Scrapy工作原理
1. Scrapy旧版架构图(绿线是数据流向)
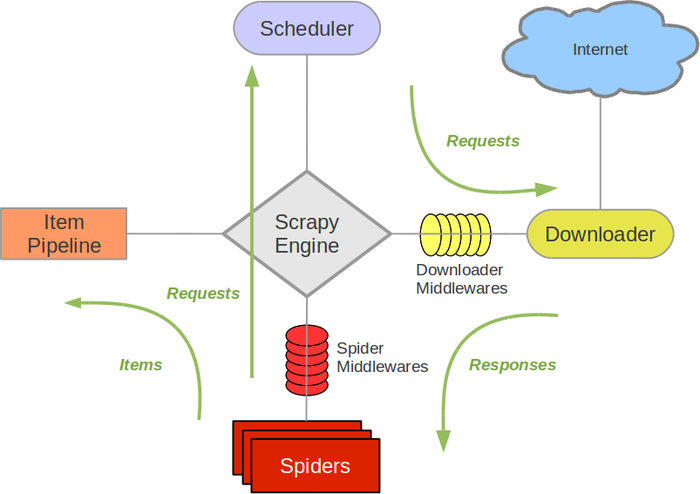
- Spiders(爬虫):负责处理所有Responses,从中分析提取数据,获取Items字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
- Engine(引擎):负责Spider、Item Pipeline、Downloader、Scheduler中间的通讯、信号以及数据传递等。
- Scheduler(调度器):负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列和入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载引擎发送的所有Requests请求,并将其获取到的Responses交还给引擎,由引擎交给Spider来处理。
- Item Pipeline(管道):负责处理Spider中获取到的Items,并进行后期处理(如详细分析、过滤、存储等)。
- Downloader Middlewares(下载中间件):一个可以自定义下载功能的组件。
- Spider Middlewares(Spider中间件):一个可以自定义引擎和Spider交互的组件。
- 通信的功能组件:如进入Spider的Responses和从Spider出去的Requests。
2. Scrapy新版架构图
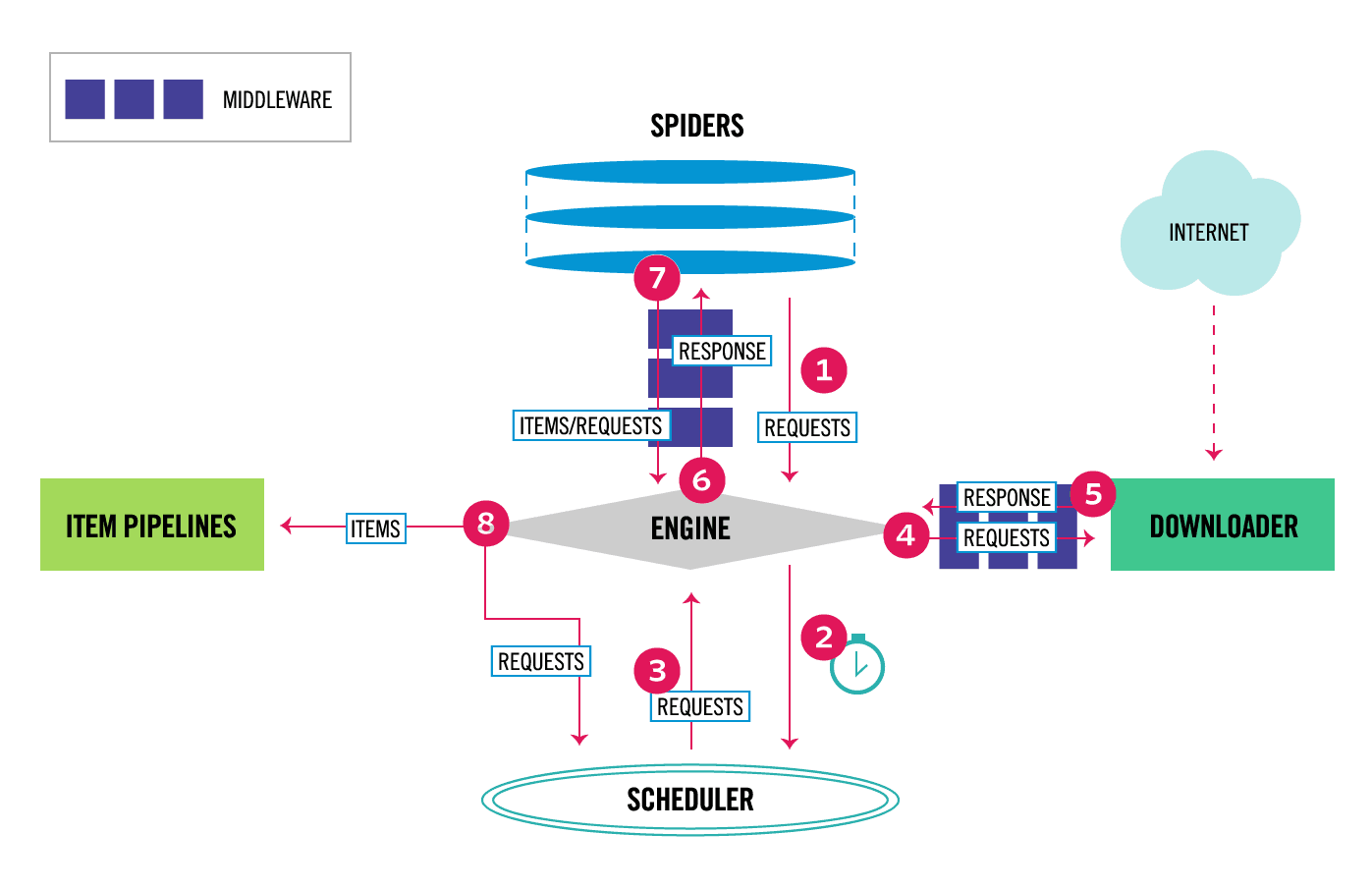
1. 组件介绍
- Scrapy Engine(引擎):引擎负责控制数据流在所有组件中的流动,并在相应动作发生时触发事件。
- Scheduler(调度器):调度器从引擎接受Request并将他们入队,以便之后引擎请求他们时提供给引擎。
- Downloader(下载器):下载器负责获取页面数据并提供给引擎,而后提供给Spiders。
- Spiders(爬虫):Spiders是用户编写用于分析Response并提取items(即获取到的items)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。 更多内容请看 Spiders 。
- Item Pipeline(管道):Item Pipeline负责处理被Spider提取出来的items。典型的处理有清理、 验证及持久化(例如存取到数据库中)。 更多内容查看 Item Pipeline 。
- Downloader Middlewares(下载器中间件):下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的Response(也包括引擎传递给下载器的Request),即处理下载请求。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看Downloader Middleware 。
- Spider middlewares(爬虫中间件):Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理Spider的输入(Response)和输出(Items及Requests),即处理解析。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 Spider Middleware 。
2. 数据流(Data Flow)
- 引擎打开一个网站(open a domain),找到处理该网站的Spiders并向该Spiders请求第一个要爬取的URL(s)。
