Apriori算法-频繁项集-关联规则
计算频繁项集:
首先生成一个数据集
def loadDataSet():
return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]

测试数据集dataset有了,第一步,我们要根据数据集dataset得到一个集合C1,集合C1中包含的元素为dataset的无重复的每个单元素,候选项集。
def createC1(dataset):
C1 = []
for transaction in dataset:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort()
return map(frozenset, C1)
返回的数据map计算得到一个元素为frozenset的集合。
为什么要转成frozenset?

原因两个:
1. 这个集合是从dataset中抽取出所有无重复的数据集,是固定的,应该是不可变的类型。
2. frozenset可以作字典
可以看一下返回结果:
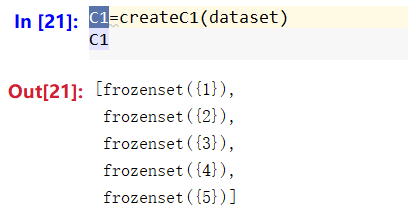
第二步,计算C1<key>每个元素key的支持度。
支持度= count(key) / sizeof(C1)
def scanD(D, Ck, minSupport):
ssCnt = {}
for tid in D:
for can in Ck:
if can.issubset(tid):
if not ssCnt.has_key(can):
ssCnt[can] = 1
else:
ssCnt[can] += 1
numitems = float(len(D)) # 数据集长度
retList = []
supportData = {}
for key in ssCnt:
support = ssCnt[key] / numitems
if support >= minSupport:
retList.insert(0, key)
supportData[key] = support
return retList, supportData
调用返回结果:
先把dataset转成元素为集合的类型。
这里设置支持度为0.5。当key在dataset中出现的集合个数超过一半即认为是频繁项。
L1是根据计算C1中每个元素是否满足支持度规则过滤得到的C1的子集。
L1的元素两两组合构成C2,再根据C2中每个元素是否满足支持度规则过滤得到的C1的子集L2。依次类推,直到Lk是单元素集合。
添加如下代码,可以得到一个完整的找频繁项集的代码:

def aprioriGen(Lk, k):
retList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i + 1, lenLk):
L1 = list(Lk[i])[:k - 2];
L2 = list(Lk[j])[:k - 2]
L1.sort()
L2.sort()
if L1 == L2:
retList.append(Lk[i] |
Lk[j])
return retList
def apriori(dataset, minsupport=0.5):
C1 = createC1(dataset) # 候选项集
D = map(set, dataset) # 数据集
L1, supportData =
scanD(D, C1, minsupport) # 频繁项集与支持度
L = [L1]
k = 2
while (len(L[k - 2]) > 0):
Ck = aprioriGen(L[k - 2], k)
Lk, supK = scanD(D, Ck,
minsupport)
supportData.update(supK)
L.append(Lk)
k += 1
return L, supportData
apriori是主函数,这里对Lk进行了合并,如果Lk的两个元素(都是集合,假设分别是Lk1,Lk2)的[0:k-2]是一样的,(k是什么?k是Lk1的长度加1)比方说:
example1:
{a},{c} k=2
[0:k-2]分别是{}=={},需要进行合并。得到{a,c}
注意:[0:0]意思是从0开始取(含0),直到0(不含0),所以是{}
example2:
{a,c},{a,d} k=3
[0:k-2]分别是{a}=={a},合并得到{a,c,d}
注意:[0:1]意思是从0开始取(含0),直到1(不含1),所以是{a}
应该能理解怎么合并的了。
为什么要合并?
上面解释了怎么合并,以及合并的规则。我们拿到的数据是由C1生成的L1,L1是单元素中符合支持度的构成的集合。所以我们只需要对L1进行组合,就能得到二元素集合C2,并根据支持度过滤得到其中符合支持度的二元素的频繁项集L2。由L1得到C2,这就是为什么要合并的理由。
为什么用这种合并规则呢?
