Skip-Gram模型
Stanford CS224n的课程资料关于word2vec的推荐阅读里包含Word2Vec Tutorial - The Skip-Gram Model 这篇文章。这里针对此文章作一个整理。
word2vec做了什么事情
从字面意思上来说就是将单词word转为向量vector,通过词向量来表征语义信息。
word2vec模型
这篇文章主要介绍的是Skip-Gram模型,除此之外word2vec还有CBOW模型。
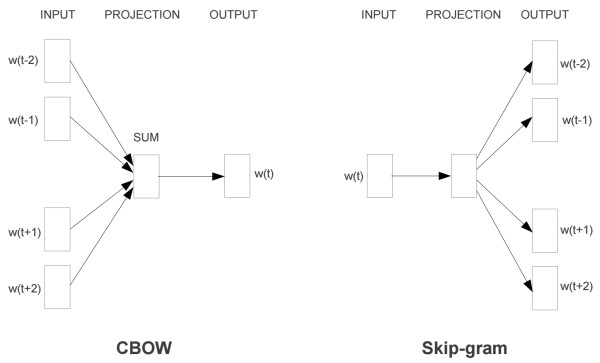
如上图所示,这两种模型的区别就是
- Skip-Gram是给定输入词来预测上下文
- 而CBOW则是给定上下文来预测输入词
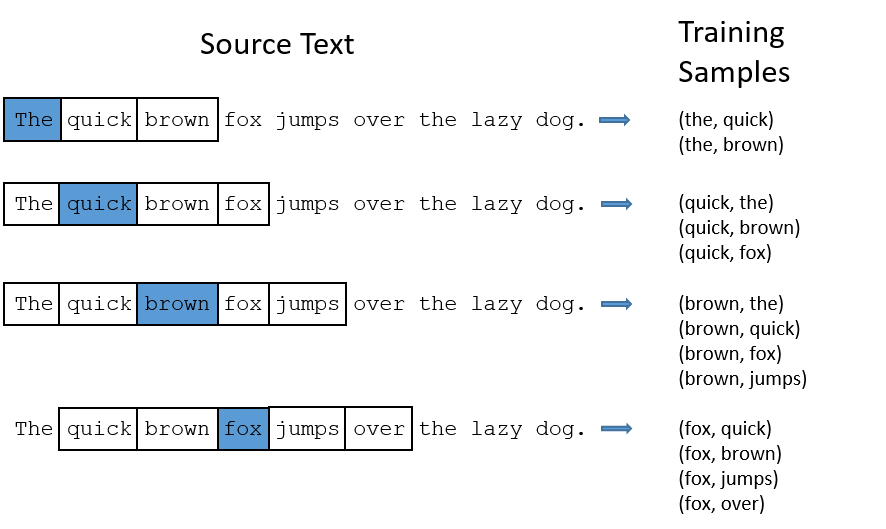
那么如何来训练Skip-Gram模型呢?上面这张图使用的句子是:"The quick brown fox jumps over the lazy dog.",通过逐一选定句子中的单词作为输入词,将与之相邻的词提取出来,进行学习。图中的窗口大小为2,也即每次向前和向后各看2个词(如果存在的话)。
一些细节
输入参数:通常会将文本中的词进行编码表示,如常见的有将文本库中的单词转换为词汇表,这样可以将每个单词通过one-hot编码表示。比如总共有10000个词,则每个单词最终都可以通过一个10000维向量表示。
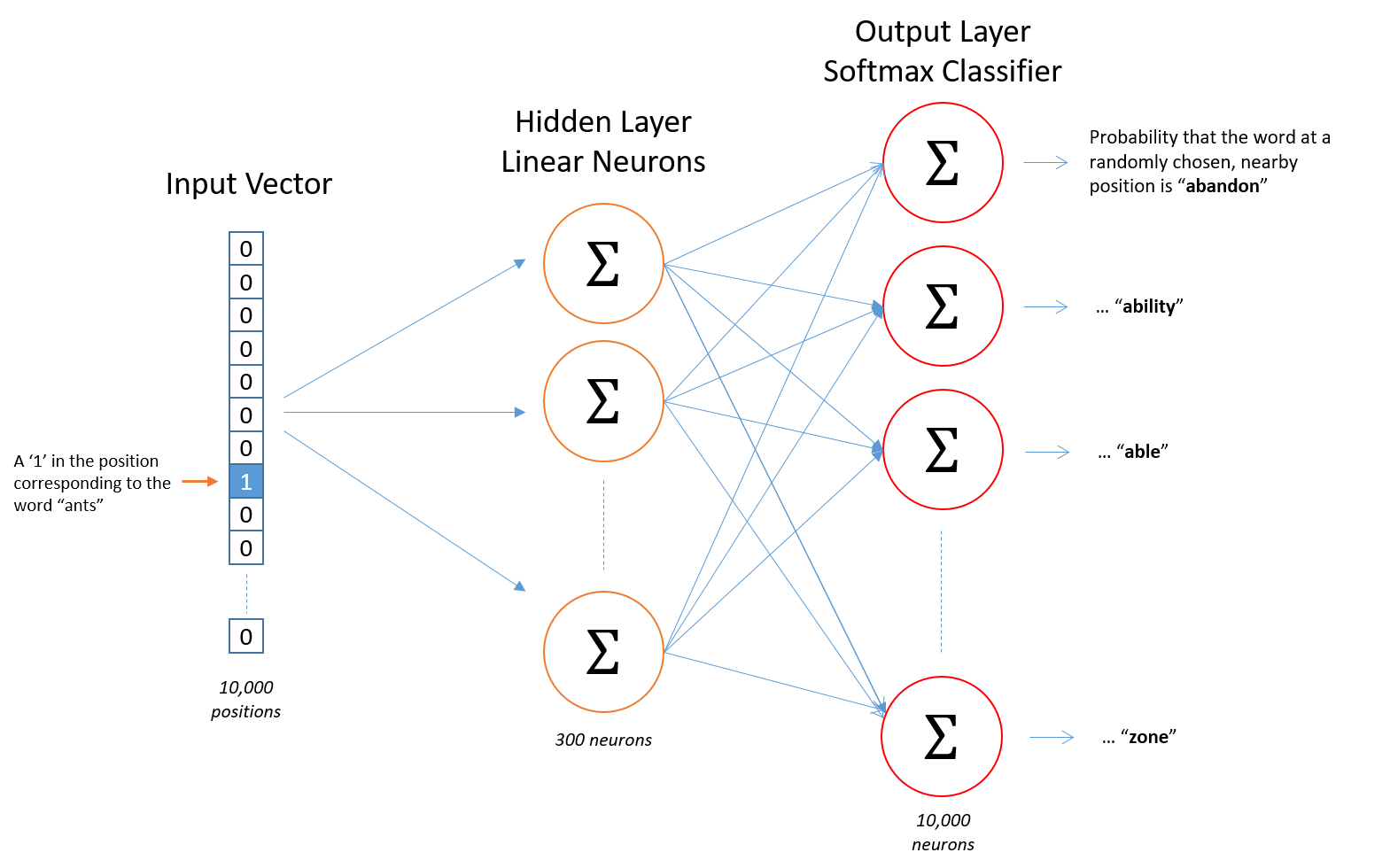
