python爬虫(6)——正则表达式(三)
下面,我再写一个例子,加强对正则表达式的理解。还是回到我们下载的那个二手房网页,在实际中,我们并不需要整个网页的内容,因此我们来改进这个程序,对网页上的信息进行过滤筛选,并保存我们需要的内容。打开chrome浏览器,右键检查。

在网页源码中找到了我们所需要的内容。为了调试程序,我们可以在 http://tool.oschina.net/regex/ 上测试编译好的正则表达式。
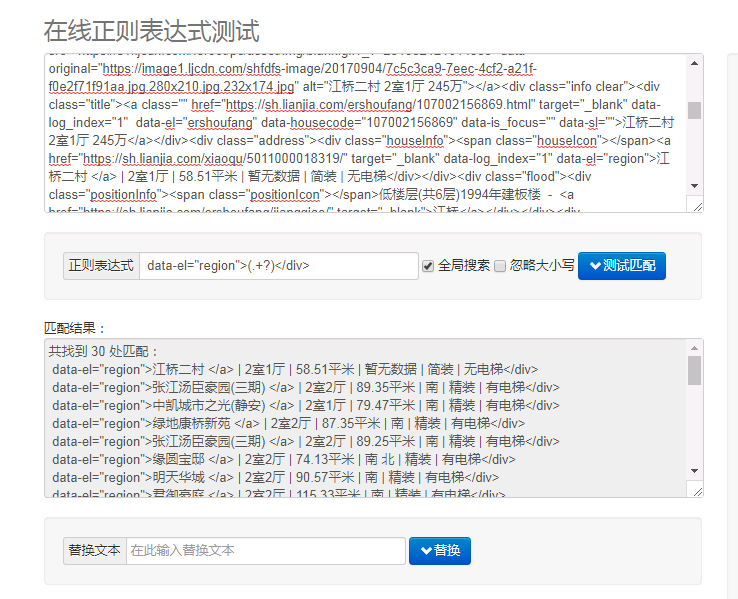
对于 houseinfo:pattern=r' data-el="region">(.+?)</div>'
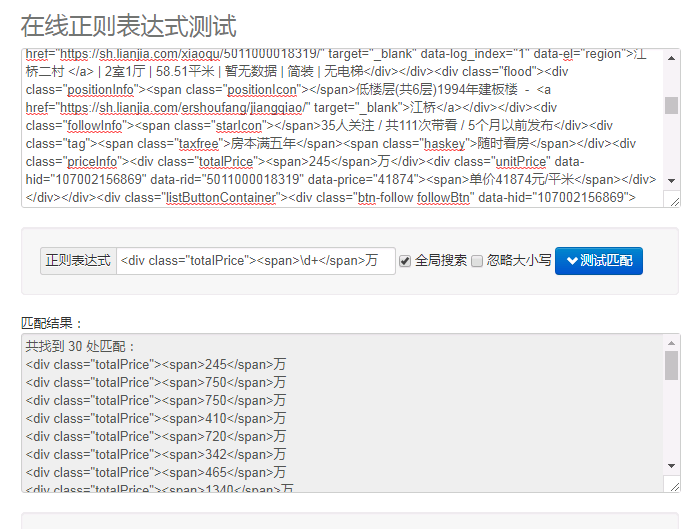
对于 price:pattern=r'<div class="totalPrice"><span>\d+</span>万'
我们用正则提取的内容是有冗余部分的,可以联想到用切片的方法处理提取内容。上源码:
from urllib import request
import re def HTMLspider(url,startPage,endPage): #作用:负责处理URL,分配每个URL去发送请求 for page in range(startPage,endPage+1):
filename="第" + str(page) + "页.html" #组合为完整的url
fullurl=url + str(page) #调用loadPage()发送请求,获取HTML页面
html=loadPage(fullurl,filename) def loadPage(fullurl,filename):
#获取页面
response=request.urlopen(fullurl)
Html=response.read().decode('utf-8')
#print(Html) #正则编译,获取房产信息
info_pattern=r'data-el="region">(.+?)</div>'
info_list=re.findall(info_pattern,Html)
#print(info_list)
#正则编译,获取房产价格
price_pattern=r'<div class="totalPrice"><span>\d+</span>万'
price_list=re.findall(price_pattern,Html)
#print(price_list) writePage(price_list,info_list,filename) def writePage(price_list,info_list,filename):
"""
将服务器的响应文件保存到本地磁盘
"""
list1=[]
list2=[]
for i in price_list:
i='-------------->>>>>Price:' + i[30:-8] + '万'
list1.append(i)
#print(i[30:-8])
for j in info_list:
j=j.replace('</a>',' '*10)
j=j[:10] + ' '*5 + '---------->>>>>Deatil information: ' + j[10:] + ' '*5
list2.append(j)
#print(j) for each in zip(list2,list1):
print(each) print("正在存储"+filename)
#with open(filename,'wb') as f:
# f.write(html) print("--"*30) if __name__=="__main__":
#输入需要下载的起始页和终止页,注意转换成int类型
startPage=int(input("请输入起始页:"))
endPage=int(input("请输入终止页:")) url="https://sh.lianjia.com/ershoufang/" HTMLspider(url,startPage,endPage) print("下载完成!")
