无监督学习 Kmeans
无监督学习
自动对输入数据进行分类或者分群
优点:
算法不受监督信息(偏见)的约束,可能考虑到新的信息
不需要标签数据,极大程度扩大数据样本
Kmeans 聚类
根据数据与中心点距离划分类别
基于类别数据更新中心点
重复过程直到收敛
特点:实现简单、收敛快;需要指定类别数量(需要告诉计算机要分成几类)
- 选择聚类的个数
- 确定聚类中心
- 根据点到聚类中心聚类确定各个点所属类别
- 更具各个类别数据更新聚类中心
- 重复以上步骤直到收敛(中心点不再变化)
均值漂移聚类 Meanshift
在中心点一定区域检索数据点
更新中心
重复流程到中心点稳定
DBSCAN算法(基于密度的空间聚类算法)
基于区域点密度筛选有效数据
基于有效数据向周边扩张,直到没有新点加入
特点:过滤噪音数据;不需要人为选择类别数量;数据密度不同时影响结果
KNN K邻近分类监督学习
给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类, 就把该输入实例分类到这个类中。
参考链接
https://blog.csdn.net/weixin_46344368/article/details/106036451?spm=1001.2014.3001.5502
code
#加载数据并预览
import pandas as pd
import numpy as np
data = pd.read_csv('data.csv')
data.head()
#定义X和y
X = data.drop(['labels'],axis=1)
y = data.loc[:,'labels']
y.head()#预览
pd.value_counts(y) #查看类别数(这里有0,1,2三个类别)以及每个类别对应的样本数
#导入数据以及数据可视化
%matplotlib inline
from matplotlib import pyplot as plt
fig1 = plt.figure()
plt.scatter(X.loc[:,'V1'],X.loc[:,'V2'])
plt.title("un-labled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.show()
#给出标签
fig1 = plt.figure()
label0 = plt.scatter(X.loc[:,'V1'][y==0],X.loc[:,'V2'][y==0])
label1 = plt.scatter(X.loc[:,'V1'][y==1],X.loc[:,'V2'][y==1])
label2 = plt.scatter(X.loc[:,'V1'][y==2],X.loc[:,'V2'][y==2])
plt.title("labled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.show()
#建立模型
from sklearn.cluster import KMeans
KM = KMeans(n_clusters=3,random_state=0)
KM.fit(X)
#给出中心点
centers = KM.cluster_centers_
fig3 = plt.figure()
label0 = plt.scatter(X.loc[:,'V1'][y==0],X.loc[:,'V2'][y==0])
label1 = plt.scatter(X.loc[:,'V1'][y==1],X.loc[:,'V2'][y==1])
label2 = plt.scatter(X.loc[:,'V1'][y==2],X.loc[:,'V2'][y==2])
plt.title("labled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])
plt.show()
#测试数据: V1=80,V2=60
y_predict_test = KM.predict([[80,60]])
print(y_predict_test)
y_predict = KM.predict(X)
print(pd.value_counts(y_predict),'\n',pd.value_counts(y))
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y,y_predict)
print(accuracy)
fig4 = plt.subplot(121)
label0 = plt.scatter(X.loc[:,'V1'][y_predict==0],X.loc[:,'V2'][y_predict==0])
label1 = plt.scatter(X.loc[:,'V1'][y_predict==1],X.loc[:,'V2'][y_predict==1])
label2 = plt.scatter(X.loc[:,'V1'][y_predict==2],X.loc[:,'V2'][y_predict==2])
plt.title("predicted data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])
fig5 = plt.subplot(122)
label0 = plt.scatter(X.loc[:,'V1'][y==0],X.loc[:,'V2'][y==0])
label1 = plt.scatter(X.loc[:,'V1'][y==1],X.loc[:,'V2'][y==1])
label2 = plt.scatter(X.loc[:,'V1'][y==2],X.loc[:,'V2'][y==2])
plt.title("labled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])
plt.show()
#矫正结果
y_corrected = []
for i in y_predict:
if i==0:
y_corrected.append(1)
elif i==1:
y_corrected.append(2)
else:
y_corrected.append(0)
print(pd.value_counts(y_corrected),pd.value_counts(y))
print(accuracy_score(y,y_corrected))
y_corrected = np.array(y_corrected)
print(type(y_corrected))
fig6 = plt.subplot(121)
label0 = plt.scatter(X.loc[:,'V1'][y_corrected==0],X.loc[:,'V2'][y_corrected==0])
label1 = plt.scatter(X.loc[:,'V1'][y_corrected==1],X.loc[:,'V2'][y_corrected==1])
label2 = plt.scatter(X.loc[:,'V1'][y_corrected==2],X.loc[:,'V2'][y_corrected==2])
plt.title("corrected data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])
fig7 = plt.subplot(122)
label0 = plt.scatter(X.loc[:,'V1'][y==0],X.loc[:,'V2'][y==0])
label1 = plt.scatter(X.loc[:,'V1'][y==1],X.loc[:,'V2'][y==1])
label2 = plt.scatter(X.loc[:,'V1'][y==2],X.loc[:,'V2'][y==2])
