[Spark Core] 在 Spark 集群上运行程序
0. 说明
将 IDEA 下的项目导出为 Jar 包,部署到 Spark 集群上运行。
1. 打包程序
1.0 前提
搭建好 Spark 集群,完成代码的编写。
1.1 修改代码
【添加内容,判断参数的有效性】
// 判断参数的有效性
if (args == null || args.length == 0) {
throw new Exception("需要指定文件路径") ;
}
【注释掉 conf.setMaster("...")】
// 不用写,在提交代码的时候通过 spark-submit --master ... 自动生成
// conf.setMaster("spark://s101:7077")
【将加载文件部分由固定路径改为读取传入的路径参数】
// 1. 加载文件
val rdd1 = sc.textFile(args(0))
【原代码参考】
Spark 实现标签生成 中 Scala 代码部分
【修改过的代码如下】
import java.util
import com.share.util.TagUtil
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD /**
* 标签生成
*/
object TaggenCluster {
def main(args: Array[String]): Unit = {
// 判断参数的有效性
if (args == null || args.length == 0) {
throw new Exception("需要指定文件路径") ;
}
// 创建 spark 配置对象
val conf = new SparkConf()
conf.setAppName("TaggenScalaApp") // 不用写,在提交代码的时候通过 spark-submit --master ... 自动生成
// conf.setMaster("spark://s101:7077") // 创建上下文
val sc = new SparkContext(conf) // 1. 加载文件
val rdd1 = sc.textFile(args(0)) // 2. 解析每行的json数据成为集合
val rdd2: RDD[(String, java.util.List[String])] = rdd1.map(line => {
val arr: Array[String] = line.split("\t")
// 商家id
val busid: String = arr(0)
// json
val json: String = arr(1)
val list: java.util.List[String] = TagUtil.extractTag(json)
Tuple2[String, java.util.List[String]](busid, list)
}) // 3. 过滤空集合 (85766086,[干净卫生, 服务热情, 价格实惠, 味道赞])
val rdd3: RDD[(String, util.List[String])] = rdd2.filter((t: Tuple2[String, java.util.List[String]]) => {