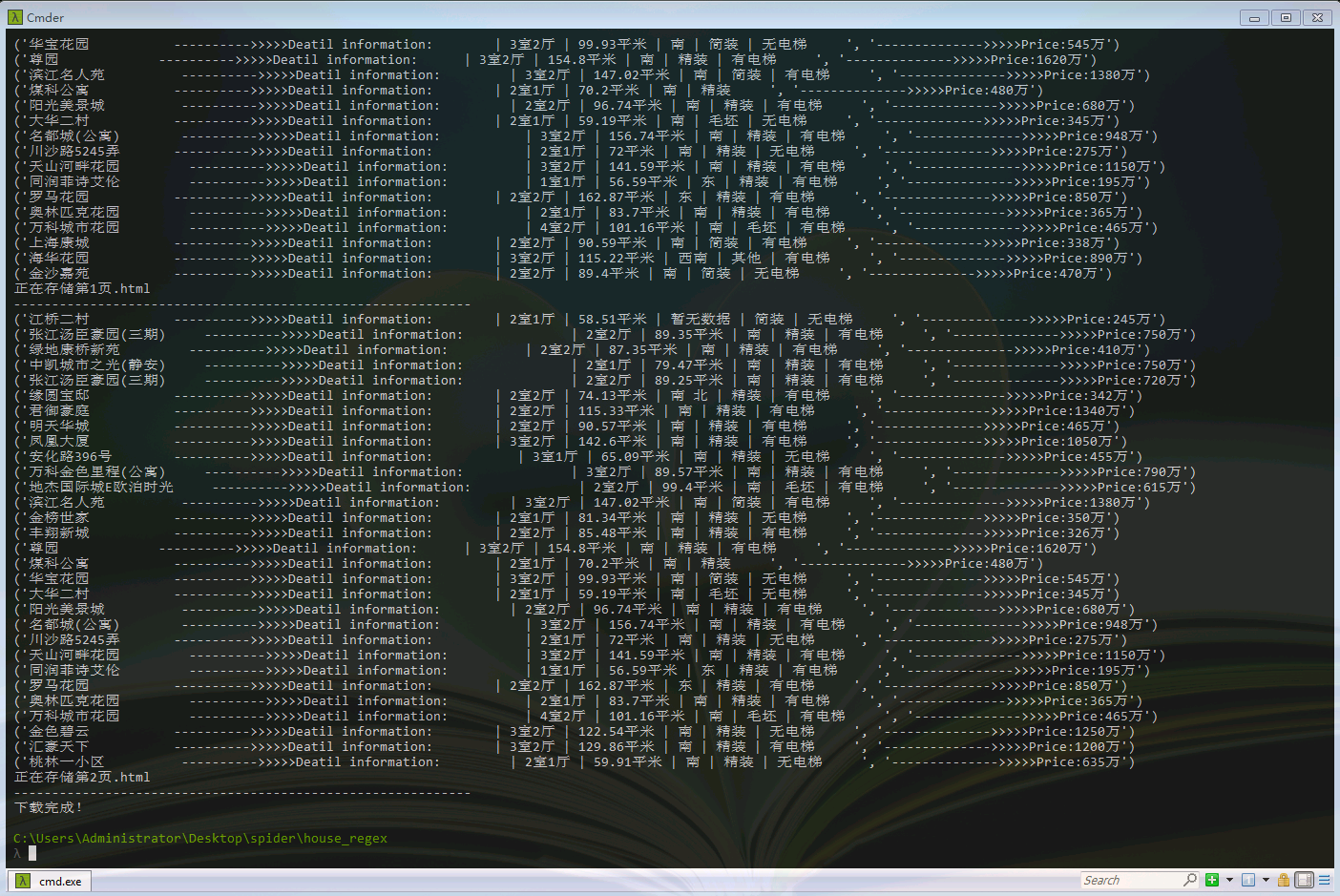
这是程序运行后的结果。我只是将其打印在终端,也可以使用json.dumps(),将爬取到的内容保存到本地中。
实际上这种数据提取还有其他方法,这将在以后会讲到。
python爬虫(6)——正则表达式(三)的更多相关文章
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- 玩转python爬虫之正则表达式
玩转python爬虫之正则表达式 这篇文章主要介绍了python爬虫的正则表达式,正则表达式在Python爬虫是必不可少的神兵利器,本文整理了Python中的正则表达式的相关内容,感兴趣的小伙伴们可以 ...