plt.title("labled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])
plt.show()
# eatablish a KNN model
from sklearn.neighbors import KNeighborsClassifier
KNN = KNeighborsClassifier(n_neighbors = 3)
KNN.fit(X,y)
# predict based on the test data V1 = 80 V2 = 60
y_predict_knn_test = KNN.predict([[80,60]])
y_predict_knn = KNN.predict(X)
print(y_predict_knn_test)
print('Knn accuracy:',accuracy_score(y,y_predict_knn))
print(pd.value_counts(y_predict_knn),pd.value_counts(y))
fig8 = plt.subplot(121)
label0 = plt.scatter(X.loc[:,'V1'][y_predict_knn==0],X.loc[:,'V2'][y_predict_knn==0])
label1 = plt.scatter(X.loc[:,'V1'][y_predict_knn==1],X.loc[:,'V2'][y_predict_knn==1])
label2 = plt.scatter(X.loc[:,'V1'][y_predict_knn==2],X.loc[:,'V2'][y_predict_knn==2])
plt.title("knn predict data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])
fig9 = plt.subplot(122)
label0 = plt.scatter(X.loc[:,'V1'][y==0],X.loc[:,'V2'][y==0])
label1 = plt.scatter(X.loc[:,'V1'][y==1],X.loc[:,'V2'][y==1])
label2 = plt.scatter(X.loc[:,'V1'][y==2],X.loc[:,'V2'][y==2])
plt.title("labled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])
plt.show()
# try meanshift model
from sklearn.cluster import MeanShift,estimate_bandwidth
# obtain the bandwidth
bw = estimate_bandwidth(X, n_samples=500)
print(bw)
# establish the meanshift model
ms = MeanShift(bandwidth=bw)
ms.fit(X)
y_predict_ms = ms.predict(X)
print(pd.value_counts(y_predict_ms), pd.value_counts(y))
fig10 = plt.subplot(121)
label0 = plt.scatter(X.loc[:,'V1'][y_predict_ms==0],X.loc[:,'V2'][y_predict_ms==0])
label1 = plt.scatter(X.loc[:,'V1'][y_predict_ms==1],X.loc[:,'V2'][y_predict_ms==1])
label2 = plt.scatter(X.loc[:,'V1'][y_predict_ms==2],X.loc[:,'V2'][y_predict_ms==2])
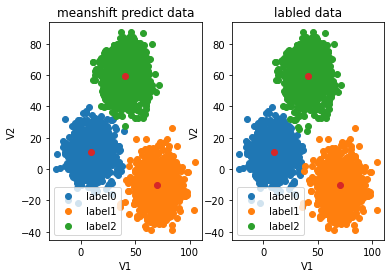
plt.title("meanshift predict data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])
fig11 = plt.subplot(122)
label0 = plt.scatter(X.loc[:,'V1'][y==0],X.loc[:,'V2'][y==0])
label1 = plt.scatter(X.loc[:,'V1'][y==1],X.loc[:,'V2'][y==1])
label2 = plt.scatter(X.loc[:,'V1'][y==2],X.loc[:,'V2'][y==2])
plt.title("labled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])
plt.show()
#矫正结果
y_corrected_ms = []
for i in y_predict_ms:
if i==0:
y_corrected_ms.append(2)
elif i==1:
y_corrected_ms.append(1)
else:
y_corrected_ms.append(0)
print(pd.value_counts(y_corrected_ms),pd.value_counts(y))
# convert the results to numpy array
y_corrected_ms = np.array(y_corrected_ms)
print(type(y_corrected_ms))
fig12 = plt.subplot(121)
label0 = plt.scatter(X.loc[:,'V1'][y_corrected_ms==0],X.loc[:,'V2'][y_corrected_ms==0])
label1 = plt.scatter(X.loc[:,'V1'][y_corrected_ms==1],X.loc[:,'V2'][y_corrected_ms==1])
label2 = plt.scatter(X.loc[:,'V1'][y_corrected_ms==2],X.loc[:,'V2'][y_corrected_ms==2])
plt.title("meanshift predict data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])
fig13 = plt.subplot(122)
label0 = plt.scatter(X.loc[:,'V1'][y==0],X.loc[:,'V2'][y==0])
label1 = plt.scatter(X.loc[:,'V1'][y==1],X.loc[:,'V2'][y==1])
label2 = plt.scatter(X.loc[:,'V1'][y==2],X.loc[:,'V2'][y==2])
plt.title("labled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])
plt.show()
image
无监督学习 Kmeans的更多相关文章
- 4.无监督学习--K-means聚类
K-means方法及其应用 1.K-means聚类算法简介: k-means算法以k为参数,把n个对象分成k个簇,使簇内具有较高的相似度,而簇间的相似度较低.主要处理过程包括: 1.随机选择k个点作为 ...
- 机器学习7-模型保存&无监督学习
模型保存和加载 sklearn模型的保存和加载API from sklearn.externals import joblib 保存:joblib.dump(rf, 'test.pkl') 加载:es ...
