《转载》python爬虫实践之模拟登录
浏览器访问服务器的过程

Http消息
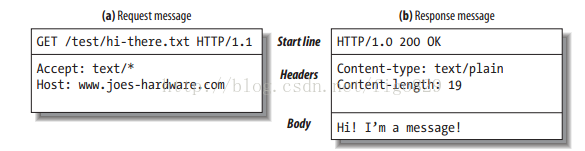
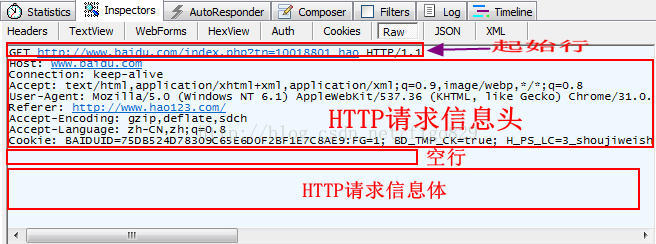
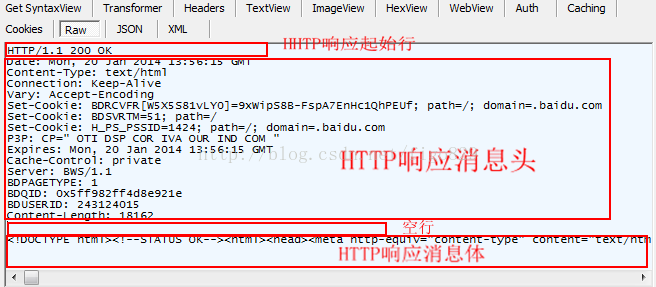

什么是Cookie?
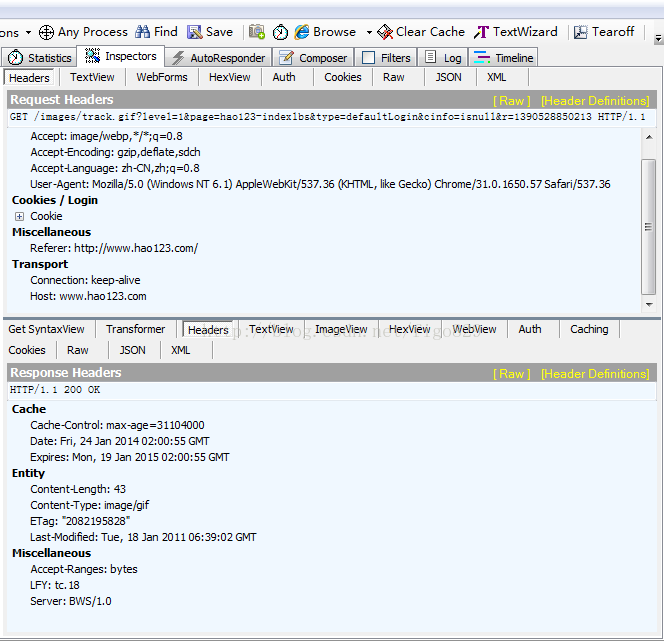
为什么需要Cookie
Cookie的种类
Cookie的构成
python模拟登录
- #! /usr/bin/env python
- #coding:utf-8
- import sys
- import re
- import urllib2
- import urllib
- import requests
- import cookielib
- ## 这段代码是用于解决中文报错的问题
- reload(sys)
- sys.setdefaultencoding("utf8")
- #####################################################
- #登录人人
- loginurl = 'http://www.renren.com/PLogin.do'
- logindomain = 'renren.com'
- class Login(object):
- def __init__(self):
- self.name = ''
- self.passwprd = ''
- self.domain = ''
- self.cj = cookielib.LWPCookieJar()
- self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cj))
- urllib2.install_opener(self.opener)
- def setLoginInfo(self,username,password,domain):
- '''''设置用户登录信息'''
- self.name = username
- self.pwd = password
- self.domain = domain
- def login(self):
- '''''登录网站'''
- loginparams = {'domain':self.domain,'email':self.name, 'password':self.pwd}
- headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.57 Safari/537.36'}
- req = urllib2.Request(loginurl, urllib.urlencode(loginparams),headers=headers)
- response = urllib2.urlopen(req)
- self.operate = self.opener.open(req)
- thePage = response.read()
- if __name__ == '__main__':
- userlogin = Login()
- username = 'username'
- password = 'password'
- domain = logindomain
- userlogin.setLoginInfo(username,password,domain)
- userlogin.login()
《转载》python爬虫实践之模拟登录的更多相关文章
- Python 爬虫实战5 模拟登录淘宝并获取所有订单
经过多次尝试,模拟登录淘宝终于成功了,实在是不容易,淘宝的登录加密和验证太复杂了,煞费苦心,在此写出来和大家一起分享,希望大家支持. 本篇内容 python模拟登录淘宝网页 获取登录用户的所有订单详情 ...
