开源通用爬虫框架YayCrawler-页面的抽取规则定义
本节我将向大家介绍一下YayCrawler的核心-页面的抽取规则定义,这也是YayCrawler能够做到通用的主要原因之一。如果我要爬去不同的网站的数据,尽管他们的网站采用的开发技术不同、页面的结构不同,但是我只要针对不同的网站定义不同的抽取规则即可,不用再对每个网站专门开发一个爬虫。
首先让我来解释几个概念:
一、页面(Page)
这里说的页面不是指在浏览器上能直接看到的页面,而是指一个http请求发送后服务端返回的response中的内容。它大多数情况是一个html文档,也可能是一个Json字符串,甚至是自定义的字符串和二进制等。
二、区域(Region)
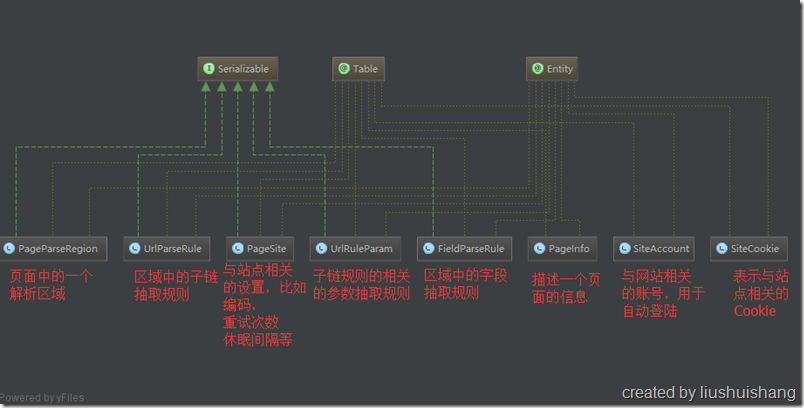
页面上的一个或多个感兴趣的代码片段,比如某些div,某个表格,包含某个class的dom元素,Json数据中的某个节点,甚至某一段字符串。区域是规则解析的单元,一个Page可以有多个Region,每个Region在执行规则解析后会产生两类数据:字段数据和子链接。字段数据会被持久化到数据库,子链接会发送给Master加入待执行队列。
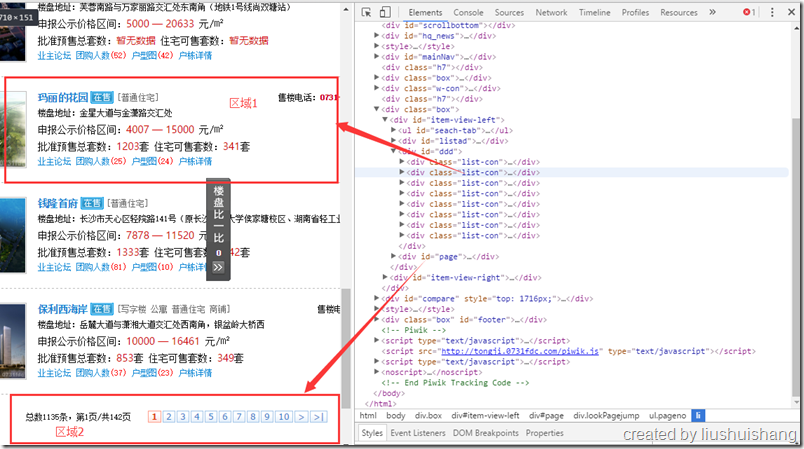
上图中,我如果用css选择器选取class为list-con的元素会选择到多个div,我们认为这就是一个类型的区域,叫做区域1;如果我用css选择器选择id为page的元素会选择到分页控件所在的div,我们认为这是区域2。
对于区域1,我可以通过xpath或者正则表达式来抽取楼盘地址、申报公示价格区间等字段数据,我也可以抽取“户栋详情”这个链接加入到任务队列中。
对于区域2,我并不关心它的字段数据,我只关心下一页的链接是什么,因此我只要配置一个子链接规则把下一页的链接抽取出来即可。
三、解析规则
我们的解析是以区域(Region)为单位的(您可以把整个Page当成一个Region),前面说过一个Region解析完成后会产生两类数据:字段数据和子链接。因此我们框架中存在两种规则:字段规则和链接规则。字段规则描述的是如何从Region片段中抽取所需的字段数据;链接规则则描述的是如何从Region片段中抽取子链接。举例说明:
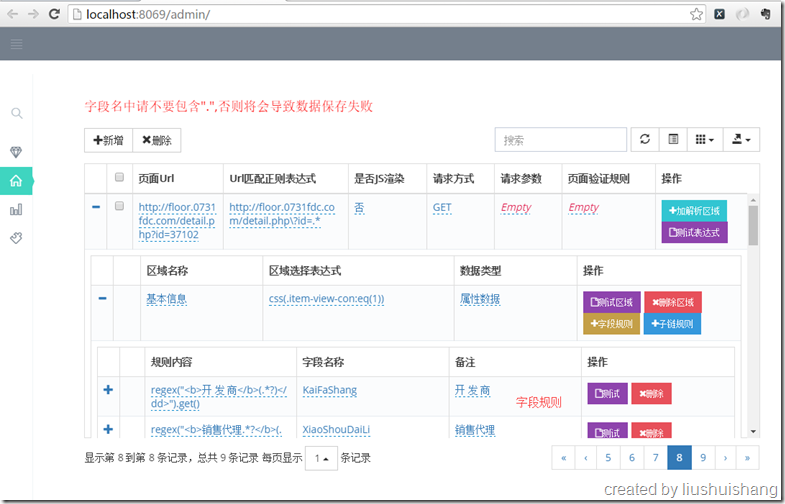
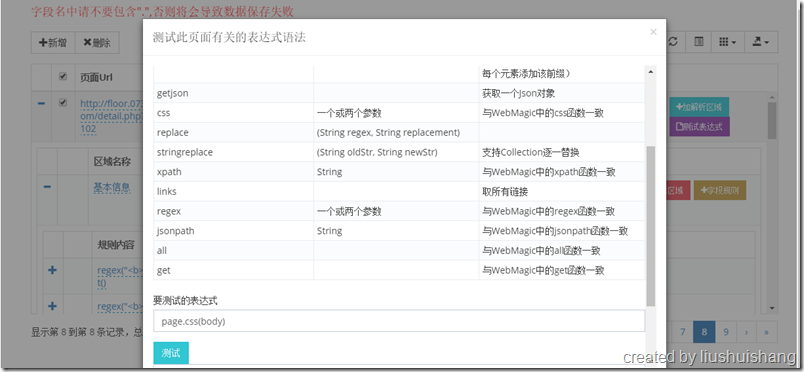
上图中我们针对基本信息这个区域设定了几个字段抽取规则,我们来看看测试结果:

开源通用爬虫框架YayCrawler-页面的抽取规则定义的更多相关文章
- 开源通用爬虫框架YayCrawler-开篇
各位好!从今天起,我将用几个篇幅的文字向大家介绍一下我的一个开源作品--YayCrawler,其在GitHub上的网址是:https://github.com/liushuishang/YayCraw ...
