全文检索Lucene框架---查询索引
一、 Lucene索引库查询
对要搜索的信息创建Query查询对象,Lucene会根据Query查询对象生成最终的查询语法,类似关系数据库Sql语法一样Lucene也有自己的查询语法,比如:“name:lucene”表示查询Field的name为“lucene”的文档信息。
可通过两种方法创建查询对象:
1)使用Lucene提供Query子类
2)使用QueryParse解析查询表达式
二、 TermQuery
TermQuery,通过项查询,TermQuery不使用分析器所以建议匹配不分词的Field域查询,比如订单号、分类ID号等。
指定要查询的域和要查询的关键词。
1、代码实现
package com.zn; import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.jupiter.api.Test; import java.io.File;
import java.io.IOException; /**
* 查询索引
*/
public class QueryTest { /**
* 根据域或关键词进行搜索
*/
@Test
public void termQuery() throws IOException {
Directory directory= FSDirectory.open(new File("E:\\accp\\Y2\\进阶内容\\Lucene\\Lucene\\Index").toPath());
IndexReader indexReader= DirectoryReader.open(directory);
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
//创建查询条件
Query query=new TermQuery(new Term("fieldName","spring"));
//执行查询
TopDocs topDocs=indexSearcher.search(query,10);
System.out.println("返回的文档个数:"+topDocs.totalHits); //获取到文档集合
ScoreDoc [] scoreDocs=topDocs.scoreDocs;
for (ScoreDoc doc:scoreDocs) {
//获取到文档
Document document = indexSearcher.doc(doc.doc);
//获取到文档域中数据
System.out.println("fieldName:"+document.get("fieldName"));
System.out.println("fieldPath:"+document.get("fieldPath"));
System.out.println("fieldSize:"+document.get("fieldSize"));
System.out.println("fieldContent:"+document.get("fieldContent"));
System.out.println("==============================================================");
}
//关闭
indexReader.close();
}
}
2、查询效果
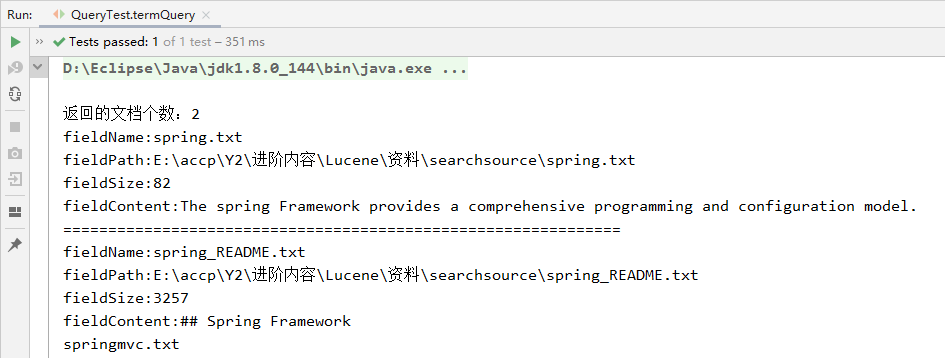
三、 RangeQuery数值查询
1、代码实现
package com.zn; import org.apache.lucene.document.Document;
import org.apache.lucene.document.LongPoint;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.jupiter.api.Test; import java.io.File;
import java.io.IOException; /**
* 查询索引
*/
public class QueryTest { /**
* RangeQuery:范围搜索
*/
@Test
public void rangeQuery() throws IOException {
Directory directory= FSDirectory.open(new File("E:\\accp\\Y2\\进阶内容\\Lucene\\Lucene\\Index").toPath());
IndexReader indexReader= DirectoryReader.open(directory);
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
//创建查询条件
//设置范围搜索的条件 参数一范围所在的域
Query query= LongPoint.newRangeQuery("fieldSize",0,50);
//查询
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("返回的文档个数:"+topDocs.totalHits); //获取到文档集合
ScoreDoc [] scoreDocs=topDocs.scoreDocs;
for (ScoreDoc doc:scoreDocs) {
//获取到文档