如上图所示,网络的输入是一个单词,10000维的one-hot向量,最终输出的结果也是一个10000维的向量,其中的值表示对应的词作为输入词的上下文的概率,也就是说最后输出的是输入词的邻近词的概率分布。
隐藏层
从上面的图也可以看出隐藏层中有300个神经元,也就是说输入词被表示为300维的一个向量。
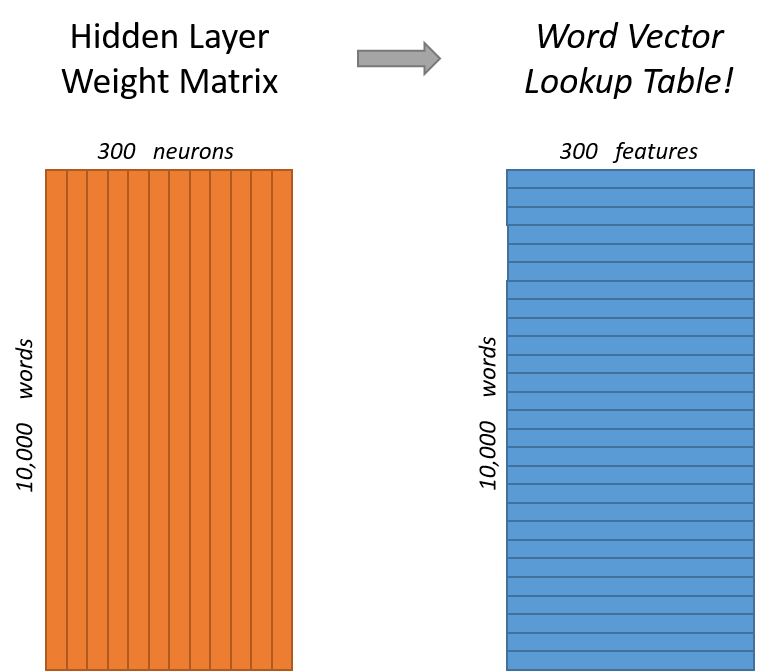
隐藏层中的权重矩阵大小为10000*300,一个10000维的one-hot输入词通过权重矩阵映射到了一个300维的向量,而这个向量正是所谓的word vector,对应于上图中右边的每一行。
另外值得提的是,如果将110000的输入向量与10000300的权重矩阵作乘积的话,其实效率挺低的。因为one-hot向量中只有1个元素是1,所以不难发现其实结果就是权重矩阵中的某一行。
输出层
在隐藏层中计算得到的300维的向量最终会再经过输出层变为10000维的向量,这里使用的是softmax回归,最终输出的结果所有概率之和为1。
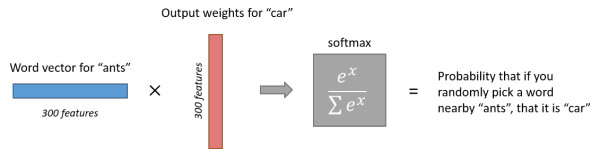
上图展示了输入词为ants,计算输出词为car的概率。
参考
Word2Vec Tutorial - The Skip-Gram Model
Skip-Gram模型的更多相关文章
- RNN、LSTM、Seq2Seq、Attention、Teacher forcing、Skip thought模型总结
RNN RNN的发源: 单层的神经网络(只有一个细胞,f(wx+b),只有输入,没有输出和hidden state) 多个神经细胞(增加细胞个数和hidden state,hidden是f(wx+b) ...
