crawlspider爬虫:定义url规则
spider爬虫,适合meta传参的爬虫(列表页,详情页都有数据要爬取的时候)
crawlspider爬虫,适合不用meta传参的爬虫
scrapy genspider -t crawl it it.com
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from Sun.items import SunItem class DongguanSpider(CrawlSpider):
name = 'dongguan'
# 修改允许的域
allowed_domains = ['sun0769.com']
# 修改起始的url
start_urls = ['http://wz.sun0769.com/index.php/question/questionType?type=4'] rules = (
# 构建列表url的提取规则
Rule(LinkExtractor(allow=r'questionType'), follow=True),
# 构建详情页面url提取规则
# 'html/question/201711/352271.shtml'
Rule(LinkExtractor(allow=r'html/question/\d+/\d+.shtml'), callback='parse_item'),
) def parse_item(self, response):
# print (response.url,'--------') # 构建item实例
item = SunItem() # 抽取数据,将数据存放到item中
item['number'] = response.xpath('/html/body/div[6]/div/div[1]/div[1]/strong/text()').extract()[0].split(':')[-1].strip()
item['title'] = response.xpath('/html/body/div[6]/div/div[1]/div[1]/strong/text()').extract()[0].split(':')[-1].split(' ')[0]
item['link'] = response.url
data = ''.join(response.xpath('//div[@class="c1 text14_2"]/text()|//div[@class="contentext"]/text()').extract())
item['content'] = data.replace('\xa0','')
# print(item)
# 返回数据
yield item

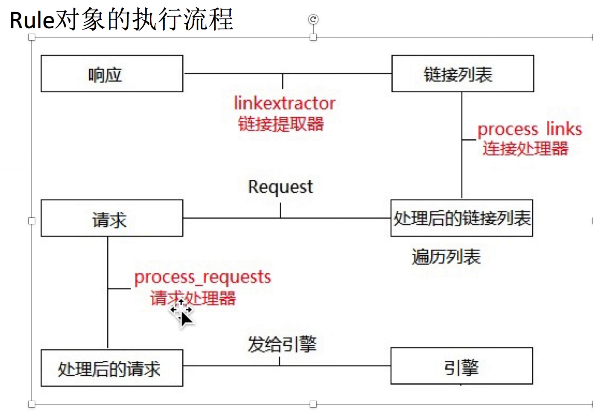
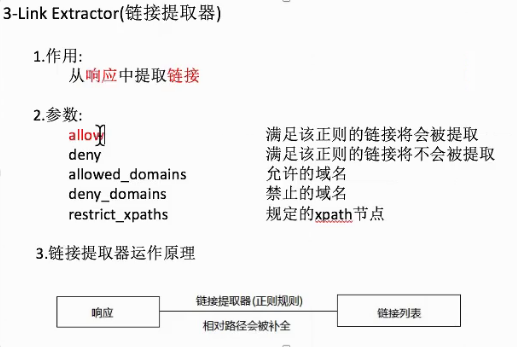
链接提取器的使用
scrapy shell http://hr.tencent.com/position.php
>>> from scrapy.linkextractors import LinkExtractor
>>> le = LinkExtractor(allow=('position_detail.php\?id=\d+&keywords=&tid=0&lid=0'))
或者直接 le = LinkExtractor(allow=('position_detail.php')) 也可以
>>> links=le.extract_links(response)
>>> for link in links:
... print(link)
...
>>> for link in links:
... print(link.url)
...


crawlspider爬虫:定义url规则的更多相关文章
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- Django学习(四) Django提供的后台管理系统以及如何定义URL路由
一旦你建立了模型Models,那么Django就可以为你创建一个专业的,可以提供给生成用的后台管理站点.这个站点可以提供给有权限的人进行已有模型Models数据的增删改查. 将新建的模型Models是 ...
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
- scrapy 中crawlspider 爬虫
爬取目标网站: http://www.chinanews.com/rss/rss_2.html 获取url后进入另一个页面进行数据提取 检查网页: 爬虫该页数据的逻辑: Crawlspider爬虫类: ...