- 【Python爬虫】正则表达式与re模块
正则表达式与re模块 阅读目录 在线正则表达式测试 常见匹配模式 re.match re.search re.findall re.compile 实战练习 在线正则表达式测试 http://tool ...
- 路飞学城-Python爬虫集训-第三章
这个爬虫集训课第三章的作业讲得是Scrapy 课程主要是使用Scrapy + Redis实现分布式爬虫 惯例贴一下作业: Python爬虫可以使用Requests库来进行简单爬虫的编写,但是Reque ...
- python 爬虫之-- 正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. 正则表达式非python独有,python 提供了正则表达式的接口,re模块 一.正则匹配字符简介 模式 描述 \d ...
- Python爬虫学习笔记(三)
Cookies: 以抓取https://www.yaozh.com/为例 Test1(不使用cookies): 代码: import urllib.request # 1.添加URL url = &q ...
- Python爬虫之正则表达式的使用(三)
正则表达式的使用 re.match(pattern,string,flags=0) re.match尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none 参数 ...
- python爬虫训练——正则表达式+BeautifulSoup爬图片
这次练习爬 传送门 这贴吧里的美食图片. 如果通过img标签和class属性的话,用BeautifulSoup能很简单的解决,但是这次用一下正则表达式,我这也是参考了该博主的博文:传送门 所有图片的s ...
- Python 爬虫入门(三)—— 寻找合适的爬取策略
写爬虫之前,首先要明确爬取的数据.然后,思考从哪些地方可以获取这些数据.下面以一个实际案例来说明,怎么寻找一个好的爬虫策略.(代码仅供学习交流,切勿用作商业或其他有害行为) 1).方式一:直接爬取网站 ...
- 【python爬虫和正则表达式】爬取表格中的的二级链接
开始进公司实习的一个任务是整理一个网页页面上二级链接的内容整理到EXCEL中,这项工作把我头都搞大了,整理了好几天,实习生就是端茶送水的.前段时间学了爬虫,于是我想能不能用python写一个爬虫一个个 ...
随机推荐
- HDU 1069 Monkey and Banana(DP——最大递减子序列)
题目链接: http://acm.split.hdu.edu.cn/showproblem.php?pid=1069 题意描述: 给n块砖,给出其长,宽和高 问将这n块砖,怎样叠放使得满足以下条件使得 ...
- node学习笔记2 —— npm包管理
全局模式安装包 将包安装为全局可用的可执行命令, 并非可以从任意地方require 将 package.json中bin定义的文件软链到统一的目录下, 该目录可以通过如下方式推算出来: path.re ...
- phpstorm ctrl+shift+F键不管用,不弹出搜索弹框
般热键冲突搜狗默认简繁切换组合键位ctrl+shift+F故outlook2011按三建且失效应该能看搜狗输入状态简繁变搜狗设置按键-取消选简繁切换热键即在任务栏的语言地方点击一下再点击语言首选项.进 ...
- 怎样实现给DEDE的栏目增加栏目图片(2)
2.3 打开dede/templets/catalog_edit.htm页面,查找 栏目名称:
- ABB中断设定
简介: 中断是程序定义事件,通过中断编号识别.中断发生在中断条件为真时.中断不同于其他错误,前者与特定消息号位置无直接关系(不同步).中断会导致正常程序执行过程暂停,跳过控制,进入软中断程序. 即使机 ...
- 让自己写的项目支持Cocoapods管理
学会使用别人的 Pods 依赖库以后, 你一定对创建自己的依赖库很有兴趣吧,现在我们一起来制作自己的Pods依赖库. 1.创建自己的 github 仓库 上图中标识出了6处地方 Repository ...
- 2017-07-10(lastlog rpm yum)
lastlog 查看所有用户最后一次登录的时间 rpm www.rpmfind.net 用来确认函数库需要安装哪个依赖程序的的网站 rpm -ivh 包全名 (安装) rpm -Uvh 包全名( ...
- 《UNIX实用教程》读书笔记
原著:<Just Enough UNIX> Fifth Edition [美]Paul K.Andersen 译著:<UNIX实用教程> 第5版 宋虹 曾庆冬 段桂华 杨路 ...
- POI--HSSFRow类
用POI在工作表里作成一个行,可以用「HSSFRow」类,它的构造方法有三个. protected HSSFRow() protected HSSFRow(Workbook book, Sheet s ...
- web技术发展历程--读《大型网站技术架构_核心原理与案例分析》
1 早期的web服务 2 CGI程序的出现.发展.凋零到MVC的兴起 CGI:通用网关接口技术. 随着CGI技术的出现,web服务端可以通过不同的用户请求产生动态页面内容. web服务器将请求数据交给 ...