- 引擎从Spiders中获取到第一个要爬取的URL(s)并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL(s)。
- 调度器返回下一个要爬取的URL(s)给引擎,引擎将URL(s)通过下载中间件(请求(Request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(Response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spiders处理。
- Spiders处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spiders返回的)爬取到的Item推送给Item Pipelines,将(Spiders返回的)Request推送给调度器。
- (从第二步)重复直到调度器中没有更多的Request,引擎关闭该网站。
3. 使用Scrapy框架爬虫的重要命令
创建项目:scrapy startproject xxx (项目名)
进入项目:cd xxx
基本爬虫:scrapy genspider xxx(爬虫名) xxx.com (爬取域)
规则爬虫:scrapy genspider -t crawl xxx(爬虫名) xxx.com (爬取域)
运行命令:scrapy crawl xxx(项目名) -o xxx(项目名).json
4. Middlewares主要方法
1. Spider Middlewares: 处理解析Items的相关逻辑修正,比如数据不完整要添加默认,增加其他额外信息等
- process_spider_input(response, spider):当Response通过spider中间件时,该方法被调用,处理该Response。
- process_spider_output(response, result, spider):当Spider处理Response返回result时,该方法被调用。
- process_spider_exception(response, exception, spider):当spider或(其他spider中间件的) process_spider_input()抛出异常时, 该方法被调用。
2. Downloader Middlewares:处理发出去的请求(Request)和返回结果(Response)的一些回调
- process_request(request, spider):当每个request通过下载中间件时,该方法被调用,这里可以修改UA,代理,Refferer
- process_response(request, response, spider): 这里可以看返回是否是200加入重试机制
- process_exception(request, exception, spider):这里可以处理超时
参考:https://blog.csdn.net/baidu_32542573/article/details/79415947
https://blog.csdn.net/qq_37143745/article/details/80996707
Scrapy工作原理的更多相关文章
- scrapy工作原理探秘
def _next_request_from_scheduler(self, spider):#engine从调度器取得下一个request slot = self.slot request = sl ...