- 《玩转Django2.0》读书笔记-编写URL规则
<玩转Django2.0>读书笔记-编写URL规则 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. URL(Uniform Resource Locator,统一资源定位 ...
- Scrapy - CrawlSpider爬虫
crawlSpider 爬虫 思路: 从response中提取满足某个条件的url地址,发送给引擎,同时能够指定callback函数. 1. 创建项目 scrapy startproject mysp ...
- 创建CrawlSpider爬虫简要步骤
创建CrawlSpider爬虫简要步骤: 1. 创建项目文件: e.g: scrapy startproject douyu (douyu为项目名自定义) 2. 进入项目文件: e.g: cd dou ...
- dt框架自定义url规则
destoon的列表的地址规则是定义在/api/url.inc.php,然后又是在include/global.func.php中进行的listpages这个函数调用实现 if($page < ...
- PHPCMS V9静态化HTML生成设置及URL规则优化
先讲讲Phpcms V9在后台怎么设置生成静态化HTML,之后再讲解怎么自定义URL规则,进行URL地址优化.在这一篇中,伪静态就不涉及了,大家可以移步到Phpcms V9全站伪静态设置方法. 一.静 ...
随机推荐
- JLINK与JTAG的区别(转)
调试ARM,要遵循ARM的调试接口协议,JTAG就是其中的一种.当仿真时,IAR.KEIL.ADS等都有一个公共的调试接口,RDI就是其中的一种,那么我们如何完成RDI-->ARM调试协议(JT ...
- iOS9下App Store新应用提审攻略
博文转载 CocoaChina 文/文公子 公子在第十讲中提到应用更新时需要注意的细节和苹果便捷通道的利用.今天,公子将进一步深扒iTunes Connect的面纱,为大家呈现新应用在提审前需要准备的 ...
- Get方法和post方法有何不同?
Get方法和post方法有何不同? 在B/S应用程序中,前台与后台的数据交互,都是通过HTML中Form表单完成的.Form提供了两种数据传输的方式——get和post.虽然它们都 是数据的提交方式, ...
- 【基础】java类的各种成员初始化顺序
父子类继承时的静态代码块,普通代码块,静态方法,构造方法,等先后顺序 前言: 普通代码块:在方法或语句中出现的{}就称为普通代码块.普通代码块和一般的语句执行顺序由他们在代码中出现的次序决定--“先出 ...
- 【基础】httpclient注意事项
一.HttpClient有默认的执行器RetryExec,其默认的重试策略是DefaultHttpRequestRetryHandler. RetryExec在执行http请求的时候使用的是底层的基础 ...
- Ubuntu 14.04 LTS 火狐浏览器中,鼠标选择文字被删除的解决办法
这篇文章主要介绍了Ubuntu 火狐浏览器中,鼠标选择文字被删除的解决办法,需要的朋友可以参考下在终端中输入命令: ibus-setup将 “在应用程序窗口中启用内嵌编辑模式“ 选项取消
- dpkg安装deb缺少依赖包的解决方法
[先贴出解决方案(基于Ubuntu)]: 使用dpkg -i *.deb 的时候出现依赖没有安装 使用apt-get -f -y install 解决依赖问题后再执行dpkg安装deb包 === ...
- 如何分离p12(或pfx)文件中的证书和私钥
p12(或者pfx)文件里一般存放有CA的根证书,用户证书和用户的私钥 假设我们有一个test.p12文件 在安装了openssl的linux服务器上执行以下命令: 提取用户证书: openssl p ...
- 解决方案:CS0016: 未能写入输出文件“c:\Windows\Microsoft.NET\Framework64\v4.0.30319\--”--“拒绝访问。 ”
IIS部署的网站打开出现问题: CS0016: 未能写入输出文件“c:\Windows\Microsoft.NET\Framework64\v4.0.30319\Temporary ASP.NET F ...
- kvm/qemu虚拟机桥接网络创建与配置
首先阐述一下kvm与qemu的关系,kvm是修改过的qemu,而且使用了硬件支持的仿真,仿真速度比QEMU快. 配置kvm/qemu的网络有两种方法.其一,默认方式为用户模式网络(Usermode N ...