crawlspider爬虫:定义url规则
spider爬虫,适合meta传参的爬虫(列表页,详情页都有数据要爬取的时候)
crawlspider爬虫,适合不用meta传参的爬虫
scrapy genspider -t crawl it it.com
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from Sun.items import SunItem class DongguanSpider(CrawlSpider):
name = 'dongguan'
# 修改允许的域
allowed_domains = ['sun0769.com']
# 修改起始的url
start_urls = ['http://wz.sun0769.com/index.php/question/questionType?type=4'] rules = (
# 构建列表url的提取规则
Rule(LinkExtractor(allow=r'questionType'), follow=True),
# 构建详情页面url提取规则
# 'html/question/201711/352271.shtml'
Rule(LinkExtractor(allow=r'html/question/\d+/\d+.shtml'), callback='parse_item'),
) def parse_item(self, response):
# print (response.url,'--------') # 构建item实例
item = SunItem() # 抽取数据,将数据存放到item中
item['number'] = response.xpath('/html/body/div[6]/div/div[1]/div[1]/strong/text()').extract()[0].split(':')[-1].strip()
item['title'] = response.xpath('/html/body/div[6]/div/div[1]/div[1]/strong/text()').extract()[0].split(':')[-1].split(' ')[0]
item['link'] = response.url
data = ''.join(response.xpath('//div[@class="c1 text14_2"]/text()|//div[@class="contentext"]/text()').extract())
item['content'] = data.replace('\xa0','')
# print(item)
# 返回数据
yield item

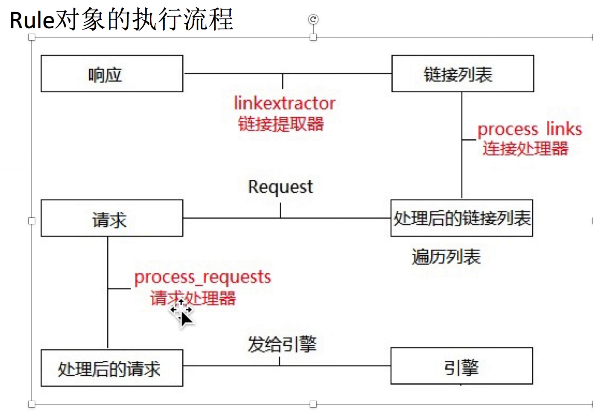
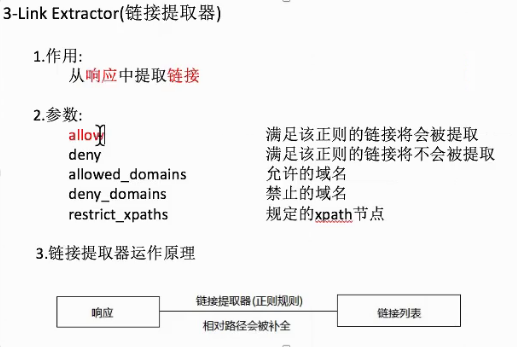
链接提取器的使用
scrapy shell http://hr.tencent.com/position.php
>>> from scrapy.linkextractors import LinkExtractor
>>> le = LinkExtractor(allow=('position_detail.php\?id=\d+&keywords=&tid=0&lid=0'))
或者直接 le = LinkExtractor(allow=('position_detail.php')) 也可以
>>> links=le.extract_links(response)
>>> for link in links:
... print(link)
...
>>> for link in links:
... print(link.url)
...


crawlspider爬虫:定义url规则的更多相关文章
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- Django学习(四) Django提供的后台管理系统以及如何定义URL路由
一旦你建立了模型Models,那么Django就可以为你创建一个专业的,可以提供给生成用的后台管理站点.这个站点可以提供给有权限的人进行已有模型Models数据的增删改查. 将新建的模型Models是 ...
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
- scrapy 中crawlspider 爬虫
爬取目标网站: http://www.chinanews.com/rss/rss_2.html 获取url后进入另一个页面进行数据提取 检查网页: 爬虫该页数据的逻辑: Crawlspider爬虫类: ...
- 《玩转Django2.0》读书笔记-编写URL规则
<玩转Django2.0>读书笔记-编写URL规则 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. URL(Uniform Resource Locator,统一资源定位 ...
- Scrapy - CrawlSpider爬虫
crawlSpider 爬虫 思路: 从response中提取满足某个条件的url地址,发送给引擎,同时能够指定callback函数. 1. 创建项目 scrapy startproject mysp ...
- 创建CrawlSpider爬虫简要步骤
创建CrawlSpider爬虫简要步骤: 1. 创建项目文件: e.g: scrapy startproject douyu (douyu为项目名自定义) 2. 进入项目文件: e.g: cd dou ...
- dt框架自定义url规则
destoon的列表的地址规则是定义在/api/url.inc.php,然后又是在include/global.func.php中进行的listpages这个函数调用实现 if($page < ...
- PHPCMS V9静态化HTML生成设置及URL规则优化
先讲讲Phpcms V9在后台怎么设置生成静态化HTML,之后再讲解怎么自定义URL规则,进行URL地址优化.在这一篇中,伪静态就不涉及了,大家可以移步到Phpcms V9全站伪静态设置方法. 一.静 ...
随机推荐
- (转载)JVM实现synchronized的底层机制
目前在Java中存在两种锁机制:synchronized和Lock,Lock接口及其实现类是JDK5增加的内容,其作者是大名鼎鼎的并发专家Doug Lea.本文并不比较synchronized与Loc ...
- iOS 沙盒目录结构及正确使用
前言:处于安全考虑,iOS系统的沙盒机制规定每个应用都只能访问当前沙盒目录下面的文件(也有例外,比如在用户授权情况下访问通讯录,相册等),这个规则展示了iOS系统的封闭性.在开发中常常需要数据存储的功 ...
- 基础知识《零》---一张图读懂JDK,JRE,JVM的区别与联系
- [sql异常]SQL Server 阻止了对组件 'Ad Hoc Distributed Queries' 的
//执行远程数据库表查询 SELECT * FROM OPENDATASOURCE('SQLOLEDB', 'Data Source=数据库地址;User ID=sa;password=sa' ).n ...
- Material Design系列第八篇——Creating Lists and Cards
Creating Lists and Cards //创建列表和卡片 To create complex lists and cards with material design styles in ...
- C# 中对COOKIES的操作
HttpUtility.UrlDecode HttpUtility.UrlEncode HttpContext.Current.Request.Cookies["UserCode" ...
- 转载>>六款大数据采集平台的架构分析
随着大数据越来越被重视,数据采集的挑战变的尤为突出.今天为大家介绍几款数据采集平台: Apache Flume Fluentd Logstash Chukwa Scribe Splunk Forwar ...
- 报错---“node install.js”
如图 解决方案: 目录中执行 npm install chromedriver --chromedriver_cdnurl=http://cdn.npm.taobao.org/dist/chromed ...
- MySQL外键和高级查询(连接查询、联合查询、子查询、去重查询)
MySQL的外键 什么是外键,很简单保持数据一致性的一个约束键.如果你有两张表,第一张是学生表,第二张表是一个成绩表,我们来看看保持数据一致性,其实在Django等框架的模型中中也能做关联获取对象. ...
- 配置Mac漂亮的Shell--Iterm2+OhMyZSH+Agnoster
安装包管理器 首先当然是解决包管理的问题,Mac下面是Homebrew的天下了 /usr/bin/ruby -e "$(curl -fsSL https://raw.githubuserco ...