L1={[frozenset([1]), frozenset([3]),
frozenset([2]), frozenset([5])]}
很明显,我们可以组合得到
Ck[k=2]={[frozenset([1, 3]), frozenset([1, 2]), frozenset([1, 5]), frozenset([2, 3]), frozenset([3, 5]), frozenset([2, 5])]}
scanD(D, Ck, minsupport)执行该函数得到我们想要的
Lk[k=2]= {[frozenset([1, 3]), frozenset([2, 5]), frozenset([2, 3]), frozenset([3, 5])]}。
接着看:
接下来我们就要对Lk[k=2]进行组合了。按照我们的规则:
[1,3]没有与之可以合并的。
[2,5][2,3]可以合并。得到[2,3,5]
[3,5]没有与之合并的。
所以Ck[k=3]={[frozenset([2, 3, 5])]}
假如我们不按照该规则来:
[1,3][2,5]=>[1,2,3,5],三元素集合这点规则是必须要遵守的。
[1,3][2,3]=>[1,2,3]出现[1,2]该子集不满足支持度。
[1,3][3,5]=>[1,3,5]出现[1,5]该子集不满足支持度。
[2,5][2,3]=>[2,3,5]
[2,5][3,5]=>[2,3,5]
[2,3][3,5]=>[2,3,5]出现三个重复的[2,3,5],还需要我们添加去重规则,相对比较麻烦。而且按照我们的规则,可以减少集合的数目,省去遍历去重的过程,降低算法的时间复杂度。
根据规则生成的Ck,是建立在不违背最小支持度的基础之上的,至于生成的Ck是否符合最小支持度,接下来要使用scanD算法来进行验证,并丢掉不符合最小支持度的项集。
有一个问题:
k-2的操作,到底是怎么做到的,避免出现类似[1,2,3]这种含有[1,2]子集是之前已经被抛弃的集合。还是说,这里就是一个巧合?。
挖掘关联规则:
1. # 下面是关联规则 默认最小置信度为0.7
2. # 主函数
3. def generateRules(L, supportData, minConf=0.7):
4. bigRuleList = []
5. for i in range(1, len(L)): # 不处理单元素集合L[0]
6. for freqSet in L[i]:
7. H1 = [frozenset([item]) for item in freqSet]
8. if (i > 1): # 当集合中元素的长度大于2的时候,尝试对集合合并。
9. # 比如:[2,3,5]=>{[2,3],5}
10. rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf)
11. else: # 对于2元组,直接计算置信度
12. calConf(freqSet, H1, supportData, bigRuleList, minConf)
13. return bigRuleList
14.
15.
16.def calConf(freqSet, H, supportData, brl, minConf=0.7):
17. prunedH = []
18. for conseq in H:
19. conf = supportData[freqSet] / supportData[freqSet - conseq] # 置信度
20. if conf >= minConf:
21. print freqSet - conseq, "--->", conseq, "conf", conf
22. brl.append((freqSet - conseq, conseq, conf))
23. prunedH.append(conseq)
24. if (len(freqSet) > 2):
25. conf = supportData[freqSet] / supportData[conseq] # 置信度
26. if conf >= minConf:
27. print conseq, "--->", freqSet - conseq, "conf", conf
28. brl.append((conseq, freqSet - conseq, conf))
29. prunedH.append(freqSet - conseq)
30. return prunedH
31.
32.
33.def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):
34. m = len(H[0])
35. if (len(freqSet) > (m + 1)):
36. Hmp1 = aprioriGen(H, m + 1)
37. Hmp1 = calConf(freqSet, Hmp1, supportData, brl, minConf)
38. if (len(Hmp1) > 1):
39. rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)
40.
41.
42.ruleList = generateRules(L, supportData)
43.# print ruleList
对rulesFromConseq解释一下:
在主函数generateRules中的标记处,此时freqSet是三元组[2,3,5],尝试对其元素进行合并。调用rulesFromConseq,执行aprioriGen(H, m + 1)得到Hmp1={[frozenset([2, 3]), frozenset([2, 5]),
frozenset([3, 5])]}
然后调用calConf计算置信度。
这里对calConf补充了如下代码:
1. if (len(freqSet) > 2):
2. conf = supportData[freqSet] / supportData[conseq] # 置信度
3. if conf >= minConf:
4. print conseq, "--->", freqSet - conseq, "conf", conf
5. brl.append((conseq, freqSet - conseq, conf))
6. prunedH.append(freqSet - conseq)
理由:原代码,如果freqSet =[2,3,5] H={[frozenset([2, 3]), frozenset([2, 5]), frozenset([3, 5])]}
[2,3,5]去计算对[2][3][5]的置信度均不符合最小要求,返回[],无法继续对[2,3][2,5][3,5]进行置信度验证。
源代码:https://files.cnblogs.com/files/simuhunluo/Apriori%E7%AE%97%E6%B3%95%E4%BB%A3%E7%A0%81.zip
Apriori算法-频繁项集-关联规则的更多相关文章
- 海量数据挖掘MMDS week2: Association Rules关联规则与频繁项集挖掘
http://blog.csdn.net/pipisorry/article/details/48894977 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- apriori && fpgrowth:频繁模式与关联规则挖掘
已迁移到我新博客,阅读体验更佳apriori && fpgrowth:频繁模式与关联规则挖掘 详细代码我放在github上:click me 一.实验说明 1.1 任务描述 1.2 数 ...