!t._2.isEmpty
}) // 4. 将值压扁 (78477325,味道赞)
val rdd4: RDD[(String, String)] = rdd3.flatMapValues((list: java.util.List[String]) => {
// 导入隐式转换
import scala.collection.JavaConversions._
list
}) // 5. 滤除数字的tag (78477325,菜品不错)
val rdd5 = rdd4.filter((t: Tuple2[String, String]) => {
try {
Integer.parseInt(t._2)
false
} catch {
case _ => true
}
}) // 6. 标1成对 ((70611801,环境优雅),1)
val rdd6: RDD[Tuple2[Tuple2[String, String], Int]] = rdd5.map((t: Tuple2[String, String]) => {
Tuple2[Tuple2[String, String], Int](t, 1)
}) // 7. 聚合 ((78477325,味道赞),8)
val rdd7: RDD[Tuple2[Tuple2[String, String], Int]] = rdd6.reduceByKey((a: Int, b: Int) => {
a + b
}) // 8. 重组 (83073343,List((性价比高,8)))
val rdd8: RDD[Tuple2[String, List[Tuple2[String, Int]]]] = rdd7.map((t: Tuple2[Tuple2[String, String], Int]) => {
Tuple2[String, List[Tuple2[String, Int]]](t._1._1, Tuple2[String, Int](t._1._2, t._2) :: Nil)
}) // 9. reduceByKey (71039150,List((环境优雅,1), (价格实惠,1), (朋友聚会,1), (团建,1), (体验好,1)))
val rdd9: RDD[Tuple2[String, List[Tuple2[String, Int]]]] = rdd8.reduceByKey((a: List[Tuple2[String, Int]], b: List[Tuple2[String, Int]]) => {
a ::: b
}) // 10. 分组内排序 (88496862,List((回头客,5), (服务热情,4), (味道赞,4), (分量足,3), (性价比高,2)))
val rdd10: RDD[Tuple2[String, List[Tuple2[String, Int]]]] = rdd9.mapValues((list: List[Tuple2[String, Int]]) => {
val list2: List[Tuple2[String, Int]] = list.sortBy((t: Tuple2[String, Int]) => {