Document document = indexSearcher.doc(doc.doc);
//获取到文档域中数据
System.out.println("fieldName:"+document.get("fieldName"));
System.out.println("fieldPath:"+document.get("fieldPath"));
System.out.println("fieldSize:"+document.get("fieldSize"));
System.out.println("fieldContent:"+document.get("fieldContent"));
System.out.println("==============================================================");
} //关闭
indexReader.close();
} }
2、查询效果
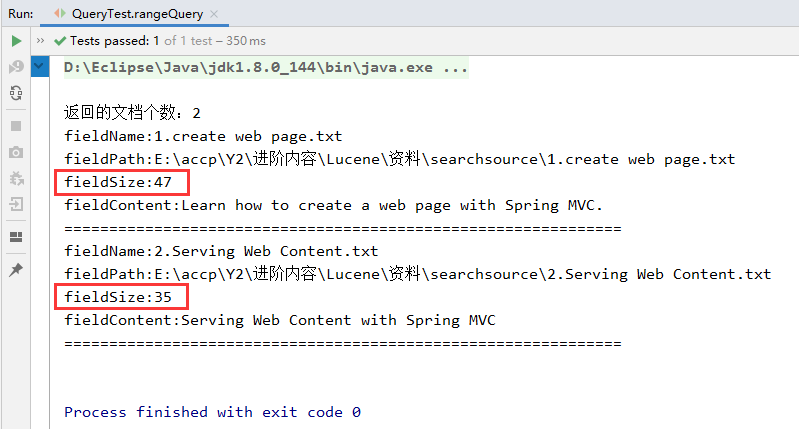
四、 QueryParser
通过QueryParser也可以创建Query,QueryParser提供一个Parse方法,此方法可以直接根据查询语法来查询。Query对象执行的查询语法可通过System.out.println(query);查询。
需要使用到分析器。建议创建索引时使用的分析器和查询索引时使用的分析器要一致。
需要加入queryParser依赖的jar包。
1、导入依赖
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-queryparser -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>7.4.0</version>
</dependency>
2、代码实现
package com.zn; import org.apache.lucene.document.Document;
import org.apache.lucene.document.LongPoint;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.jupiter.api.Test;
import org.wltea.analyzer.lucene.IKAnalyzer; import java.io.File;
import java.io.IOException; /**
* 查询索引
*/
public class QueryTest { /**
* QueryParser:将搜索条件分词
*/
@Test
public void queryParser() throws IOException, ParseException {
Directory directory= FSDirectory.open(new File("E:\\accp\\Y2\\进阶内容\\Lucene\\Lucene\\Index").toPath());
IndexReader indexReader= DirectoryReader.open(directory);
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
//创建QueryParser对象 参数一范围所在的域 参数二:使用哪种分析器
QueryParser parser=new QueryParser("fieldContent",new IKAnalyzer());
//设置匹配的数据条件
Query query = parser.parse("新添加的文档的内容");
//查询
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("返回的文档个数:"+topDocs.totalHits); //获取到文档集合
ScoreDoc [] scoreDocs=topDocs.scoreDocs;
for (ScoreDoc doc:scoreDocs) {
//获取到文档
Document document = indexSearcher.doc(doc.doc);
//获取到文档域中数据
System.out.println("fieldName:"+document.get("fieldName"));
System.out.println("fieldPath:"+document.get("fieldPath"));
System.out.println("fieldSize:"+document.get("fieldSize"));
System.out.println("fieldContent:"+document.get("fieldContent"));
System.out.println("==============================================================");
} //关闭
indexReader.close();
} }
3、效果展示

全文检索Lucene框架---查询索引的更多相关文章
- Lucene之查询索引
Query子类 TermQuery:根据域和关键词进行搜索 /** * termQuery根据域和关键词进行搜索 */ @Test public void termQuery() throws IOE ...
