearn import d ...
- 吴裕雄 python 机器学习——半监督学习标准迭代式标记传播算法LabelPropagation模型
import numpy as np import matplotlib.pyplot as plt from sklearn import metrics from sklearn import d ...
- python大战机器学习——模型评估、选择与验证
1.损失函数和风险函数 (1)损失函数:常见的有 0-1损失函数 绝对损失函数 平方损失函数 对数损失函数 (2)风险函数:损失函数的期望 经验风险:模型在数据集T上的平均损失 根据大 ...
- python大战机器学习——数据预处理
数据预处理的常用流程: 1)去除唯一属性 2)处理缺失值 3)属性编码 4)数据标准化.正则化 5)特征选择 6)主成分分析 1.去除唯一属性 如id属性,是唯一属性,直接去除就好 2.处理缺失值 ( ...
- python大战机器学习——集成学习
集成学习是通过构建并结合多个学习器来完成学习任务.其工作流程为: 1)先产生一组“个体学习器”.在分类问题中,个体学习器也称为基类分类器 2)再使用某种策略将它们结合起来. 通常使用一种或者多种已有的 ...
- python大战机器学习——人工神经网络
人工神经网络是有一系列简单的单元相互紧密联系构成的,每个单元有一定数量的实数输入和唯一的实数输出.神经网络的一个重要的用途就是接受和处理传感器产生的复杂的输入并进行自适应性的学习,是一种模式匹配算法, ...
- python大战机器学习——支持向量机
支持向量机(Support Vector Machine,SVM)的基本模型是定义在特征空间上间隔最大的线性分类器.它是一种二类分类模型,当采用了核技巧之后,支持向量机可以用于非线性分类. 1)线性可 ...
- python大战机器学习——聚类和EM算法
注:本文中涉及到的公式一律省略(公式不好敲出来),若想了解公式的具体实现,请参考原著. 1.基本概念 (1)聚类的思想: 将数据集划分为若干个不想交的子集(称为一个簇cluster),每个簇潜在地对应 ...
- python大战机器学习——数据降维
注:因为公式敲起来太麻烦,因此本文中的公式没有呈现出来,想要知道具体的计算公式,请参考原书中内容 降维就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中 1.主成分分析(PCA) 将n ...
随机推荐
- 多版本Python共存时pip给指定版本的python安装package的方法
在Linux安装了多版本Python时(例如python2.7和3.6),pip安装的包不一定是用户想要的位置,此时可以用 -t 选项来指定位置. 例如目标位置是/usr/local/lib/pyth ...
- 洛谷【P1104】生日(插入排序版)
题目传送门:https://www.luogu.org/problemnew/show/P1104 题目很简单,我主要是来讲插入排序的. 所谓插入排序,就是从待排序数组不断将数据插入答案数组里. 假设 ...
- 杂项-JS:artTemplate.js
ylbtech-杂项-JS:artTemplate.js artTemplate 是新一代 javascript 模板引擎,它采用预编译方式让性能有了质的飞跃,并且充分利用 javascript 引擎 ...
- linux获取文件大小的函数
C语言fstat()函数:由文件描述词取得文件状态 头文件:#include <sys/stat.h> #include <unistd.h> 定义函数:int fstat ...
- Python-IO模式介绍
事件驱动模型:有个事件队列,把事件放到队列里,然后循环这个队列,取出事件执行 5种IO模式: 阻塞 I/O(blocking IO) 非阻塞 I/O(nonblocking IO) I/O 多路复用( ...
- 【原】spring jar 下载
作者:david_zhang@sh [转载时请以超链接形式标明文章] 链接:http://www.cnblogs.com/david-zhang-index/p/8098965.html 1.进入官网 ...
- Hander----使用
public class MainActivity extends Activity { private EditText UITxt; private Button updateUIBtn; pri ...
- mysql nginx redis 配置文件
https://github.com/superhj1987/awesome-config
- 【总结整理】关于Json的解析,校验和验证
var jasondata='{"staff": [{"name":"红旗","age":90}, {"nam ...
- 任务调度TimerTask&Quartz的 Java 实现方法与比较
文章引自--https://www.ibm.com/developerworks/cn/java/j-lo-taskschedule/ 前言 任务调度是指基于给定时间点,给定时间间隔或者给定执行次数自 ...