- FP-growth高效频繁项集发现
FP-growth 算法优缺点: 优点:一般快于Apriori 缺点:实现比较困难,在某些数据上性能下降 适用数据类型:标称型数据 算法思想: FP-growth算法是用来解决频繁项集发现问题的,这个 ...
- 关联规则—频繁项集Apriori算法
频繁模式和对应的关联或相关规则在一定程度上刻画了属性条件与类标号之间的有趣联系,因此将关联规则挖掘用于分类也会产生比较好的效果.关联规则就是在给定训练项集上频繁出现的项集与项集之间的一种紧密的联系.其 ...
- Python两步实现关联规则Apriori算法,参考机器学习实战,包括频繁项集的构建以及关联规则的挖掘
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 海量数据挖掘MMDS week2: 频繁项集挖掘 Apriori算法的改进:非hash方法
http://blog.csdn.net/pipisorry/article/details/48914067 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 海量数据挖掘MMDS week2: 频繁项集挖掘 Apriori算法的改进:基于hash的方法
http://blog.csdn.net/pipisorry/article/details/48901217 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 手推Apriori算法------挖掘频繁项集
版权声明:本文为博主原创文章,未经博主允许不得转载. Apriori算法: 使用一种称为逐层搜索的迭代方法,其中K项集用于搜索(K+1)项集. 首先,通过扫描数据库,统计每个项的计数,并收集满足最小支 ...
- 使用 FP-growth 算法高效挖掘海量数据中的频繁项集
前言 对于如何发现一个数据集中的频繁项集,前文讲解的经典 Apriori 算法能够做到. 然而,对于每个潜在的频繁项,它都要检索一遍数据集,这是比较低效的.在实际的大数据应用中,这么做就更不好了. 本 ...
随机推荐
- UNIX环境高级编程——存储映射I/O(mmap函数)
共享内存可以说是最有用的进程间通信方式,也是最快的IPC形式,因为进程可以直接读写内存,而不需要任何数据的拷贝.对于像管道和消息队列等通信方式,则需要在内核和用户空间进行四次的数据拷贝,而共 ...
- 《java入门第一季》之UDP协议下的网络编程小案例
需求,一台电脑发送数据,其他电脑都可以收到该数据.使用广播地址. 发送端: import java.io.BufferedReader; import java.io.IOException; imp ...
- python字符串与数字类型转化
数字转字符串:str(数字),如str(10) 相反:int(字符串),如int('10') 另外,import string后 用string.atoi('100',base),转换为int,bas ...
- Socket编程实践(5) --TCP粘包问题与解决
TCP粘包问题 由于TCP协议是基于字节流且无边界的传输协议, 因此很有可能产生粘包问题, 问题描述如下 对于Host A 发送的M1与M2两个各10K的数据块, Host B 接收数据的方式不确定, ...
- 【嵌入式开发】gcc 学习笔记(一) - 编译C程序 及 编译过程
一. C程序编译过程 编译过程简介 : C语言的源文件 编译成 可执行文件需要四个步骤, 预处理 (Preprocessing) 扩展宏, 编译 (compilation) 得到汇编语言, 汇编 (a ...
- 基于web的jfreechart的使用
这个模块的主要步骤就是: 前台通过struts调用后台,通过JFreeChart产生图片格式的图表,存储在某个位置,然后前台jsp再去调用图片. 来开工. JFreeChart的简介大家请百度. 首先 ...
- 【一天一道LeetCode】#15 3Sum
一天一道LeetCode系列 (一)题目 Given an array S of n integers, are there elements a, b, c in S such that a + b ...
- C++模板总结
在编写含有模板的程序的时候,我还是按照一个头文件声明,一个源文件的方法来组织,结果编译的时候总出现一些很奇怪的语法问题,但程序明明是没有问题的.后来经过查阅才知道原来是因为C++编译器不支持对模板的分 ...
- Linux - vim按键说明
第一部份:一般模式可用的按钮说明,光标移动.复制贴上.搜寻取代等 移动光标的方法 h 或 向左箭头键(←) 光标向左移动一个字符 j 或 向下箭头键(↓) 光标向下移动一个字符 k 或 向上箭头键(↑ ...
- iOS下FMDB的多线程操作(一)
iOS中一些时间比较长的操作都应该放在子线程中,以避免UI的卡顿.而sqlite 是非线程安全的,故在多线程中不能共用同一个数据库连接,否则会导致EXC_BAD_ACCESS.所以我们可以在子线程中创 ...