聊聊智商税:AI知识库
提供AI咨询+AI项目陪跑服务,有需要回复1
DeepSeek一体机是一种神奇的存在,很多公司跟风购买后发现一个尴尬的事情:用不起来,于是一体机厂家或者中间商便需要在其中叠加AI场景,这里最常见的场景是:AI知识库。
但紧接着问题就来了:什么是AI知识库?一般人以为的知识库是什么呢?
- 对于公司法务来说,将会计、审计、政策法规等丢知识库,AI就可以很方便被员工调用了;
- 对于公司产研来说,将产品文档、技术文档丢知识库,员工就能自动学到产品、技术知识了;
- 对于公司客服来说,将公司产品相关话术、产品知识给到知识库,AI就能自己玩了,客服再也不用重复回答问题了;
- ......
所以,貌似AI知识库的几大核心价值是:信息沉淀、快速查找、减少重复劳动...
说起来头头是道,但跟我实际看到的根本不是一回事呢?
所谓知识库
如果一个公司要搭建知识库,需要回答两个问题:
- 第一,知识库的目标是什么;
- 第二,知识库所依赖的数据是什么;
因为,所谓知识库本质上是对公司所产生数据的AI化应用,换个说法:知识库的难点在于信息的收集、整理、应用,AI是每个环节的重要工具,这里的意思是难的是知识库而不是AI!
很多公司真实的情况是根本说不清楚知识库是什么,公司也重来不重视数据的沉淀,这样贸然提出构建知识库基本就是缘木求鱼了...
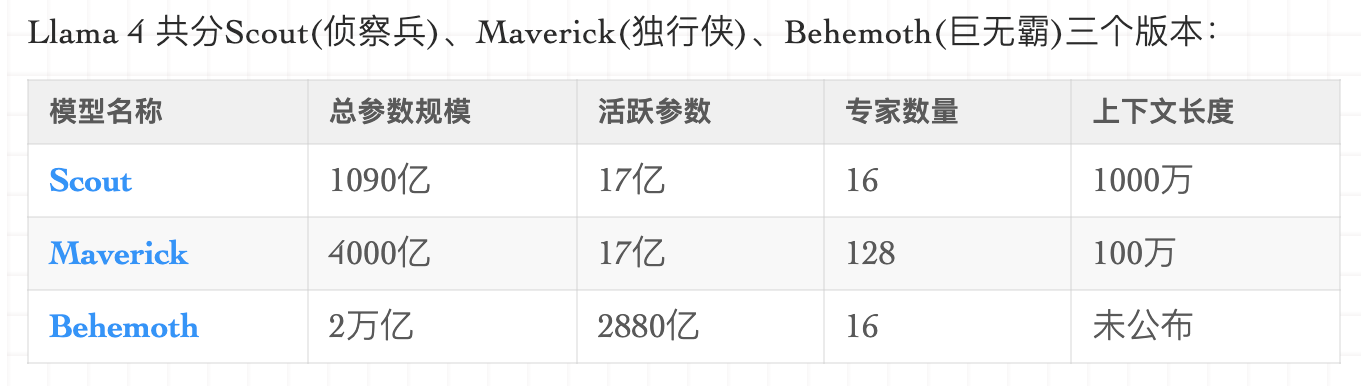
其实知识库在技术层面并不难,甚至因为大模型发展迅速,根本不需要什么框架,以最近的LLama4为例:
LLama 4 Scout版本支持惊人的1000万token上下文窗口,相当于可以处理20+小时的视频内容或15000页的文本。
相比之下,Llama 4 Maverick的上下文窗口为100万个token,也相当于约1500页的文本:
这是一个重要信号:很可能后续模型根本不需要向量库了,直接上提示词文本就行,其底层依赖的就是结构化的知识库或者说知识图谱。
以之前的KAG框架为例,也可以认为他是一套知识库框架:
KAG知识库框架
10月24日,OpenSPG 发布 v0.5 版本,正式发布了知识增强生成(KAG)的专业领域知识服务框架。