- scrapy工作原理概述
当运行scrapy crawl spider 时,会生成一个crawl命令对象,scrapy是调用execute函数(cmdlin.py)来执行命令的,execute函数会给命令对象添加crawler ...
- 一篇文章教会你理解Scrapy网络爬虫框架的工作原理和数据采集过程
今天小编给大家详细的讲解一下Scrapy爬虫框架,希望对大家的学习有帮助. 1.Scrapy爬虫框架 Scrapy是一个使用Python编程语言编写的爬虫框架,任何人都可以根据自己的需求进行修改,并且 ...
- Scrapy 框架结构及工作原理
1.下图为 Scrapy 框架的组成结构,并从数据流的角度揭示 Scrapy 的工作原理 2.首先.简单了解一下 Scrapy 框架中的各个组件 组 件 描 述 类 型 EN ...
- scrapy框架结构与工作原理
组件: ENGINE:引擎,框架的核心,其他组件在其控制下协同工作. SCHEDULER:调度器,负责对SPIDER提交的下载请求进行调度 DOWNLOADER:下载器,负责下载页面,发送HTTP请求 ...
- Python爬虫-Scrapy框架的工作原理
Scrapy框架工作原理 Scrapy框架架构图 Scrapy框架主要由六大组件组成,分别为: 调度器(Scheduler),下载器(Downler),爬虫(Spiders),中间件(Middwa ...
- scrapy学习笔记(二)框架结构工作原理
scrapy结构图: scrapy组件: ENGINE:引擎,框架的核心,其它所有组件在其控制下协同工作. SCHEDULER:调度器,负责对SPIDER提交的下载请求进行调度. DOWNLOADER ...
- Python 爬虫之 Scrapy 分布式原理以及部署
Scrapy分布式原理 关于Scrapy工作流程 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享 ...
- scrapy分布式原理
scrapy分布式原理 关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键 ...
随机推荐
- CNN卷积核反传分析
CNN(卷积神经网络)的误差反传(error back propagation)中有一个非常关键的的步骤就是将某个卷积(Convolve)层的误差传到前一层的池化(Pool)层上,因为在CNN中是2D ...
- 【转载】史上最全:TensorFlow 好玩的技术、应用和你不知道的黑科技
[导读]TensorFlow 在 2015 年年底一出现就受到了极大的关注,经过一年多的发展,已经成为了在机器学习.深度学习项目中最受欢迎的框架之一.自发布以来,TensorFlow 不断在完善并增加 ...
- [HBase Manual] CH2 Getting Started
Getting Started Getting Started 1. Introduction 2.Quick Start-Strandalone HBase 2.1 JDK版本选择 2.2 Get ...
- windows上RSA密钥生成和使用
一,下载安装windows平台openssl密钥生成工具,执行安装目录bin下的"openssl.exe",执行后弹出命令窗口如下 运行 二,生成私钥 输入"genrsa ...
- jd-gui在Ubuntu上打不开
你在 ubuntu13.10上 安装了最新版本的 jd-gui 但是它跑不起来怎么办? 请执行如下指令: sudo apt-get install libgtk2.0-0:i386 libxxf86v ...
- 阿里java代码检测工具p3c
阿里在杭州云栖大会上,正式发布众所期待的<阿里巴巴Java开发规约>扫描插件! 该插件由阿里巴巴P3C项目组研发.这个项目组是阿里巴巴开发爱好者自发组织形成的虚拟项目组,把<阿里巴巴 ...
- python 序列化模块之 json 和 pickle
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,采用完全独立于语言的文本格式,支持不同程序之间的数据转换.但是只能转换简单的类型如:(列表.字典.字符串. ...
- Transaction rolled back because it has been marked as rollback-only分析解决方法
1. Transaction rolled back because it has been marked as rollback-only事务已回滚,因为它被标记成了只回滚<prop key= ...
- a,abbr,address,area,article, aside, audio标签文档
<a>标签 download属性 <!-- 下载hello.txt --> <a href="test.txt" download="hel ...
- 我的订单页面List
<%@ page language="java" contentType="text/html;charset=UTF-8"%> <%@ ta ...