- lucene入门查询索引——(三)
1.用户接口(lucene不提供)
- 搜索引擎学习(三)Lucene查询索引
一.查询理论 创建查询:构建一个包含了文档域和语汇单元的文档查询对象.(例:fileName:lucene) 查询过程:根据查询对象的条件,在索引中找出相应的term,然后根据term找到对应的文档i ...
- lucene查询索引库、分页、过滤、排序、高亮
2.查询索引库 插入测试数据 xx.xx. index. ArticleIndex @Test public void testCreateIndexBatch() throws Exception{ ...
- lucene&solr学习——创建和查询索引(代码篇)
1. Lucene的下载 Lucene是开发全文检索功能的工具包,从官网下载Lucene4.10.3并解压. 官网:http://lucene.apache.org/ 版本:lucene7.7.0 ( ...
- lucene&solr学习——创建和查询索引(理论)
1.Lucene基础 (1) 简介 Lucene是apache下的一个开放源代码的全文检索引擎工具包.提供完整的查询引擎和索引引擎:部分文本分析引擎. Lucene的目的是为软件开发人员提供一个简单易 ...
- Lucene查询索引(分页)
分页查询只需传入每页显示记录数和当前页就可以实现分页查询功能 Lucene分页查询是对搜索返回的结果进行分页,而不是对搜索结果的总数量进行分页,因此我们搜索的时候都是返回前n条记录 package c ...
- Lucene查询索引
索引创建 以新闻文档为例,每条新闻是一个document,新闻有news_id.news_title.news_source.news_url.news_abstract.news_keywords这 ...
- 学习笔记CB011:lucene搜索引擎库、IKAnalyzer中文切词工具、检索服务、查询索引、导流、word2vec
影视剧字幕聊天语料库特点,把影视剧说话内容一句一句以回车换行罗列三千多万条中国话,相邻第二句很可能是第一句最好回答.一个问句有很多种回答,可以根据相关程度以及历史聊天记录所有回答排序,找到最优,是一个 ...
随机推荐
- ThinkPad全家族机型对比
如图所示
- 如何学习理解Redux Middleware
Redux中的middleware其实就像是给你提供一个在action发出到实际reducer执行之前处理一些事情的机会.可以允许我们添加自己的逻辑在这段当中.它提供的是位于 action 被发起之后 ...
- 【java面试】网络通信篇
1.说一下HTTP协议 HTTP协议是超文本传输协议,属于应用层协议,规定了客户端与服务端传输数据的格式:它是无状态的,对于前面传送过的信息没有记录:请求方式有GET,POST,HEAD,PUT,DE ...
- Ubuntu16手动安装OpenStack
记录大佬的博客全文转载于https://www.voidking.com/dev-ubuntu16-manual-openstack-env/ 前言 <Ubuntu16安装OpenStack&g ...
- Apache Hudi 0.5.1版本重磅发布
历经大约3个月时间,Apache Hudi 社区终于发布了0.5.1版本,这是Apache Hudi发布的第二个Apache版本,该版本中一些关键点如下 版本升级 将Spark版本从2.1.0升级到2 ...
- Mybatis基础(一)
mybatis概述: MyBatis 是一款优秀的持久层框架,它支持定制化 SQL.存储过程以及高级映射.MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集.MyBatis ...
- 图解kubernetes调度器SchedulerExtender扩展
在kubernetes的scheduler调度器的设计中为用户预留了两种扩展机制SchdulerExtender与Framework,本文主要浅谈一下SchdulerExtender的实现, 因为还有 ...
- Django 2.2
Django 2.2 LTS 发布,长期支持版来了 django中文网:https://www.django.cn/course/course-3.html Django 2.2 已正式发布,这是一个 ...
- Integer梳理
Integer常量池 问题1 public class Main_1 { public static void main(String[] args) { Integer a = 1; Integer ...
- js----UTC时间于本地时间相差8小时问题
js----UTC时间于本地时间相差8小时问题 js获取周几有两个方法getDay() getUTCDay(),但是它们是有区别的,前者返回的本地时间,后者返回的UTC时间,一般情况下,两者相差8个小 ...