全卷积神经网络FCN
卷积神经网络CNN(YannLecun,1998年)通过构建多层的卷积层自动提取图像上的特征,一般来说,排在前边较浅的卷积层采用较小的感知域,可以学习到图像的一些局部的特征(如纹理特征),排在后边较深的卷积层采用较大的感知域,可以学习到更加抽象的特征(如物体大小,位置和方向信息等)。CNN在图像分类和图像检测领域取得了广泛应用。
CNN提取的抽象特征对图像分类、图像中包含哪些类别的物体,以及图像中物体粗略位置的定位很有效,但是由于采用了感知域,对图像特征的提取更多的是以“一小块临域”为单位的,因此很难做到精细(像素级)的分割,不能很准确的划定物体具体的轮廓。
针对CNN在图像精细分割上存在的局限性,UC Berkeley的Jonathan Long等人2015年在其论文 “Fully convolutional networks for semantic segmentation”(用于语义分割的全卷积神经网络)中提出了Fully Convolutional Networks (FCN)用于图像的分割,要解决的核心问题就是图像像素级别的分类。论文链接: https://arxiv.org/abs/1411.4038
FCN与CNN的核心区别就是FCN将CNN末尾的全连接层转化成了卷积层:
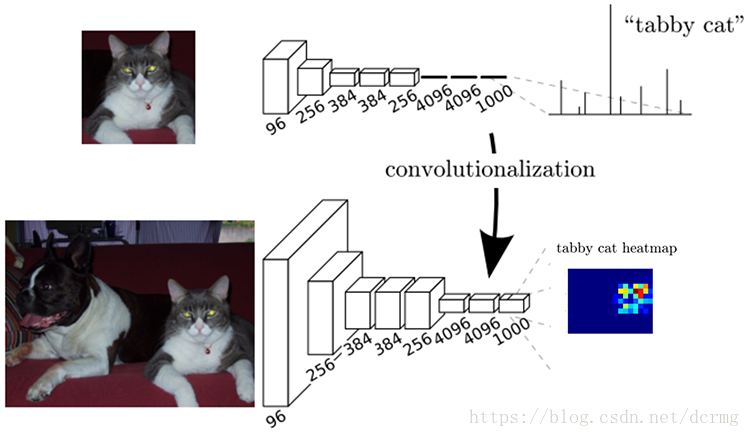
以Alexnet为例,输入是227*227*3的图像,前5层是卷积层,第5层的输出是256个特征图,大小是6*6,即256*6*6,第6、7、8层分别是长度是4096、4096、1000的一维向量。
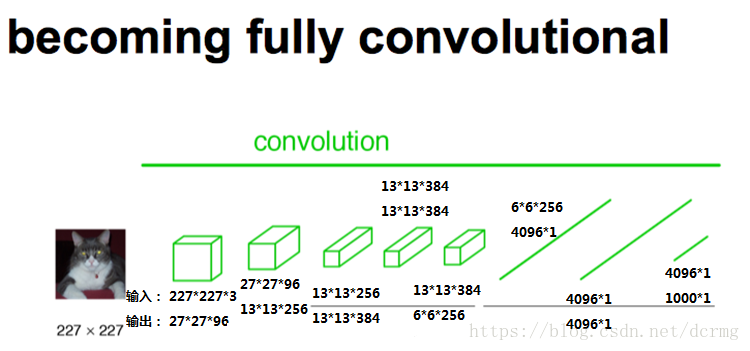
