kafka数据祸福和failover
k

CAP帽子理论。
consistency:一致性 Availability:可用性 partition tolerance:分区容忍型


CA :mysql oracle(抛弃了网络分区)
CP:hbase redis mongodb(抛弃了可用性)
AP:cassandra simpleDB(抛弃了强一致性,采用弱一致性或者最终一致性,不定时一致性)
一致性的方案

master-slave(hadoop)
WNR 读取后还得判断哪个数据是最新的。常用做法(版本号或者时间戳)

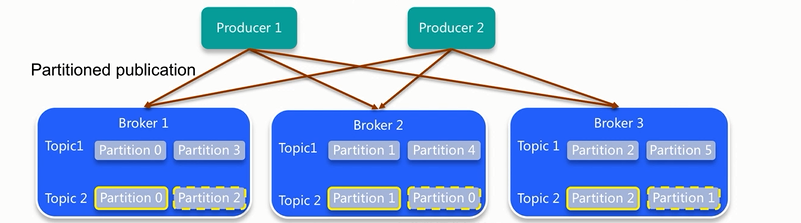

平时读取数据是从leader上读取,follower是为了防止leader宕机进行可用性保证。数据是follower从leader拉取,类似consumer

kafka既不是同步也不是异步机制,而是采用了isr机制。(kafka一旦数据进行commit就必须保证所有的数据都被commit)
一旦发现follower和leader相距的数据过大,就会进行节点移除。差距过大的条件为时间或者条目数:

这是kafka区别与其他系统一个亮点,既不采用同步复制也不采用异步,而且采用了中间的动态控制的设计。
min,insync.replicas是kafka备份的选取,通常是2比较安全一些
request.required.acks
0:这意味着生产者producer不等待来自broker同步完成的确认继续发送下一条(批)消息。此选项提供最低的延迟但最弱的耐久性保证(当服务器发生故障时某些数据会丢失,如leader已死,但producer并不知情,发出去的信息broker就收不到)。
1:这意味着producer在leader已成功收到的数据并得到确认后发送下一条message。此选项提供了更好的耐久性为客户等待服务器确认请求成功(被写入死亡leader但尚未复制将失去了唯一的消息)。
-1:这意味着producer在follower副本确认接收到数据后才算一次发送完成。
此选项提供最好的耐久性,我们保证没有信息将丢失,只要至少一个同步副本保持存活。
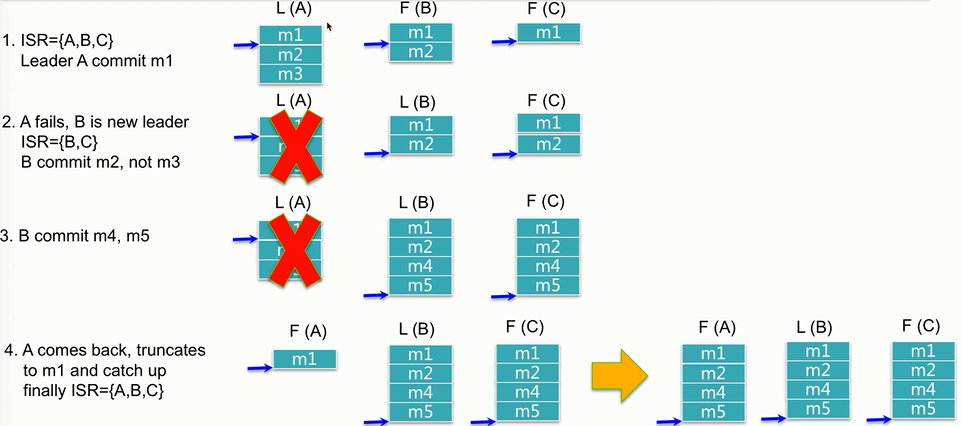
从上图可以看出kafka只有commit的数据才会可以被消费。比如3---4时候M3数据会丢失,因为leader宕机的时候M3从来没被commit过,所以数据在默认retry还没成功就会丢失,但是如果retry成功后会插入M5之后,顺序性也就变了(所以kafka的顺序性是comit顺序而不是发送顺序,而且处理不好也会存在数据丢失的情况),一旦宕机节点恢复就需要check out所有落后数据,直到isr设置的临界点(比如4K条目)才会被加入到ISR列表中。

有选项可以配置全部节点挂掉时候,是恢复isr中的列表,还是全部机器无论在不在ISR中(默认选项)