- 监督学习 VS 无监督学习
监督学习 就是人们常说的分类,通过已有的训练样本(即已知数据以及其对应的输出)去训练得到一个最优模型(这个模型属于某个函数的集合,最优则表示在某个评价准则下是最佳的),再利用这个模型将所有的输入映射为 ...
- Machine Learning Algorithms Study Notes(4)—无监督学习(unsupervised learning)
1 Unsupervised Learning 1.1 k-means clustering algorithm 1.1.1 算法思想 1.1.2 k-means的不足之处 1 ...
- 【学习笔记】非监督学习-k-means
目录 k-means k-means API k-means对Instacart Market用户聚类 Kmeans性能评估指标 Kmeans性能评估指标API Kmeans总结 无监督学习,顾名思义 ...
- 无监督学习——K-均值聚类算法对未标注数据分组
无监督学习 和监督学习不同的是,在无监督学习中数据并没有标签(分类).无监督学习需要通过算法找到这些数据内在的规律,将他们分类.(如下图中的数据,并没有标签,大概可以看出数据集可以分为三类,它就是一个 ...
- Andrew Ng-ML-第十四章-无监督学习
1.无监督学习概述 图1.无监督学习 有监督学习中,数据是有标签的,而无监督学习中的训练集是没有标签的,比如聚类算法. 2.k-means算法 k-means算法应用是十分广泛的聚类方法,它包括两个 ...
- Machine Learning分类:监督/无监督学习
从宏观方面,机器学习可以从不同角度来分类 是否在人类的干预/监督下训练.(supervised,unsupervised,semisupervised 以及 Reinforcement Learnin ...
- 无监督学习(Unsupervised Learning)
无监督学习(Unsupervised Learning) 聚类无监督学习 特点 只给出了样本, 但是没有提供标签 通过无监督学习算法给出的样本分成几个族(cluster), 分出来的类别不是我们自己规 ...
- 斯坦福机器学习视频笔记 Week8 无监督学习:聚类与数据降维 Clusting & Dimensionality Reduction
监督学习算法需要标记的样本(x,y),但是无监督学习算法只需要input(x). 您将了解聚类 - 用于市场分割,文本摘要,以及许多其他应用程序. Principal Components Analy ...
随机推荐
- python爬虫爬取B站视频字幕,简单的数据处理(pandas将字幕写入到CSV文件中)
上文,我们爬取到B站视频的字幕:https://www.cnblogs.com/becks/p/14540355.html 这篇,讲讲怎么把爬到的字幕写到CSV文件中,以便用于后面的分析 本文主要用到 ...
- robotframework:运用JavaScript进行定位元素以及页面操作
在ui自动化时,有些特殊情况需要用到js操作,在进行js操作前要先进行js元素定位.一.js元素定位 1.id定位 document.getElementById("id") 2. ...
- [笔记]这些超级好用的html标签和css属性
1.sup.sub 上标.下标,直接看下面的例子吧 A<sub>2</sub> 4<sup>2</sup> 42 A2 2.伪类属性的love hate ...
- Go-Spring v1.2.0 版本简介
引言 随着微服务和云原生架构的普及,Go 语言以其高并发.低延迟和简洁语法在后端开发领域迅速崛起.然而,原生 Go 在项目结构.依赖管理.配置热更新等方面相比 Java Spring 生态尚有短板.G ...
- 【HUST】网安|操作系统实验|实验二 进程管理与死锁
目的 1)理解进程/线程的概念和应用编程过程: 2)理解进程/线程的同步机制和应用编程: 任务 1)在Linux下创建一对父子进程. 2)在Linux下创建2个线程A和B,循环输出数据或字符串. 3) ...
- k8s入门操作
kubectl -->apiserver 管理工具 管理k8s集群 增删改查node kubectl get service/node/replicaset/deployment/statefu ...
- Vue3 学习-初识体验-helloworld
在数据分析中有一个最重要的一环就是数据可视化, 数据报表的开发. 从我从业这几年的经历上看, 经历了从业务系统导表格数据, 到Excel+PPT, 再是开源报表工具, 再是主流商业BI产品(低/零代码 ...
- 【SQL周周练】:利用行车轨迹分析犯罪分子作案地点
大家好,我是"蒋点数分",多年以来一直从事数据分析工作.从今天开始,与大家持续分享关于数据分析的学习内容. 本文是第 7 篇,也是[SQL 周周练]系列的第 6 篇.该系列是挑选或 ...
- WPF应用启动时,检测触摸失效的几种方式
在开发OPS项目,发现插拔式的OPS在切换系统.开关机.重启,会时不时出现部分WPF开机自启的 应用触摸失效的问题.而且出现问题的应用都是全屏窗口应用.用snoop 附加上去,没有Touch 和Sty ...
- 【公众号搬运】React-Native开发鸿蒙NEXT(3)
.markdown-body { line-height: 1.75; font-weight: 400; font-size: 16px; overflow-x: hidden; color: rg ...