在FCN中第6、7、8层都是通过卷积得到的,卷积核的大小全部是1*1,第6层的输出是4096*7*7,第7层的输出是4096*7*7,第8层的输出是1000*7*7(7是输入图像大小的1/32),即1000个大小是7*7的特征图(称为heatmap)。
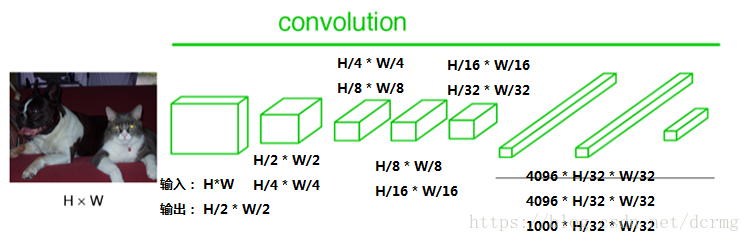
经过多次卷积后,图像的分辨率越来越低,,为了从低分辨率的heatmap恢复到原图大小,以便对原图上每一个像素点进行分类预测,需要对heatmap进行反卷积,也就是上采样。论文中首先进行了一个上池化操作,再进行反卷积,使得图像分辨率提高到原图大小:
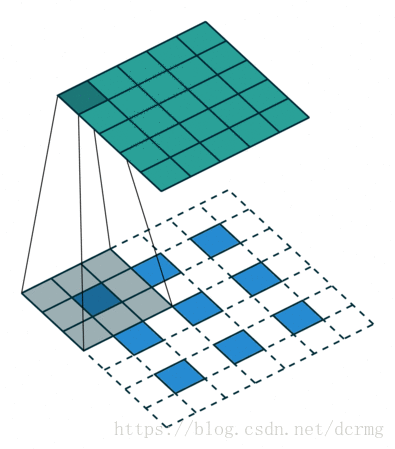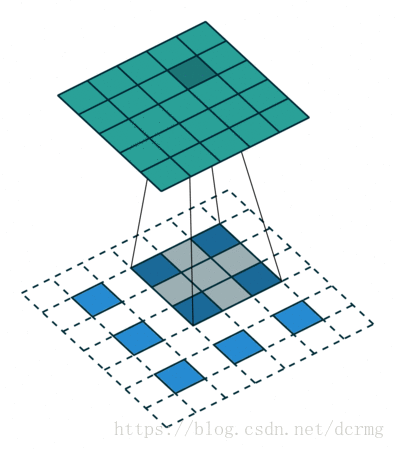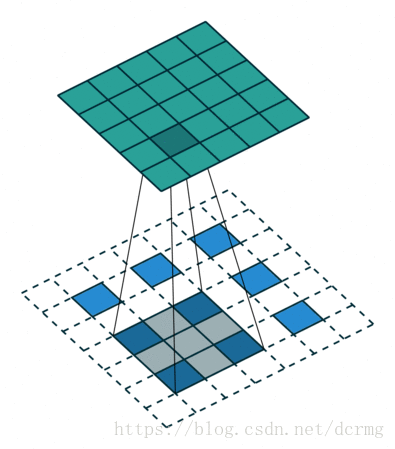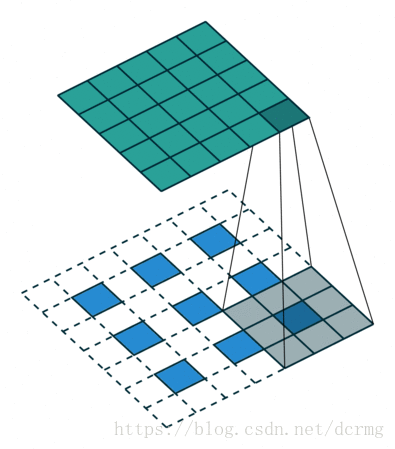
对第5层的输出执行32倍的反卷积得到原图,得到的结果不是很精确,论文中同时执行了第4层和第3层输出的反卷积操作(分别需要16倍和8倍的上采样),再把这3个反卷积的结果图像融合,提升了结果的精确度:
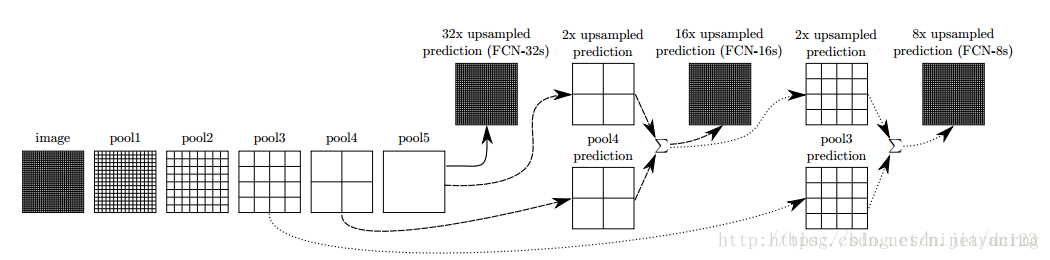
最后像素的分类按照该点在1000张上采样得到的图上的最大的概率来定。
FCN可以接受任意大小的输入图像,但是FCN的分类结果还是不够精细,对细节不太敏感,再者没有考虑到像素与像素之间的关联关系,丢失了部分空间信息。
全卷积神经网络FCN的更多相关文章
- 全卷积神经网络FCN详解(附带Tensorflow详解代码实现)
一.导论 在图像语义分割领域,困扰了计算机科学家很多年的一个问题则是我们如何才能将我们感兴趣的对象和不感兴趣的对象分别分割开来呢?比如我们有一只小猫的图片,怎样才能够通过计算机自己对图像进行识别达到将 ...