-t._2
})
list2.take(5)
}) // 11. 商家间排序 (75144086,List((服务热情,38), (效果赞,30), (无办卡,22), (环境优雅,22), (性价比高,21)))
val rdd11: RDD[Tuple2[String, List[Tuple2[String, Int]]]] = rdd10.sortBy((t: Tuple2[String, List[Tuple2[String, Int]]]) => {
t._2(0)._2
}, false) rdd11.collect().foreach(println)
}
}
1.2 导出 Jar 包,并添加依赖的第三方类库
【打开 Project Structure】
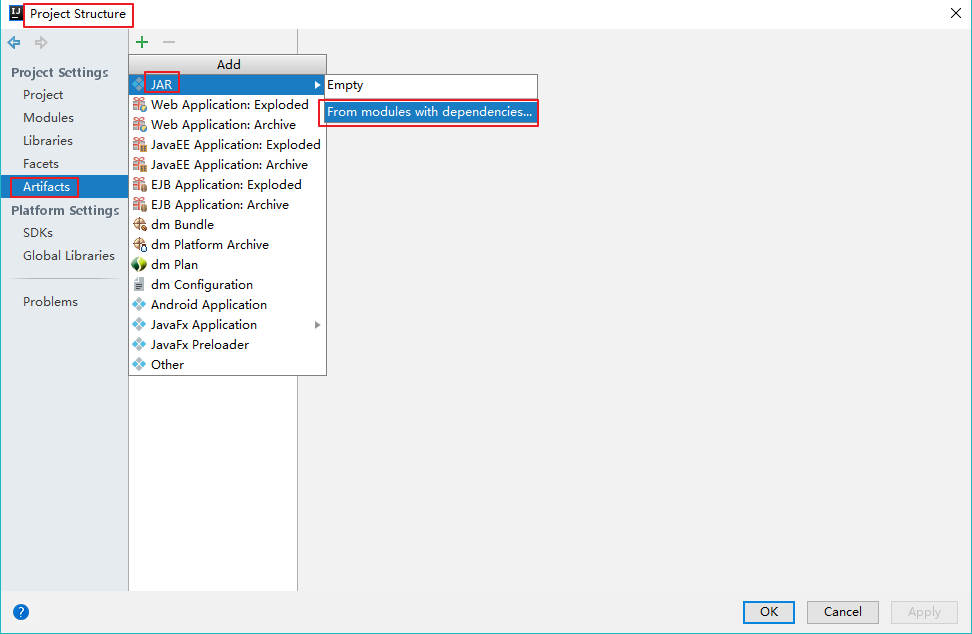
【添加模块】
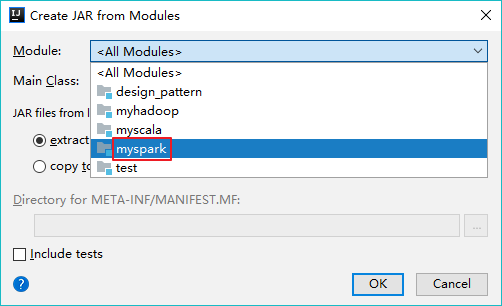
【移除第三方类库】
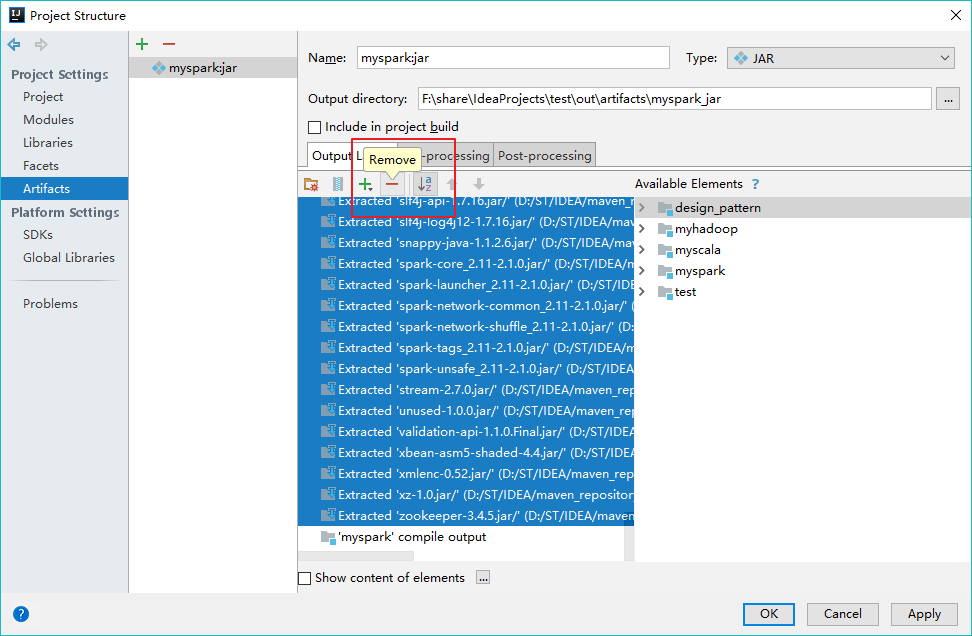
【添加第三方类库 fastjson】
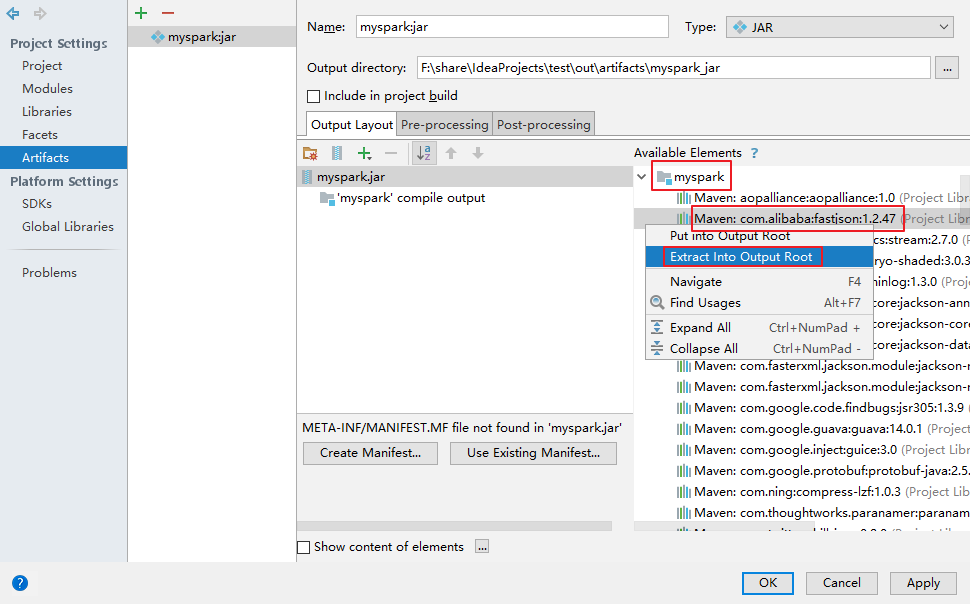
【导入完成】
【构建 Jar 包】
【得到 Jar 包】
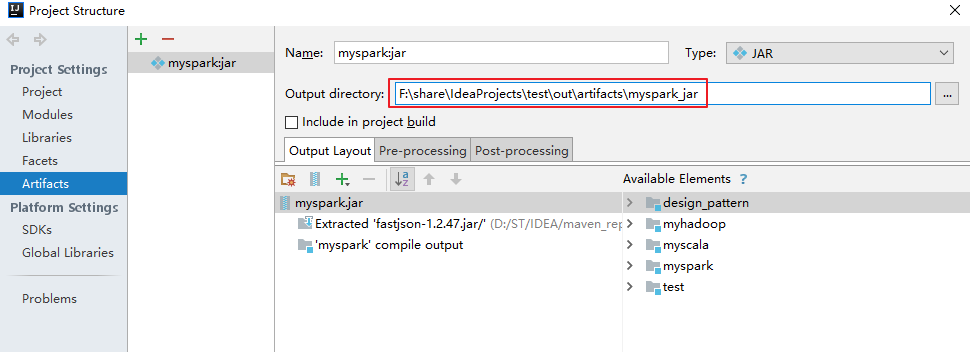

2. 运行程序
2.0 将 Jar 包传输到服务器
通过 Xftp 将 myspark.jar 传到服务器,过程略。
2.1 上传文件到 HDFS 中
hdfs dfs -put temptags.txt /user/centos
2.2 使用 spark-submit 提交应用(Scala)
spark-submit --class com.share.scala.mr.TaggenCluster --master spark://s101:7077 myspark.jar /user/centos/temptags.txt
2.3 使用 spark-submit 提交应用(Java)
spark-submit --class com.share.java.mr.TaggenCluster --master spark://s101:7077 myspark.jar /user/centos/temptags.txt
[Spark Core] 在 Spark 集群上运行程序的更多相关文章
- Spark学习之在集群上运行Spark(6)
Spark学习之在集群上运行Spark(6) 1. Spark的一个优点在于可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力. 2. Spark既能适用于专用集群,也可以适用于共享的云计算 ...
- Spark学习之在集群上运行Spark
一.简介 Spark 的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力.好在编写用于在集群上并行执行的 Spark 应用所使用的 API 跟本地单机模式下的完全一样.也就是说 ...
