Scrapy工作原理
1. Scrapy旧版架构图(绿线是数据流向)
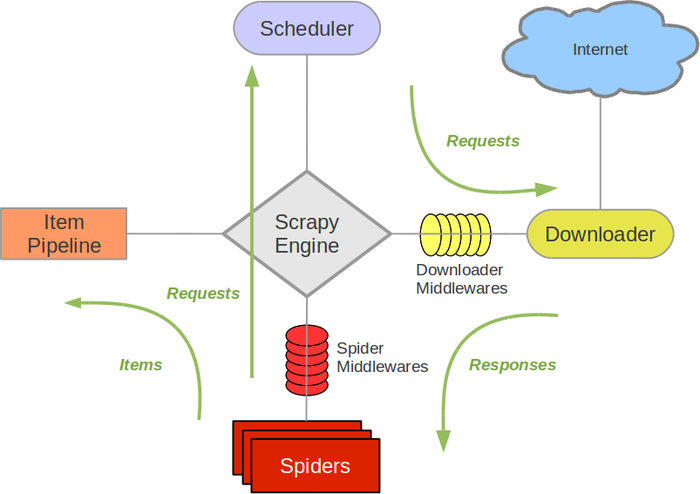
- Spiders(爬虫):负责处理所有Responses,从中分析提取数据,获取Items字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
- Engine(引擎):负责Spider、Item Pipeline、Downloader、Scheduler中间的通讯、信号以及数据传递等。
- Scheduler(调度器):负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列和入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载引擎发送的所有Requests请求,并将其获取到的Responses交还给引擎,由引擎交给Spider来处理。
- Item Pipeline(管道):负责处理Spider中获取到的Items,并进行后期处理(如详细分析、过滤、存储等)。
- Downloader Middlewares(下载中间件):一个可以自定义下载功能的组件。
- Spider Middlewares(Spider中间件):一个可以自定义引擎和Spider交互的组件。
- 通信的功能组件:如进入Spider的Responses和从Spider出去的Requests。
2. Scrapy新版架构图
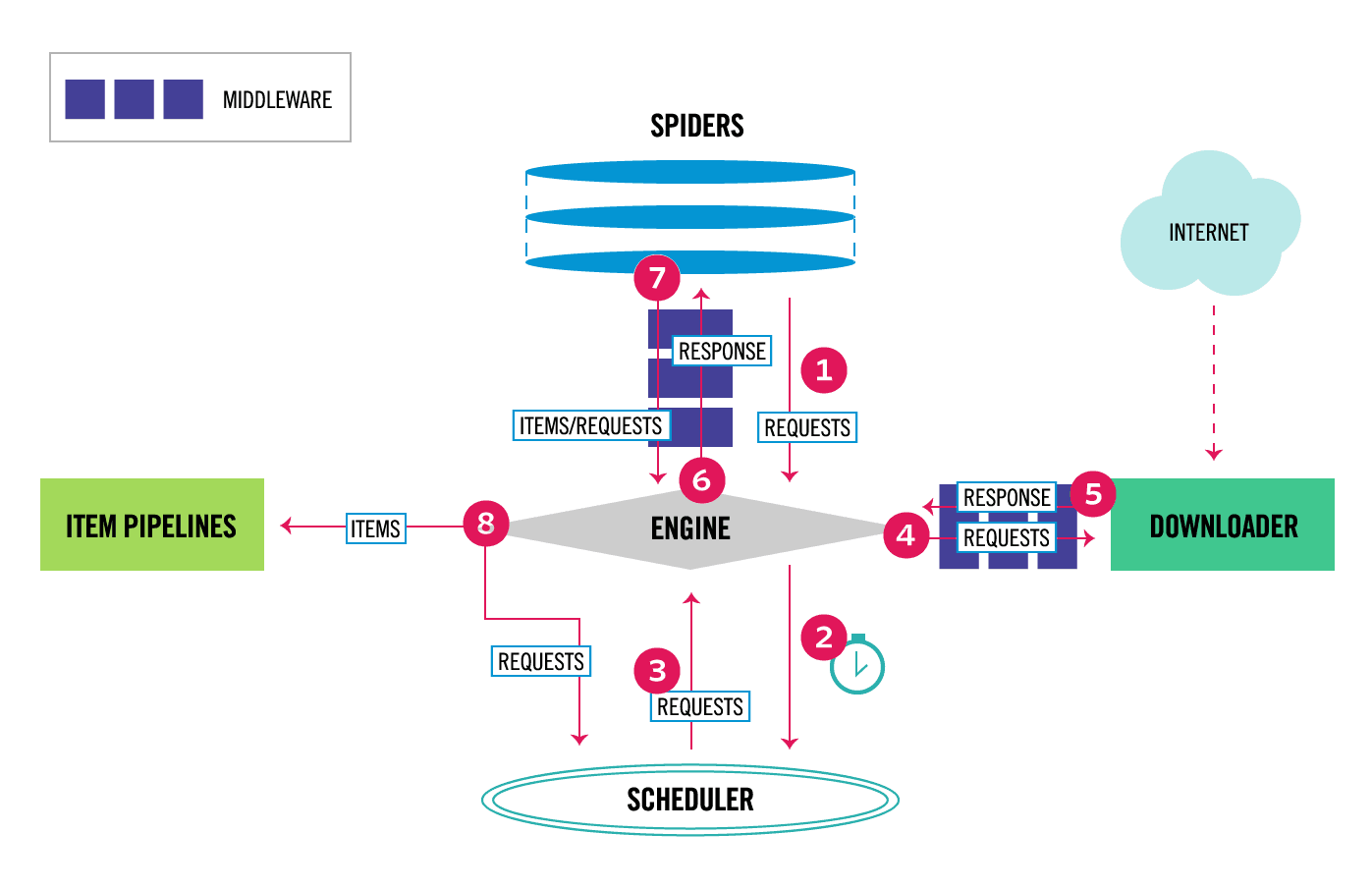
1. 组件介绍
- Scrapy Engine(引擎):引擎负责控制数据流在所有组件中的流动,并在相应动作发生时触发事件。
- Scheduler(调度器):调度器从引擎接受Request并将他们入队,以便之后引擎请求他们时提供给引擎。
- Downloader(下载器):下载器负责获取页面数据并提供给引擎,而后提供给Spiders。
- Spiders(爬虫):Spiders是用户编写用于分析Response并提取items(即获取到的items)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。 更多内容请看 Spiders 。
- Item Pipeline(管道):Item Pipeline负责处理被Spider提取出来的items。典型的处理有清理、 验证及持久化(例如存取到数据库中)。 更多内容查看 Item Pipeline 。
- Downloader Middlewares(下载器中间件):下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的Response(也包括引擎传递给下载器的Request),即处理下载请求。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看Downloader Middleware 。
- Spider middlewares(爬虫中间件):Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理Spider的输入(Response)和输出(Items及Requests),即处理解析。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 Spider Middleware 。
2. 数据流(Data Flow)
- 引擎打开一个网站(open a domain),找到处理该网站的Spiders并向该Spiders请求第一个要爬取的URL(s)。
