python爬虫(6)——正则表达式(三)
下面,我再写一个例子,加强对正则表达式的理解。还是回到我们下载的那个二手房网页,在实际中,我们并不需要整个网页的内容,因此我们来改进这个程序,对网页上的信息进行过滤筛选,并保存我们需要的内容。打开chrome浏览器,右键检查。

在网页源码中找到了我们所需要的内容。为了调试程序,我们可以在 http://tool.oschina.net/regex/ 上测试编译好的正则表达式。
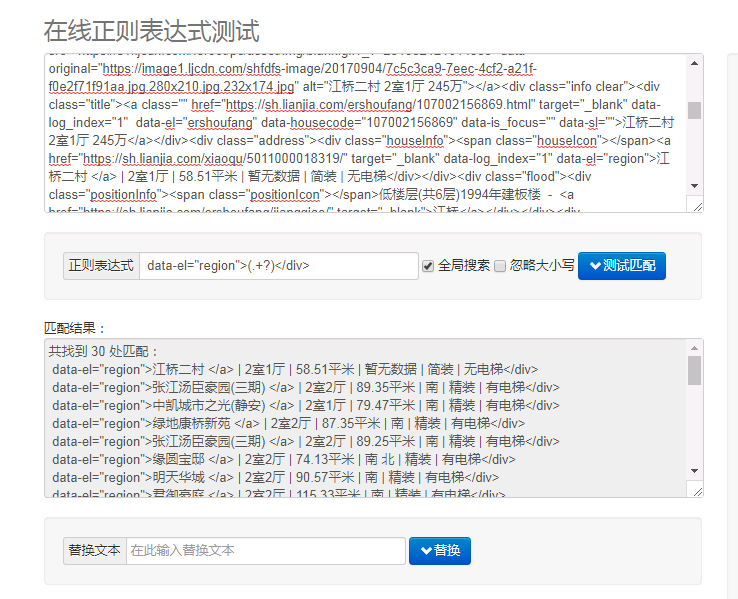
对于 houseinfo:pattern=r' data-el="region">(.+?)</div>'
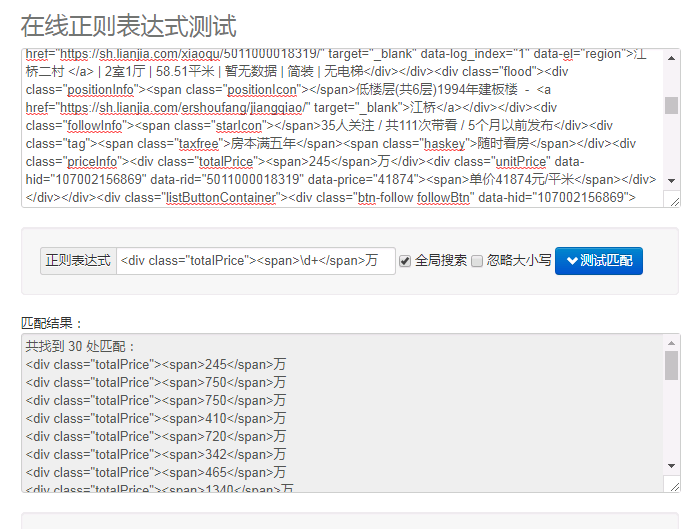
对于 price:pattern=r'<div class="totalPrice"><span>\d+</span>万'
我们用正则提取的内容是有冗余部分的,可以联想到用切片的方法处理提取内容。上源码:
from urllib import request
import re def HTMLspider(url,startPage,endPage): #作用:负责处理URL,分配每个URL去发送请求 for page in range(startPage,endPage+1):
filename="第" + str(page) + "页.html" #组合为完整的url
fullurl=url + str(page) #调用loadPage()发送请求,获取HTML页面
html=loadPage(fullurl,filename) def loadPage(fullurl,filename):
#获取页面
response=request.urlopen(fullurl)
Html=response.read().decode('utf-8')
#print(Html) #正则编译,获取房产信息
info_pattern=r'data-el="region">(.+?)</div>'
info_list=re.findall(info_pattern,Html)
#print(info_list)
#正则编译,获取房产价格
price_pattern=r'<div class="totalPrice"><span>\d+</span>万'
price_list=re.findall(price_pattern,Html)
#print(price_list) writePage(price_list,info_list,filename) def writePage(price_list,info_list,filename):
"""
将服务器的响应文件保存到本地磁盘
"""
list1=[]
list2=[]
for i in price_list:
i='-------------->>>>>Price:' + i[30:-8] + '万'
list1.append(i)
#print(i[30:-8])
for j in info_list:
j=j.replace('</a>',' '*10)
j=j[:10] + ' '*5 + '---------->>>>>Deatil information: ' + j[10:] + ' '*5
list2.append(j)
#print(j) for each in zip(list2,list1):
print(each) print("正在存储"+filename)
#with open(filename,'wb') as f:
# f.write(html) print("--"*30) if __name__=="__main__":
#输入需要下载的起始页和终止页,注意转换成int类型
startPage=int(input("请输入起始页:"))
endPage=int(input("请输入终止页:")) url="https://sh.lianjia.com/ershoufang/" HTMLspider(url,startPage,endPage) print("下载完成!")