- Paddle Graph Learning (PGL)图学习之图游走类模型[系列四]
Paddle Graph Learning (PGL)图学习之图游走类模型[系列四] 更多详情参考:Paddle Graph Learning 图学习之图游走类模型[系列四] https://aist ...
- Tensorflow 的Word2vec demo解析
简单demo的代码路径在tensorflow\tensorflow\g3doc\tutorials\word2vec\word2vec_basic.py Sikp gram方式的model思路 htt ...
- word2vec的Java源码【转】
一.核心代码 word2vec.java package com.ansj.vec; import java.io.*; import java.lang.reflect.Array; import ...
- 利用 TensorFlow 入门 Word2Vec
利用 TensorFlow 入门 Word2Vec 原创 2017-10-14 chen_h coderpai 博客地址:http://www.jianshu.com/p/4e16ae0aad25 或 ...
- DeepLearning.ai学习笔记(五)序列模型 -- week2 自然语言处理与词嵌入
一.词汇表征 首先回顾一下之前介绍的单词表示方法,即one hot表示法. 如下图示,"Man"这个单词可以用 \(O_{5391}\) 表示,其中O表示One_hot.其他单词同 ...
- DLNg序列模型第二周NLP与词嵌入
1.使用词嵌入 给了一个命名实体识别的例子,如果两句分别是“orange farmer”和“apple farmer”,由于两种都是比较常见的,那么可以判断主语为人名. 但是如果是榴莲种植员可能就无法 ...
- NLP学习(4)----word2vec模型
一. 原理 哈弗曼树推导: https://www.cnblogs.com/peghoty/p/3857839.html 负采样推导: http://www.hankcs.com/nlp/word2v ...
- tensorflow在文本处理中的使用——CBOW词嵌入模型
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- tensorflow在文本处理中的使用——skip-gram模型
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
随机推荐
- 使用BizTalk实现RosettaNet B2B So Easy
使用BizTalk实现RosettaNet B2B So Easy 最近完成了一个vmi-hub的B2B项目,使用Rosettanet 2.0的标准与一家品牌商,OEM,供应商实现B2B.一共交换4个 ...
- python装饰器带括号和不带括号的语法和用法
装饰器的写法补充: 通常装饰器的写法是@func(),而有的时候为了减少出错率,可能会写成@func,没有()括号,这时我们可以这样定义,来减少括号.下面通过两个例子还看. 一般装饰器的写法: def ...
- SQLServer 2008R2 清理日志文件
设置数据库为简单模式 2.收缩日志文件 3.恢复数据库为完整模式
- HTML5仿微信公众号界面
jQuery连接: https://pan.baidu.com/s/1Qj948NPMDmcqzcMyKm8nMw 密码:vewr 图片连接: https://pan.baidu.com/s/1Fha ...
- mysql查询语句,通过limit来限制查询的行数。
mysql查询语句,通过limit来限制查询的行数. 例如: select name from usertb where age > 20 limit 0, 1; //限制从第一条开始,显示1条 ...
- Java并发编程:Java的四种线程池的使用,以及自定义线程工厂
目录 引言 四种线程池 newCachedThreadPool:可缓存的线程池 newFixedThreadPool:定长线程池 newSingleThreadExecutor:单线程线程池 newS ...
- Java框架之Struts2(五)
本文主要介绍Struts2 文件上传.Struts2 多文件上传.文件下载.上传文件的过滤.输入校验.输入校验的流程. 一.Struts2 文件上传 步骤: 1) 页面 <form action ...
- 【Spring】25、Spring代理。 BeanNameAutoProxyCreator 与 ProxyFactoryBean
一般我们可以使用ProxyBeanFactory,并配置proxyInterfaces,target和interceptorNames实现,但如果需要代理的bean很多,无疑会对spring配置文件的 ...
- Debian、Ubuntu恢复误删除(或者说重装)的/var/lib/dpkg
在使用ubuntu的使用,有可能会碰到dpkg挂掉,网上的通用解决方法,如果不管用: 1, dpkg 被中断,您必须手工运行 sudo dpkg --configure -a解决此问题 2, sudo ...
- blfs(systemv版本)学习笔记-编译安装配置dhcpcd
我的邮箱地址:zytrenren@163.com欢迎大家交流学习纠错! dhcpcd项目地址:http://www.linuxfromscratch.org/blfs/view/8.3/basicne ...