- Spark学习笔记——在集群上运行Spark
Spark运行的时候,采用的是主从结构,有一个节点负责中央协调, 调度各个分布式工作节点.这个中央协调节点被称为驱动器( Driver) 节点.与之对应的工作节点被称为执行器( executor) 节 ...
- 在local模式下的spark程序打包到集群上运行
一.前期准备 前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客: Hadoop2.0伪分布式平台环境搭建 Spark2.4.0伪分 ...
- spark在集群上运行
1.spark在集群上运行应用的详细过程 (1)用户通过spark-submit脚本提交应用 (2)spark-submit脚本启动驱动器程序,调用用户定义的main()方法 (3)驱动器程序与集群管 ...
- Eclipse提交代码到Spark集群上运行
Spark集群master节点: 192.168.168.200 Eclipse运行windows主机: 192.168.168.100 场景: 为了测试在Eclipse上开发的代码在Spa ...
- 在集群上运行Spark
Spark 可以在各种各样的集群管理器(Hadoop YARN.Apache Mesos,还有Spark 自带的独立集群管理器)上运行,所以Spark 应用既能够适应专用集群,又能用于共享的云计算环境 ...
- 将java开发的wordcount程序提交到spark集群上运行
今天来分享下将java开发的wordcount程序提交到spark集群上运行的步骤. 第一个步骤之前,先上传文本文件,spark.txt,然用命令hadoop fs -put spark.txt /s ...
- 06、部署Spark程序到集群上运行
06.部署Spark程序到集群上运行 6.1 修改程序代码 修改文件加载路径 在spark集群上执行程序时,如果加载文件需要确保路径是所有节点能否访问到的路径,因此通常是hdfs路径地址.所以需要修改 ...
随机推荐
- 《Netty权威指南》目录
一.基础篇 走进Java NIO 1. Java 的 I/O 演进之路:https://www.cnblogs.com/zengzhihua/p/9930652.html 2. NIO 入门:http ...
- 基于Ip的刷投票排名及刷百度推广的自动化实现
所有基于Ip的刷投票排名,只要不涉及用户登录情况,都可以在手机端自动化实现,因为电信运营商的ip地址段是无限的,理论上,飞行模式开关一次,所分配ip地址是变化的,这就有了大量的ip可用 在手机端写个a ...
- mybatis框架下物理分页的实现(整个工程采用的是springmvc、spring、mybatis框架,数据库是mysql数据库)
(一)关于分页拦截器的简单理解 首先,要开发MyBatis的插件需要实现org.apache.ibatis.plugin.Interceptor接口,这个接口将会要求实现几个方法:intercept( ...
- 【C#设计模式-抽象工厂模式】
一.抽象工厂模式的定义: 为创建一组相关或相互依赖的对象提供一个接口,而且无需指定他们的具体类. 二.抽象工厂模式的结构: 抽象工厂模式是所有形态的工厂模式中最为抽象和最具一般性的一种形态.抽象工厂模 ...
- JS DOM操作(三) Window.docunment对象——操作属性
属性:是对象的性质与对象之间关系的统称.HTML中标签可以拥有属性,属性为 HTML 元素提供附加信. 属性总是以名称/值对的形式出现,比如:name="value". 属性值始终 ...
- org.hibernate.HibernateException: Wrong column type
这个问题一般出现在我们使用定长的字符串作为主键(其它字段也可能)的时候,如数据库中的ID为char(16).虽然很多资料上都说不推荐这样做,但实际上我们在做很多小case的时候自己为了方便也顾不得那么 ...
- CentOS 6 安装配置JDK+tomcat环境
1.安装OpenJDK 这里安装的OpenJDK,是开源版本的JDK,我们平时自己电脑上安装的是 Sun JDK(也叫Oracle JDK),OpenJDK可以看作Sun JDK的精简版. 如果想安装 ...
- 聊聊Java内存模型
一.Java内存模型 硬件处理 电脑硬件,我们知道有用于计算的cpu.辅助运算的内存.以及硬盘还有进行数据传输的数据总线.在程序执行中很多都是内存计算,cpu为了更快的进行计算会有高速缓存,最后同步至 ...
- Linux打包、压缩与解压详解
介绍:在Windows下最常见的压缩文件就只有两种,另一个是.rar,它有.gz..tar.gz.tgz.bz2..Z..tar等众多的压缩文件名,本文就来对这些常见的压缩文件进行总结,在具体总结各类 ...
- DouPHP去除Powered by DouPHP版权的方法
DouPHP标题版权修改:打开 include 目录下的 action.class.php 文件,搜索“Powered”找到下面一行代码: $page_title = ($titles ? $titl ...