备份数目不能超过broker数量

默认kafka的replicas和leader都会尽量均匀分配。因为读写都是通过leader所以需要尽量性能均匀些
kafka数据祸福和failover的更多相关文章
- Kafka数据辅助和Failover
数据辅助与Failover CAP理论(它具有一致性.可用性.分区容忍性) CAP理论:分布式系统中,一致性.可用性.分区容忍性最多只可同时满足两个.一般分区容忍性都要求有保障,因此很多时候在可用性与 ...
- Gobblin采集kafka数据
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 找时间记录一下利用Gobblin采集kafka数据的过程,话不多说,进入正题 一.Gobblin ...
- java spark-streaming接收TCP/Kafka数据
本文将展示 1.如何使用spark-streaming接入TCP数据并进行过滤: 2.如何使用spark-streaming接入TCP数据并进行wordcount: 内容如下: 1.使用maven,先 ...
- Flink消费Kafka数据并把实时计算的结果导入到Redis
1. 完成的场景 在很多大数据场景下,要求数据形成数据流的形式进行计算和存储.上篇博客介绍了Flink消费Kafka数据实现Wordcount计算,这篇博客需要完成的是将实时计算的结果写到redis. ...
- 工具篇-Spark-Streaming获取kafka数据的两种方式(转载)
转载自:https://blog.csdn.net/weixin_41615494/article/details/7952173 一.基于Receiver的方式 原理 Receiver从Kafka中 ...
- spark streaming从指定offset处消费Kafka数据
spark streaming从指定offset处消费Kafka数据 -- : 770人阅读 评论() 收藏 举报 分类: spark() 原文地址:http://blog.csdn.net/high ...
- Spark Streaming接收Kafka数据存储到Hbase
Spark Streaming接收Kafka数据存储到Hbase fly spark hbase kafka 主要参考了这篇文章https://yq.aliyun.com/articles/60712 ...
- flume 读取kafka 数据
本文介绍flume读取kafka数据的方法 代码: /************************************************************************* ...
- Kafka数据安全性、运行原理、存储
直接贴面试题: 怎么保证数据 kafka 里的数据安全? 答: 生产者数据的不丢失kafka 的 ack 机制: 在 kafka 发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够 ...
随机推荐
- Java 仓储模式
使用的Spring boot +Jpa 项目层级: common里包含了model,以及一些viewModel等等 下面就是设计的仓储模式 先看下SysUser: @MappedSuperclass ...
- UEditor 编辑模板
读取模板,放到ueditor中进行编辑 @model WeiXin_Shop.Models.WX_GoodsDetails @Html.Partial("_MasterPage") ...
- C#让两个长度相同的数组一一对应
比如: string a[]={"x","y","z"} "} 用字典使其一一对应 Dictionary<string, s ...
- VisualGDB使用随笔
VisualGDB是目前我遇到的在Windows下开发Linux应用程序最好用的软件,它不仅可以直接在VS环境中编译Linux程序,还可以直接对Linux程序进行调试,极大的方便了Windows程序员 ...
- 廖雪峰Java16函数式编程-2Stream-2创建Stream
1. 方法1:把一个现有的序列变为Stream,它的元素是固定的 //1.直接通过Stream.of()静态方法传入可变参数进行创建 Stream<Integer> s = Stream. ...
- String 详解
String String对象不可变,当对象创建完毕之后,如果内容改变则会创建一个新的String对象,返回到原地址中. 不可变优点: 多线程安全. 节省空间,提高效率. 源码: public fin ...
- 巧用CSS3的calc()宽度计算做响应模式布局
今天浏览这个http://www.sitepoint.com站时,因为好奇看了下人家写的代码,结果发现了这行代码, 于是就研究了一下,calc()从字面我们可以把他理解为一个函数function.其实 ...
- Activity详解三 启动activity并返回结果 转载 https://www.cnblogs.com/androidWuYou/p/5886991.html
首先看演示: 1 简介 .如果想在Activity中得到新打开Activity 关闭后返回的数据,需要使用系统提供的startActivityForResult(Intent intent, int ...
- day22_5-xml模块
# 参考资料:# python模块(转自Yuan先生) - 狂奔__蜗牛 - 博客园# https://www.cnblogs.com/guojintao/articles/9070485.html ...
- clipboard.js操作剪贴版——一些移动端交互和兼容经验
https://github.com/zenorocha/clipboard.js 库,真的是个好库,而且不依赖flash,几乎完美支持移动端.但是,移动端应用有些不趟不知的小tip,这里归档下. 原 ...