F1 score,micro F1score,macro F1score 的定义
F1 score,micro F1score,macro F1score 的定义
本篇博客可能会继续更新
最近在文献中经常看到precesion,recall,常常忘记了他们的定义,在加上今天又看到评价多标签分类任务性能的度量方法micro F1score和macro F2score。决定再把F1 score一并加进来把定义写清楚,忘记了再来看看。
F1score
F1score(以下简称F1)是用来评价二元分类器的度量,它的计算方法如下: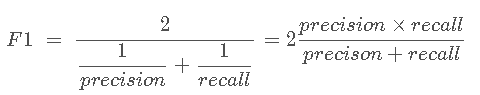
F1是用来衡量二维分类的,那形容多元分类器的性能用什么呢?micro F1score,和macro F2score则是用来衡量多元分类器的性能。
假设对于一个多分类问题,有三个类,分别记为1、2、3,
TPi是指分类i的True Positive;
FPi是指分类i的False Positive;
TNi是指分类i的True Negative;
FNi是指分类i的False Negative。
我们分别计算每个类的精度(precision)
macro 精度 就是所有分类的精度平均值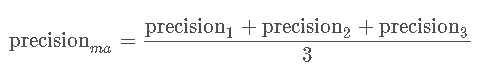
同样,每个类的recall计算为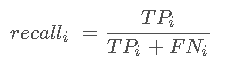
macro 召回就是所有分类的召回平均值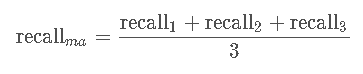
套用F1score的计算方法,macro F1score就是
micro F1score
假设对于一个多分类问题,有三个类,分别记为1、2、3,
TPi是指分类i的True Positive;
FPi是指分类i的False Positive;
TNi是指分类i的True Negative;
FNi是指分类i的False Negative。
接下来,我们来算micro precision
相应的micro recall则是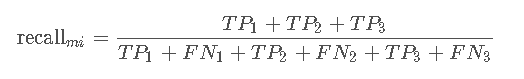
则micro F1score为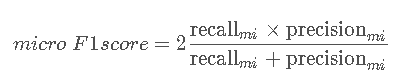
总结
如果各个类的分布不均衡的话,使用micro F1score比macro F1score 比较好,显然macro F1score没有考虑各个类的数量大小
F1 score,micro F1score,macro F1score 的定义的更多相关文章
- hihocoder 1522 : F1 Score
题目链接 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 小Hi和他的小伙伴们一起写了很多代码.时间一久有些代码究竟是不是自己写的,小Hi也分辨不出来了. 于是他实现 ...
- 机器学习--Micro Average,Macro Average, Weighted Average
根据前面几篇文章我们可以知道,当我们为模型泛化性能选择评估指标时,要根据问题本身以及数据集等因素来做选择.本篇博客主要是解释Micro Average,Macro Average,Weighted A ...
- 机器学习中的 precision、recall、accuracy、F1 Score
1. 四个概念定义:TP.FP.TN.FN 先看四个概念定义: - TP,True Positive - FP,False Positive - TN,True Negative - FN,False ...
- 【tf.keras】实现 F1 score、precision、recall 等 metric
tf.keras.metric 里面竟然没有实现 F1 score.recall.precision 等指标,一开始觉得真不可思议.但这是有原因的,这些指标在 batch-wise 上计算都没有意义, ...
- How to compute f1 score for each epoch in Keras
https://medium.com/@thongonary/how-to-compute-f1-score-for-each-epoch-in-keras-a1acd17715a2 https:// ...
- 机器学习:评价分类结果(F1 Score)
一.基础 疑问1:具体使用算法时,怎么通过精准率和召回率判断算法优劣? 根据具体使用场景而定: 例1:股票预测,未来该股票是升还是降?业务要求更精准的找到能够上升的股票:此情况下,模型精准率越高越优. ...
- 机器学习--如何理解Accuracy, Precision, Recall, F1 score
当我们在谈论一个模型好坏的时候,我们常常会听到准确率(Accuracy)这个词,我们也会听到"如何才能使模型的Accurcy更高".那么是不是准确率最高的模型就一定是最好的模型? 这篇博文会向大家解释 ...
- 【笔记】F1 score
F1 score 关于精准率和召回率 精准率和召回率可以很好的评价对于数据极度偏斜的二分类问题的算法,有个问题,毕竟是两个指标,有的时候这两个指标也会产生差异,对于不同的算法,精准率可能高一些,召回率 ...
- Micro和Macro性能学习【转载】
转自:https://datascience.stackexchange.com/questions/15989/micro-average-vs-macro-average-performance- ...
随机推荐
- poj 2553 The Bottom of a Graph(强连通、缩点、出入度)
题意:给出一个有向图G,寻找所有的sink点.“sink”的定义为:{v∈V|∀w∈V:(v→w)⇒(w→v)},对于一个点v,所有能到达的所有节点w,都能够回到v,这样的点v称为sink. 分析:由 ...
- Redis的订阅发布
using System; using System.Collections.Generic; using System.Linq; using System.Text; using ServiceS ...
- Error in as.POSIXlt.character(x, tz, ...) :
> sqlFetch(channel,"user")Error in as.POSIXlt.character(x, tz, ...) : character strin ...
- 关于inittab的几个命令
1. 查看default runlevel(默认运行等级)的方法: $cat /etc/inittab | grep id id:3:initdefault: # <id>:<run ...
- ARM初学引导_转
一直都在听说ARM有多么好,有多神奇,有多难学.故学它时都兴奋加恐惧.呵呵,我刚好用ARM也有一段时间了.写点东西给ARM的初学者,希望能起到帮助作用. 1,记住:ARM很简单,就如从51转换到PIC ...
- Android View中getViewTreeObserver().addOnGlobalLayoutListener() (转)
转自:Android View中getViewTreeObserver().addOnGlobalLayoutListener() 我们知道在oncreate中View.getWidth和View.g ...
- UFLDL深度学习笔记 (五)自编码线性解码器
UFLDL深度学习笔记 (五)自编码线性解码器 1. 基本问题 在第一篇 UFLDL深度学习笔记 (一)基本知识与稀疏自编码中讨论了激活函数为\(sigmoid\)函数的系数自编码网络,本文要讨论&q ...
- SPSS统计功能与模块对照表
SPSS统计功能 - 应用速查表第一列为统计方法,中间为统计功能,最后一列为所在模块 1 ANOVA Models(单因素方差分析:简单因子) : 摘要 描述 方差 轮廓 - SPSS Base 2 ...
- Android拍照生成缩略图
在Android 2.2版本中,新增了一个ThumbnailUtils工具类来是实现缩略图,此工具类的功能是强大的,使用是简单,它提供了一个常量和三个方法.利用这些常数和方法,可以轻松快捷的实现图片和 ...
- tomcat下发布项目,遇到的问题总结
以前一直是在eclipse下启动tomcat,然后访问web项目.今天脑门一热,就想用tomcat的bin目录下的startup.bat来启动tomcat,虽然tomcat的启动很顺利,但是访问网页的 ...