Python爬虫【五】Scrapy分布式原理笔记
Scrapy单机架构
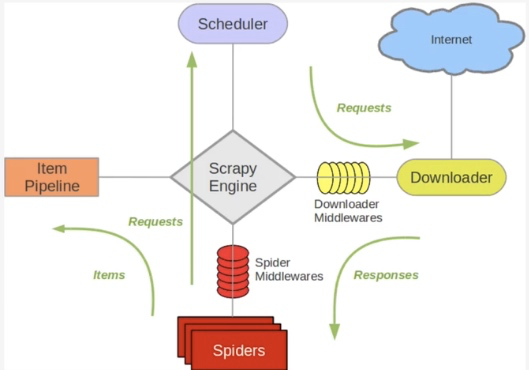
在这里scrapy的核心是scrapy引擎,它通过里面的一个调度器来调度一个request的队列,将request发给downloader,然后来执行request请求
但是这些request队列都是维持在本机上的,因此如果要多台主机协同爬取,需要一个request共享的机制——requests队列,在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列。
单主机爬虫架构
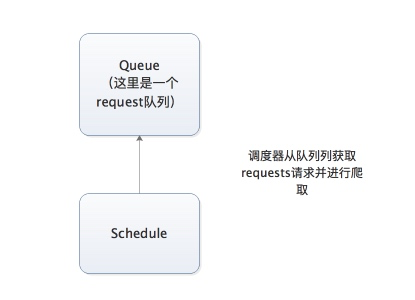
调度器负责从队列中调度requests进行爬取,而每台主机分别维护requests队列
分布式爬虫架构
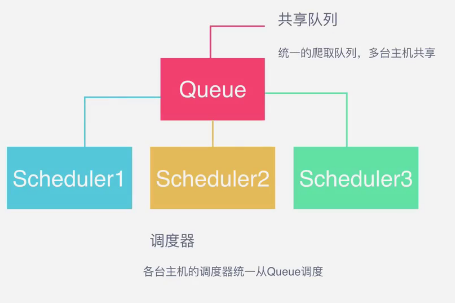
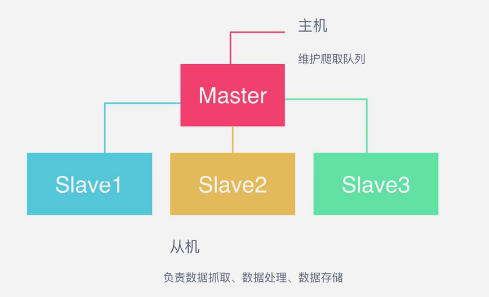
队列用什么维护?
这里一般我们通过Redis为维护,Redis,非关系型数据库,Key-Value形式存储,结构灵活。
是内存中的数据结构存储系统,处理速度快,性能好。提供队列、集合等多种存储结构,方便队列维护。
如何去重?——Redis集合
redis提供集合数据结构,在redis集合中存储每个request的指纹。
在向request队列中加入Request前先验证这个Request的指纹是否已经加入集合中。
如果已经存在则不添加到request队列中,如果不存在,则将request加入到队列并将指纹加入集合。
如何防止中断?——启动判断
在每台slave的Scrapy启动的时候都会判断当前redis request队列是否为空
如果不为空,则从队列中获取下一个request执行爬取。如果为空则重新开始爬取,第一台丛集执行爬取向队列中添加request。
如何实现分布式架构?——scrapy-redis库
scrapy-redis改写了Scrapy的调度器,队列等组件,利用它可以方便的实现Scrapy分布式架构
关于scrapy-redis的地址:https://github.com/rolando/scrapy-redis
1.新建分支distributed
2.在settings里,将SCHEDULER改为scrapy的调度器,SCHEDULER = "scrapy_redis.scheduler.Scheduler",即将scrapy中的核心调度器替换
3.添加去重的class
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
4.引入pipeline,并更改优先级
'scrapy_redis.pipelines.RedisPipeline': 301
5.共享的爬取队列,指定Redis数据库的连接信息,直接把Redis的url拿过来
这里的user:pass表示用户名和密码,如果没有则为空就可以
REDIS_URL = 'redis://user:pass@hostname:9001'
6.设置为为True则不会清空redis里的dupefilter和requests队列
这样设置后指纹和请求队列则会一直保存在redis数据库中,默认为False,一般不进行设置 SCHEDULER_PERSIST = True
7.设置重启爬虫时是否清空爬取队列
这样每次重启爬虫都会清空指纹和请求队列,一般设置为False
SCHEDULER_FLUSH_ON_START=True
8.分布式
将上述更改后的代码拷贝的各个服务器,当然关于数据库这里可以在每个服务器上都安装数据,也可以共用一个数据,所有的服务器都要安装scrapy,scrapy_redis,pymongo
这样运行各个爬虫程序启动后,在redis数据库就可以看到如下内容,dupefilter是指纹队列,requests是请求队列
Python爬虫【五】Scrapy分布式原理笔记的更多相关文章
- Python 爬虫之 Scrapy 分布式原理以及部署
Scrapy分布式原理 关于Scrapy工作流程 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享 ...