- 引擎从Spiders中获取到第一个要爬取的URL(s)并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL(s)。
- 调度器返回下一个要爬取的URL(s)给引擎,引擎将URL(s)通过下载中间件(请求(Request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(Response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spiders处理。
- Spiders处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spiders返回的)爬取到的Item推送给Item Pipelines,将(Spiders返回的)Request推送给调度器。
- (从第二步)重复直到调度器中没有更多的Request,引擎关闭该网站。
3. 使用Scrapy框架爬虫的重要命令
创建项目:scrapy startproject xxx (项目名)
进入项目:cd xxx
基本爬虫:scrapy genspider xxx(爬虫名) xxx.com (爬取域)
规则爬虫:scrapy genspider -t crawl xxx(爬虫名) xxx.com (爬取域)
运行命令:scrapy crawl xxx(项目名) -o xxx(项目名).json
4. Middlewares主要方法
1. Spider Middlewares: 处理解析Items的相关逻辑修正,比如数据不完整要添加默认,增加其他额外信息等
- process_spider_input(response, spider):当Response通过spider中间件时,该方法被调用,处理该Response。
- process_spider_output(response, result, spider):当Spider处理Response返回result时,该方法被调用。
- process_spider_exception(response, exception, spider):当spider或(其他spider中间件的) process_spider_input()抛出异常时, 该方法被调用。
2. Downloader Middlewares:处理发出去的请求(Request)和返回结果(Response)的一些回调
- process_request(request, spider):当每个request通过下载中间件时,该方法被调用,这里可以修改UA,代理,Refferer
- process_response(request, response, spider): 这里可以看返回是否是200加入重试机制
- process_exception(request, exception, spider):这里可以处理超时
参考:https://blog.csdn.net/baidu_32542573/article/details/79415947
https://blog.csdn.net/qq_37143745/article/details/80996707
Scrapy工作原理的更多相关文章
- scrapy工作原理探秘
def _next_request_from_scheduler(self, spider):#engine从调度器取得下一个request slot = self.slot request = sl ...