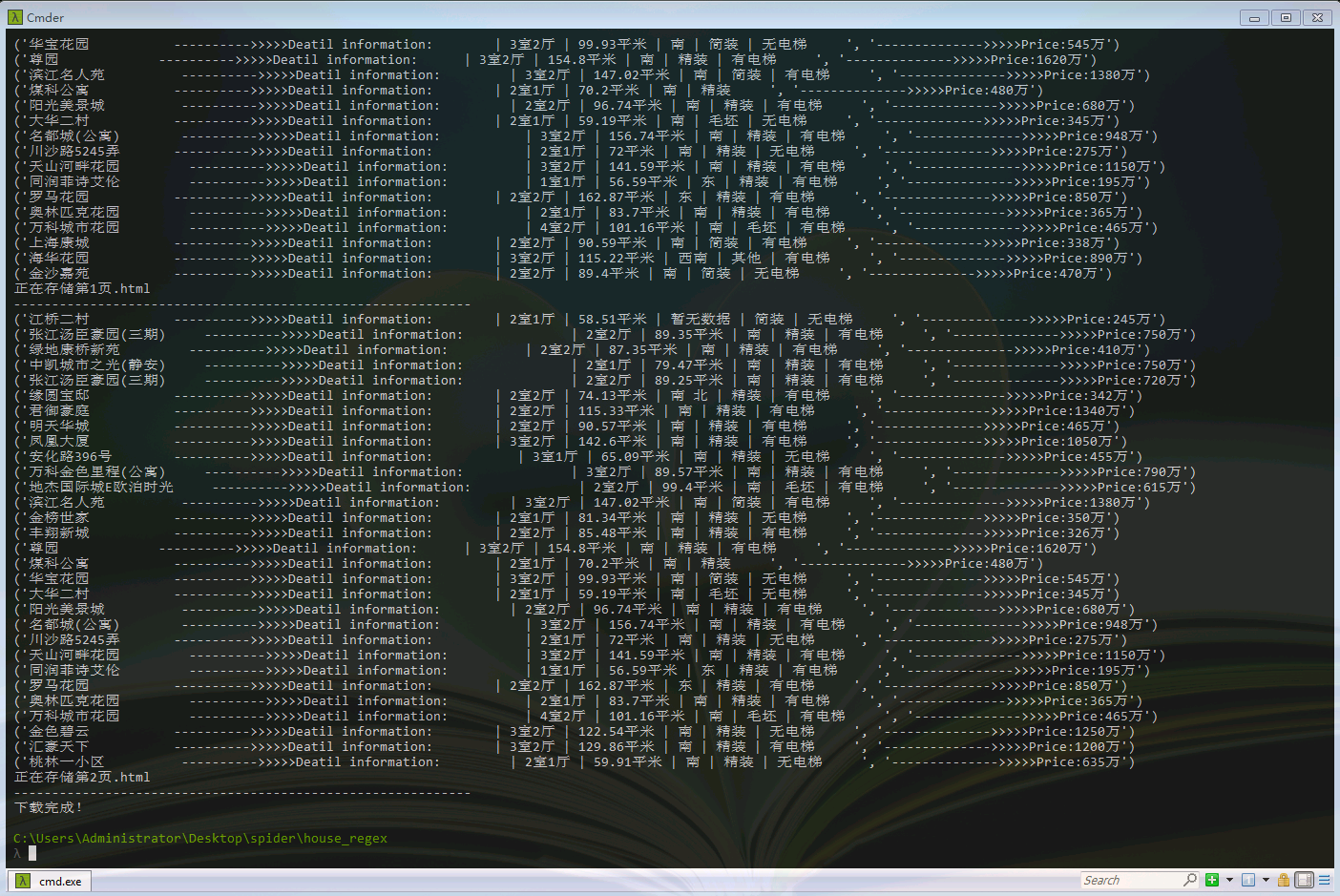
这是程序运行后的结果。我只是将其打印在终端,也可以使用json.dumps(),将爬取到的内容保存到本地中。
实际上这种数据提取还有其他方法,这将在以后会讲到。
python爬虫(6)——正则表达式(三)的更多相关文章
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- 玩转python爬虫之正则表达式
玩转python爬虫之正则表达式 这篇文章主要介绍了python爬虫的正则表达式,正则表达式在Python爬虫是必不可少的神兵利器,本文整理了Python中的正则表达式的相关内容,感兴趣的小伙伴们可以 ...