- 全卷积神经网络FCN理解
论文地址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn.pdf 这篇论文使用全卷积神经网络来做语义上的图像分割,开创了这一领 ...
- 全卷积网络 FCN 详解
背景 CNN能够对图片进行分类,可是怎么样才能识别图片中特定部分的物体,在2015年之前还是一个世界难题.神经网络大神Jonathan Long发表了<Fully Convolutional N ...
- 全卷积网络FCN详解
http://www.cnblogs.com/gujianhan/p/6030639.html CNN能够对图片进行分类,可是怎么样才能识别图片中特定部分的物体? (图像语义分割) FCN(Fully ...
- 语义分割--全卷积网络FCN详解
语义分割--全卷积网络FCN详解 1.FCN概述 CNN做图像分类甚至做目标检测的效果已经被证明并广泛应用,图像语义分割本质上也可以认为是稠密的目标识别(需要预测每个像素点的类别). 传统的基于C ...
- 全卷积网络FCN
全卷积网络FCN fcn是深度学习用于图像分割的鼻祖.后续的很多网络结构都是在此基础上演进而来. 图像分割即像素级别的分类. 语义分割的基本框架: 前端fcn(以及在此基础上的segnet,decon ...
- 全卷积网络(FCN)与图像分割
最近在做物体检测,也用到了全卷积网络,来此学习一波. 这篇文章写了很好,有利于入门,在此记录一下: http://blog.csdn.net/taigw/article/details/5140144 ...
- 【pytorch】改造resnet为全卷积神经网络以适应不同大小的输入
为什么resnet的输入是一定的? 因为resnet最后有一个全连接层.正是因为这个全连接层导致了输入的图像的大小必须是固定的. 输入为固定的大小有什么局限性? 原始的resnet在imagenet数 ...
- 基于区域的全卷积神经网络(R-FCN)简介
在 Faster R-CNN 中,检测器使用了多个全连接层进行预测.如果有 2000 个 ROI,那么成本非常高. feature_maps = process(image)ROIs = region ...
随机推荐
- Maven管理jar包依赖常出现的不能实例化类的问题
you'ji 在maven管理jar包依赖时,存在一种常见的问题. pom.xml文件配置没问题,通过eclipse里中的maven dependencies查看,也确实有这个jar 包,或者这个类. ...
- maven聚合工程tomcat插件启动没有 Starting ProtocolHandler ["http-bio-8081"]
Starting ProtocolHandler ["http-bio-8081"]无法显示,一般有三个原因: (1)数据库连不上: (2)注册中心连不上(我这里用的是zookee ...
- Nginx反向代理配置教程(php-fpm)
1.安装nginx http://www.cnblogs.com/lsdb/p/6543441.html 2.安装php-fpm yum install -y php-fpm 3.配置Nginx反向代 ...
- linux常用文本编缉命令(strings/sed/awk/cut)
一.strings strings--读出文件中的所有字符串 二.sed--文本编缉 类型 命令 命令说明 字符串替换 sed -i 's/str_reg/str_rep/' filename 将文件 ...
- Java 8 默认方法(Default Methods)
Java 8 默认方法(Default Methods) Posted by Ebn Zhang on December 20, 2015 Java 8 引入了新的语言特性——默认方法(Default ...
- python删除指定路径的文件
import os import glob path =imgDate_listResult for infi ...
- Spring之缓存注解@Cacheable
https://www.cnblogs.com/fashflying/p/6908028.html https://blog.csdn.net/syani/article/details/522399 ...
- 使用Java实现面向对象编程
使用Java实现面向对象编程 源码展示: package cdjj.s2t075.com; import java.util.Scanner; public class Door { /* * Doo ...
- Win10怎么设置打开文件的默认程序
- 分布式锁与实现(一)基于Redis实现
目前几乎很多大型网站及应用都是分布式部署的,分布式场景中的数据一致性问题一直是一个比较重要的话题.分布式的CAP理论告诉我们“任何一个分布式系统都无法同时满足一致性(Consistency).可用性( ...