- scrapy工作原理概述
当运行scrapy crawl spider 时,会生成一个crawl命令对象,scrapy是调用execute函数(cmdlin.py)来执行命令的,execute函数会给命令对象添加crawler ...
- 一篇文章教会你理解Scrapy网络爬虫框架的工作原理和数据采集过程
今天小编给大家详细的讲解一下Scrapy爬虫框架,希望对大家的学习有帮助. 1.Scrapy爬虫框架 Scrapy是一个使用Python编程语言编写的爬虫框架,任何人都可以根据自己的需求进行修改,并且 ...
- Scrapy 框架结构及工作原理
1.下图为 Scrapy 框架的组成结构,并从数据流的角度揭示 Scrapy 的工作原理 2.首先.简单了解一下 Scrapy 框架中的各个组件 组 件 描 述 类 型 EN ...
- scrapy框架结构与工作原理
组件: ENGINE:引擎,框架的核心,其他组件在其控制下协同工作. SCHEDULER:调度器,负责对SPIDER提交的下载请求进行调度 DOWNLOADER:下载器,负责下载页面,发送HTTP请求 ...
- Python爬虫-Scrapy框架的工作原理
Scrapy框架工作原理 Scrapy框架架构图 Scrapy框架主要由六大组件组成,分别为: 调度器(Scheduler),下载器(Downler),爬虫(Spiders),中间件(Middwa ...
- scrapy学习笔记(二)框架结构工作原理
scrapy结构图: scrapy组件: ENGINE:引擎,框架的核心,其它所有组件在其控制下协同工作. SCHEDULER:调度器,负责对SPIDER提交的下载请求进行调度. DOWNLOADER ...
- Python 爬虫之 Scrapy 分布式原理以及部署
Scrapy分布式原理 关于Scrapy工作流程 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享 ...
- scrapy分布式原理
scrapy分布式原理 关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键 ...
随机推荐
- 【iCore4 双核心板_ARM】例程三十四:U_DISK_IAP_ARM实验——更新升级STM32
实验现象及操作说明: 1.本例程共有两个代码包,APP和IAP,IAP程序功能实现将APP程序升级至STM32中. 2.直接上电或烧写程序将执行升级的APP应用程序. 3.按下按键上电或写程序将进行升 ...
- [转]理解Go语言中的nil
最近在油管上面看了一个视频:Understanding nil,挺有意思,这篇文章就对视频做一个归纳总结,代码示例都是来自于视频. nil是什么 相信写过Golang的程序员对下面一段代码是非常非常熟 ...
- TextView 链接显示及跳转
当文字中出现URL.E-mail.电话号码等的时候,我们为TextView设置链接.总结起来,一共有4种方法来为TextView实现链接.我们一一举例介绍: 1. 在xml里添加android:aut ...
- iview表单验证不生效问题注意点
按照iview官网介绍写的form表单验证,但是无论填写与否都不进行校验,找了很久的原因,突然才发现一个关键的地方,一定要加props!!! https://blog.csdn.net/xuaner8 ...
- 库存秒杀问题-redis解决方案- 接口限流
<?php/** * Created by PhpStorm. * redis 销量超卖秒杀解决方案 * redis 文档:http://doc.redisfans.com/ * ab -n 1 ...
- CentOS 6.8 防火墙配置
系统: CentOS release 6.8 (Final) iptables v1.4.7 执行命令: #清除所有规则 iptables -F #开放redis端口 iptables -A INPU ...
- [BTS] BizTalk EDI character set and separator settings
最近一个项目上遇到需要对EDI头.分隔符.小数点等配置项进行设置. 这里只记录一下结果,原理不记了,多看MSDN. UNB1中的信息在BizTalk中是不会体现在EDI输出文件中的,双方协商好即可. ...
- springboot2.X访问静态文件配置
config配置: @Configuration public class WebMvcConfig implements WebMvcConfigurer { /** * 跨域配置 * @retur ...
- 使用nginx运行thinkphp的nginx配置
location / { index index.php; #如果文件不存在则尝试TP解析 if (!-e $request_filename) { rewrite ^(.*)$ /index.php ...
- java基础---->Java的格式化输出
在JavaSe5中,推出了C语言中printf()风格的格式化输出.这不仅使得控制输出的代码更加简单,同时也给与Java开发者对于输出格式与排列更大的控制能力.今天,我们开始学习Java中的格式化输出 ...