- 【Python爬虫】正则表达式与re模块
正则表达式与re模块 阅读目录 在线正则表达式测试 常见匹配模式 re.match re.search re.findall re.compile 实战练习 在线正则表达式测试 http://tool ...
- 路飞学城-Python爬虫集训-第三章
这个爬虫集训课第三章的作业讲得是Scrapy 课程主要是使用Scrapy + Redis实现分布式爬虫 惯例贴一下作业: Python爬虫可以使用Requests库来进行简单爬虫的编写,但是Reque ...
- python 爬虫之-- 正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. 正则表达式非python独有,python 提供了正则表达式的接口,re模块 一.正则匹配字符简介 模式 描述 \d ...
- Python爬虫学习笔记(三)
Cookies: 以抓取https://www.yaozh.com/为例 Test1(不使用cookies): 代码: import urllib.request # 1.添加URL url = &q ...
- Python爬虫之正则表达式的使用(三)
正则表达式的使用 re.match(pattern,string,flags=0) re.match尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none 参数 ...
- python爬虫训练——正则表达式+BeautifulSoup爬图片
这次练习爬 传送门 这贴吧里的美食图片. 如果通过img标签和class属性的话,用BeautifulSoup能很简单的解决,但是这次用一下正则表达式,我这也是参考了该博主的博文:传送门 所有图片的s ...
- Python 爬虫入门(三)—— 寻找合适的爬取策略
写爬虫之前,首先要明确爬取的数据.然后,思考从哪些地方可以获取这些数据.下面以一个实际案例来说明,怎么寻找一个好的爬虫策略.(代码仅供学习交流,切勿用作商业或其他有害行为) 1).方式一:直接爬取网站 ...
- 【python爬虫和正则表达式】爬取表格中的的二级链接
开始进公司实习的一个任务是整理一个网页页面上二级链接的内容整理到EXCEL中,这项工作把我头都搞大了,整理了好几天,实习生就是端茶送水的.前段时间学了爬虫,于是我想能不能用python写一个爬虫一个个 ...
随机推荐
- ES6中export , export default , import模块系统总结
最近在学习使用Webpack3的时候发现,它已经可以在不使用babel的情况下使用ES6的模块加载功能了. 说到ES6的模块加载功能,我们先复习一下CommonJS规范吧: 一 . CommonJS ...
- SQL的各种连接(cross join、inner join、full join)的用法理解
SQL中的连接可以分为内连接,外连接,以及交叉连接 . 1. 交叉连接CROSS JOIN 如果不带WHERE条件子句,它将会返回被连接的两个表的笛卡尔积,返回结果的行数等于两个表行数的乘积: 举例, ...
- php中urldecode()和urlencode()起什么作用啊
urlencode()函数原理就是首先把中文字符转换为十六进制,然后在每个字符前面加一个标识符%. urldecode()函数与urlencode()函数原理相反,用于解码已编码的 URL 字符串,其 ...
- ios - 如何获取app上的数据
做过ios开发的人应该都用过Charles,通常叫它花瓶.Charles是Mac下常用的对网络流量进行分析的工具,类似于Windows下的Fiddler.在开发iOS程序的时候,往往需要调试客户端和服 ...
- TCP长连接和短连接的区别
当网络通信时采用TCP协议时,在真正的读写操作之前,server与client之间必须建立一个连接,当读写操作完成后,双方不再需要这个连接时它们可以释放这个连接,连接的建立是需要三次握手的,而释放则需 ...
- vue不是内部或外部命令,配置一个Path系统变量就可以解决
作为一个vue小白,最近为vue安装真是操碎了心.无论怎么查找网上的教程,还是解决不了"vue不是内部或外部的命令"诸如此类的问题.好在功夫不负有心人,终于在多次的试验下,成功解决 ...
- mmap 测试的一些坑
最近遇到一个mmap的问题,然后为了测试该问题,写了如下测试代码: #include <sys/mman.h> #include <sys/stat.h> #include & ...
- 从(0,0)到(m,n),每次走一步,只能向上或者向右走,有多少种路径走到(m,n)
body, table{font-family: 微软雅黑; font-size: 10pt} table{border-collapse: collapse; border: solid gray; ...
- php foreach用法和实例
原文地址:http://www.cnblogs.com/DaBing0806/p/4717718.html foreach()有两种用法:1: foreach(array_name as $value ...
- "Cache-control”常见的取值private、no-cache、max-age、must-revalidate及其用意
http://www.cnblogs.com/kaima/archive/2009/10/13/1582337.html 网页的缓存是由HTTP消息头中的"Cache-control&quo ...