- python爬虫之scrapy模拟登录
背景: 初来乍到的pythoner,刚开始的时候觉得所有的网站无非就是分析HTML.json数据,但是忽略了很多的一个问题,有很多的网站为了反爬虫,除了需要高可用代理IP地址池外,还需要登录.例如知乎 ...
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- Python网络爬虫实战(四)模拟登录
对于一个网站的首页来说,它可能需要你进行登录,比如知乎,同一个URL下,你登录与未登录当然在右上角个人信息那里是不一样的. (登录过) (未登录) 那么你在用爬虫爬取的时候获得的页面究竟是哪个呢? 肯 ...
- [Python爬虫] Selenium实现自动登录163邮箱和Locating Elements介绍
前三篇文章介绍了安装过程和通过Selenium实现访问Firefox浏览器并自动搜索"Eastmount"关键字及截图的功能.而这篇文章主要简单介绍如何实现自动登录163邮箱,同时 ...
- python爬虫实践(二)——爬取张艺谋导演的电影《影》的豆瓣影评并进行简单分析
学了爬虫之后,都只是爬取一些简单的小页面,觉得没意思,所以我现在准备爬取一下豆瓣上张艺谋导演的“影”的短评,存入数据库,并进行简单的分析和数据可视化,因为用到的只是比较多,所以写一篇博客当做笔记. 第 ...
- python之cookie, cookiejar 模拟登录绕过验证
0.思路 如果懒得模拟登录,或者模拟登录过于复杂(多步交互或复杂验证码)则人工登录后手动复制cookie(或者代码读取浏览器cookie),缺点是容易过期. 如果登录是简单的提交表单,代码第一步模拟登 ...
- python之简单POST模拟登录
宿舍自从换了校园网的认证系统就不再用客户端了,只能在网页登录.每次上网都要打开浏览器的话很不方便,而且我有时在ubuntu控制台上想联网但终端文本浏览器似乎不支持页面跳转,既然如此,何不写个客户端呢? ...
- Python手动构造Cookie模拟登录后获取网站页面内容
最近有个好友让我帮忙爬取个小说,这个小说是前三十章直接可读,后面章节需要充值VIP可见.所以就需要利用VIP账户登录后,构造Cookie,再用Python的获取每章节的url,得到内容后再使用 PyQ ...
随机推荐
- nginx限制ip访问(转)
一.服务器全局限IP #vi nginx.conf allow 10.57.22.172; #允许的IP deny all; 二.站点限IP #vi vhosts.conf 站点全局限IP ...
- 总结·展望
学了算法也有半年了.也是学期末,确实是该总结了.半年来说不上多努力,毕竟不如高中那时候早晨5点起晚上12点睡,但也确实学到不少东西(尽管眼下来说根本用不到并且我也不确定以为会不会去用.毕竟专业放在那里 ...
- PKCS 15 个标准
PKCS 全称是 Public-Key Cryptography Standards ,是由 RSA 实验室与其它安全系统开发商为促进公钥密码的发展而制订的一系列标准. 可以到官网上看看 What i ...
- 当echarts的legend字数过多的时候变成省略号
legend: { data: ['国有土地使用','食品药品安全','生态环境和资源保护','国有财产保护'], orient: 'horizontal', left: '10', bottom:' ...
- Linux性能分析流程图
- Spring4学习笔记一:环境搭建与插件安装、基本概念理解
一:环境搭建 1:开发环境:JDK安装.Eclipse安装 2:数据库:Mysql.Sequel Pro(数据库可视化操作工具) 3:web服务器:Tomcat下载,并且把tomcat配置到Eclip ...
- 通过jarjar.jar来替换jar包名的详细介绍
有时候我们根据一些场景 需要替换第三方jar包的包名,比如Android广告平台sdk,更换他们jar包包名的话,可以防止市场检测到有广告插件,所以,今天就介绍一下如何使用jarjar.jar工具来替 ...
- Ext4 ReiserFS Btrfs 等7种文件系统性能比拼
2009年02月04日 为了满足广大群众的热切需求,今天做了 Ext2.Ext3.Ext4.XFS.JFS.ReiserFS 和 Btrfs 的全面性能测试,对比结果如下: 本次测试所 ...
- linux下open和fopen的区别
二者返回值不同. fopen可以指定宽字符和ASCI.
- Swift Assert 断言
前言 对每次运行都会出现的错误通常不会过于苦恼,可以使用断点调试或者 try catch 之类的方式判断并修复它.但是一些偶发(甚至是无数次运行才会出现一次)的错误单靠断点之类的方式是很难排除掉的,为 ...