- 开源通用爬虫框架YayCrawler-运行与调试
本节我将向大家介绍如何运行与调试YayCrawler.该框架是采用SpringBoot开发的,所以可以通过java –jar xxxx.jar的方式运行,也可以部署在tomcat等容器中运行. 首先 ...
- 开源通用爬虫框架YayCrawler-框架的运行机制
这一节我将向大家介绍一下YayCrawler的运行机制,首先允许我上一张图: 首先各个组件的启动顺序建议是Master.Worker.Admin,其实不按这个顺序也没关系,我们为了讲解方便假定是这个启 ...
- 爬虫框架YayCrawler
爬虫框架YayCrawler 各位好!从今天起,我将用几个篇幅的文字向大家介绍一下我的一个开源作品——YayCrawler,其在GitHub上的网址是:https://github.com/liush ...
- 一个简单的开源PHP爬虫框架『Phpfetcher』
这篇文章首发在吹水小镇:http://blog.reetsee.com/archives/366 要在手机或者电脑看到更好的图片或代码欢迎到博文原地址.也欢迎到博文原地址批评指正. 转载请注明: 吹水 ...
- 基于 Java 的开源网络爬虫框架 WebCollector
原文:https://www.oschina.net/p/webcollector
- [开源 .NET 跨平台 数据采集 爬虫框架: DotnetSpider] [一] 初衷与架构设计
[DotnetSpider 系列目录] 一.初衷与架构设计 二.基本使用 三.配置式爬虫 四.JSON数据解析与配置系统 为什么要造轮子 同学们可以去各大招聘网站查看一下爬虫工程师的要求,大多是招JA ...
- [开源 .NET 跨平台 Crawler 数据采集 爬虫框架: DotnetSpider] [一] 初衷与架构设计
[DotnetSpider 系列目录] 一.初衷与架构设计 二.基本使用 三.配置式爬虫 四.JSON数据解析与配置系统 五.如何做全站采集 为什么要造轮子 同学们可以去各大招聘网站查看一下爬虫工程师 ...
- Scrapy爬虫框架第一讲(Linux环境)
1.What is Scrapy? 答:Scrapy是一个使用python语言(基于Twistec框架)编写的开源网络爬虫框架,其结构清晰.模块之间的耦合程度低,具有较强的扩张性,能满足各种需求.(前 ...
随机推荐
- WebService Client Generation Error with JDK8
java.lang.AssertionError: org.xml.sax.SAXParseException; systemId: jar:file:/path/to/glassfish/modul ...
- OutputStreamWriter与InputStreamReader(转换流)
import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.IOException; import jav ...
- 习题 6 字符串(string)和文本
虽然你已经在程序中写过字符串了,你还没学过它们的用处.在这章习题中我们将使用复杂的字符串来建立一系列的变量,从中你将学到它们的用途.首先我们解释一下字符串是什么 东西. 字符串通常是指你想要展示给别人 ...
- APC | Memcache等缓存key冲突的解决的方法
版权声明:https://github.com/wusuopubupt https://blog.csdn.net/wusuopuBUPT/article/details/24397109 apc.m ...
- UCML 参与者关键 与依赖关联外键
- 转载 WebService 的CXF框架 WS方式Spring开发
WebService 的CXF框架 WS方式Spring开发 1.建项目,导包. 1 <project xmlns="http://maven.apache.org/POM/4.0 ...
- 让sublime text3支持Vue语法高亮显示
文章转自 http://www.cnblogs.com/kongxianghai/p/6732429.html 1.准备语法高亮插件vue-syntax-highlight. 下载地址: https: ...
- 理解Path对路径进行操作的API
阅读目录 一:理解normalize方法 二:理解join方法 三:理解dirname方法 四:理解basename方法 五:理解extname方法 回到顶部 一:理解normalize方法 该方法将 ...
- JAVA 第七周学习总结
20175308 2018-2019-2 <Java程序设计>第七周学习总结 教材学习内容总结 本周学习第八章:常用实用类 String类: String类位于java.lang包中,被定 ...
- 看think in java 随笔
java的方法是运行期动态绑定上去的,可以根据自己真正实例化的类来判断调用哪个方法,比如子类重写了父类方法,会调用子类方法. 而利用final关键字可以让方法不能重写,就可以在编译期就绑定,这样就可以 ...