python爬虫爬取B站视频字幕,简单的数据处理(pandas将字幕写入到CSV文件中)
上文,我们爬取到B站视频的字幕:https://www.cnblogs.com/becks/p/14540355.html
这篇,讲讲怎么把爬到的字幕写到CSV文件中,以便用于后面的分析
本文主要用到“pandas”这个库对数据进行处理
import pandas as pd
首先需要对爬取到的内容进行数据提取
comments = [comment.text for comment in results]#从爬取的数据中取出弹幕数据,返回文本内容
执行后如下图
然后生成字典
comments_dict = {'comments': comments}#创建字典,把字幕内容装入字典
处理数据,使数据以表格形式展示
df = pd.DataFrame(comments_dict)#格式化字幕字典,将字幕内容已表格格式显示
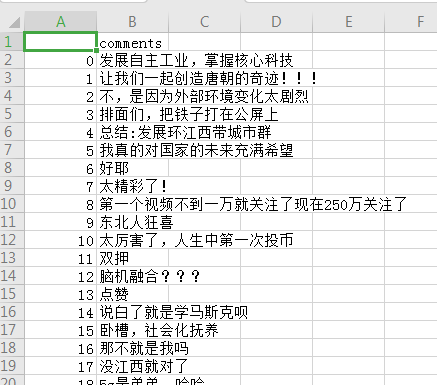
效果如下图

把格式化后的数据,存到CSV文件中
df.to_csv('B站字母.csv', encoding='utf-8-sig')#格式化后的字幕内容写入到CSV文件中
执行后,会在脚本同目录下生成CSV文件,文件内容如下图
全部脚本
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup
import requests
import re
import pandas as pd url = 'http://comment.bilibili.com/309778762.xml'
html = requests.get(url)
html.encoding='utf8' soup = BeautifulSoup(html.text,'lxml')
results = soup.find_all('d') comments = [comment.text for comment in results]#从爬取的数据中取出弹幕数据,返回文本内容
comments_dict = {'comments': comments}#创建字典,把字幕内容装入字典
df = pd.DataFrame(comments_dict)#格式化字幕字典,将字幕内容已表格格式显示
df.to_csv('B站字母.csv', encoding='utf-8-sig')#格式化后的字幕内容写入到CSV文件中
格式化数据“pd.DataFrame”函数的用法可以参考,https://www.cnblogs.com/andrew-address/p/13040035.html
python爬虫爬取B站视频字幕,简单的数据处理(pandas将字幕写入到CSV文件中)的更多相关文章
- python爬虫:爬取慕课网视频
前段时间安装了一个慕课网app,发现不用注册就可以在线看其中的视频,就有了想爬取其中的视频,用来在电脑上学习.决定花两天时间用学了一段时间的python做一做.(我的新书<Python爬虫开发与 ...
- Python 自动爬取B站视频
文件名自定义(文件格式为.py),脚本内容: #!/usr/bin/env python #-*-coding:utf-8-*- import requests import random impor ...
- python爬虫爬取安居客并进行简单数据分析
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 爬取过程一.指定爬取数据二.设置请求头防止反爬三.分析页面并且与网页源码进行比对四.分析页面整理数据 ...
- python爬虫——爬取B站用户在线人数
国庆期间想要统计一下bilibili网站的在线人数变化,写了一个简单的爬虫程序.主要是对https://api.bilibili.com/x/web-interface/online返回的参数进行分析 ...
- 爬虫---爬取b站小视频
前面通过python爬虫爬取过图片,文字,今天我们一起爬取下b站的小视频,其实呢,测试过程中需要用到视频文件,找了几个网站下载,都需要会员什么的,直接写一篇爬虫爬取视频~~~ 分析b站小视频 1.进入 ...
- 爬虫之爬取B站视频及破解知乎登录方法(进阶)
今日内容概要 爬虫思路之破解知乎登录 爬虫思路之破解红薯网小说 爬取b站视频 Xpath选择器 MongoDB数据库 爬取b站视频 """ 爬取大的视频网站资源的时候,一 ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
随机推荐
- C 简答题
1.从C语⾔执⾏效率⽅便,简述下C语⾔采取了哪些措施提⾼执⾏效率.(14分 or 20分)(年年考,⾮常重要) ①使⽤指针:有些程序⽤其他语⾔也可以实现,但C能够更有效地实现:有些程序⽆法⽤其它语⾔实 ...
- 深⼊mysqlONDUPLICATEKEYUPDATE语法的分析
深⼊mysqlONDUPLICATEKEYUPDATE语法的分析mysql "ON DUPLICATE KEY UPDATE" 语法如果在INSERT语句末尾指定了ON DUPLI ...
- 第一个helloworld,有点小兴奋
@SpringBootApplication package com.ch.boot; import org.springframework.boot.SpringApplication; imp ...
- 认识soui4js(第5篇):使用扩展控件
无论内置控件多么丰富,也不可能满足用户所有需求.总有时候用户需要自己扩展控件. soui4js推荐使用C++来扩展控件,然后通过实现一个js模块来提供js使用. 扩展控件通常涉及到图形上下文的频繁交互 ...
- Q:以非root用户编辑定时任务报错You are not allowed to use this program(crontab)
编辑定时删除文件任务时报错 crontab -e 编辑定时任务时报错,如下图所示 问题原因:/etc/cron.allow中没有添加对应的用户名解决办法:切换到root用户,在/etc/cron.al ...
- kubernets学习笔记二
Kubernetes部署"容器化应用" Kubernetes整体架构 何为"容器化应用"? 通俗点来说,就是你把一个程序放在docker里部署,这个docker ...
- GUI编程之AWT
介绍 包含了很多类和接口 元素:窗口.按钮.文本框 java.awt Frame 就是一个窗口 实现 package com.yeyue.lesson01;import java.awt.*;pu ...
- 《刚刚问世》系列初窥篇-Java+Playwright自动化测试-15- iframe操作--番外篇 (详细教程)
1.简介 通过前边三篇的学习,想必大家已经对iframe有了一定的认识和了解,今天这一篇主要是对iframe的一些特殊情况的介绍和讲解,主要从iframe的定位.监听事件和执行js脚本三个方面进行展开 ...
- Spark SQL (一)
Spark SQL Spark与Hive的比较,Hive用一句话总结是,传入一条交互式sql在海量数据中查找结果,Spark可以将其结果转化成RDD来来进一步操作. 1.0以前: Shark 1.1. ...
- CPrimerPlus
还没学 的 167页的wordcnt程序 199页的checking程序(太长了,不想看) 113页的第八章编程练习5(不想看) 125页的复习题9(有问题,有时间再来验证) 119页重定向和文件(n ...