- scrapy分布式原理
scrapy分布式原理 关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键 ...
- 教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http://www.xiaohuar.com/,让你体验爬取校花的成就感. Scr ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Linux 安装python爬虫框架 scrapy
Linux 安装python爬虫框架 scrapy http://scrapy.org/ Scrapy是python最好用的一个爬虫框架.要求: python2.7.x. 1. Ubuntu14.04 ...
- Python爬虫框架Scrapy实例(三)数据存储到MongoDB
Python爬虫框架Scrapy实例(三)数据存储到MongoDB任务目标:爬取豆瓣电影top250,将数据存储到MongoDB中. items.py文件复制代码# -*- coding: utf-8 ...
- 《Python3网络爬虫开发实战》PDF+源代码+《精通Python爬虫框架Scrapy》中英文PDF源代码
下载:https://pan.baidu.com/s/1oejHek3Vmu0ZYvp4w9ZLsw <Python 3网络爬虫开发实战>中文PDF+源代码 下载:https://pan. ...
- Python爬虫框架Scrapy教程(1)—入门
最近实验室的项目中有一个需求是这样的,需要爬取若干个(数目不小)网站发布的文章元数据(标题.时间.正文等).问题是这些网站都很老旧和小众,当然也不可能遵守 Microdata 这类标准.这时候所有网页 ...
- 0.Python 爬虫之Scrapy入门实践指南(Scrapy基础知识)
目录 0.0.Scrapy基础 0.1.Scrapy 框架图 0.2.Scrapy主要包括了以下组件: 0.3.Scrapy简单示例如下: 0.4.Scrapy运行流程如下: 0.5.还有什么? 0. ...
随机推荐
- 前端框架之Vue(5)-条件渲染
v-if 在字符串模板中,比如 Django Template语法中,我们得像这样写一个条件块: <!-- Handlebars 模板 --> {%if 1%} <h1>Yes ...
- vue-自定义全局键盘码
1.Vue.config.keyCodes.enter=13; //main.js中定义全局 <template> <div> <input v-model=" ...
- npm install webpack -g
npm install webpack -g 全局安装webpack
- MyBatis——模糊查询
在mybatis中可以使用三种模糊查询的方式: <!-- 模糊查询 --> <select id="selectListByTitle" parameterTyp ...
- 多态使用时,父类多态时需要使用子类特有对象。需要判断 就使用instanceof
instanceof:通常在向下转型前用于健壮性的判断,判断是符合哪一个子类对象 package Polymorphic; public class TestPolymorphic { public ...
- Hadoop生态集群hdfs原理(转)
初步掌握HDFS的架构及原理 原文地址:https://www.cnblogs.com/codeOfLife/p/5375120.html 目录 HDFS 是做什么的 HDFS 从何而来 为什么选 ...
- SaltStack 数据系统 Grains Pillar
grains 先来一个很好用的命令 # salt '*' grains.items \\基本上输出了所有你想要的信息 192.168.100.138: ---------- SSDs: biosrel ...
- 笔记:yum和apt-get的区别
rpm包和deb包是两种Linux系统下最常见的安装包格式,在安装一些软件或服务的时候免不了要和它们打交道. rpm包主要应用在RedHat系列包括 Fedora等发行版的Linux系统上, deb包 ...
- mybatis--parametertype的参数传递
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC ...
- winform下picturebox控件显示图片问题
viewData_pictureBox.SizeMode=PictureBoxSizeMode.StretchImage;图片会自动按照比例缩放来完全显示在你的PictureBox中.