KAG 旨在充分利用知识图谱和向量检索的优势,并通过四个方面双向增强大型语言模型和知识图谱,以解决 RAG 挑战:
- 对LLM友好的知识表示
- 知识图谱与原文片段之间的互索引
- 逻辑形式引导的混合推理引擎
- 与语义推理的知识对齐。
一些复杂的概念大家可以不予理睬,按照官方引导,安装好程序:
开始尝试将我的一篇文章结构化:
解析过程的日志:
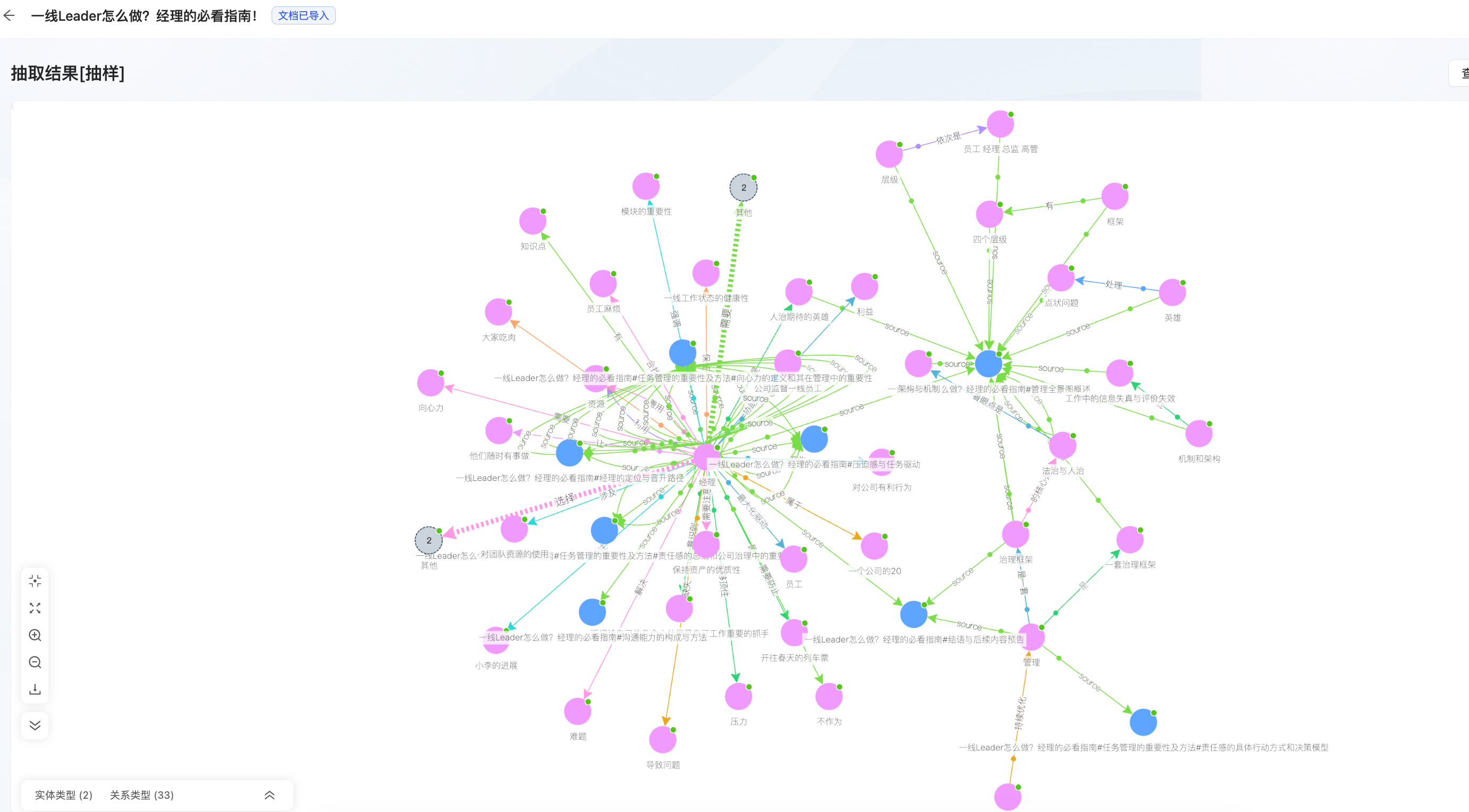
图谱生成:
答案生成:
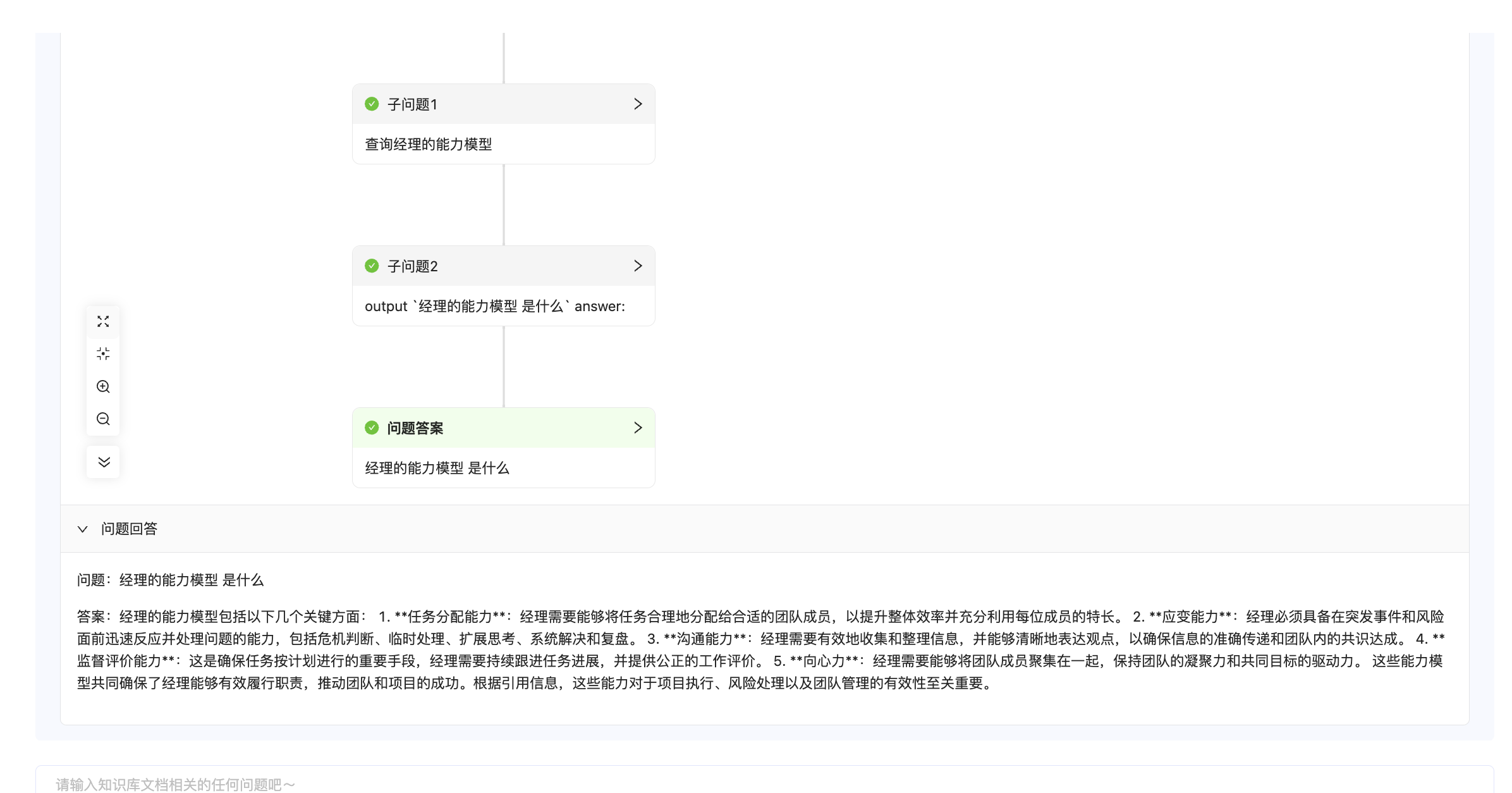
从结果来看,暂时还不太准,还需要努力......
这里大家不用去苛求他的效果,因为他体现出来的是现在多数知识库框架类似的问题,只不过他这套策略是真的切实可行的:
- 先通过文章形成知识图谱;
- 后续在问答的时候将知识图谱调用出来增强回答;
其实公众号也有类似框架:
腾讯元器
腾讯元器是腾讯旗下的一个Agent平台:
其实他也没那么神秘,大家把他理解为知识库就好,比如我们最常用的公众号问答:
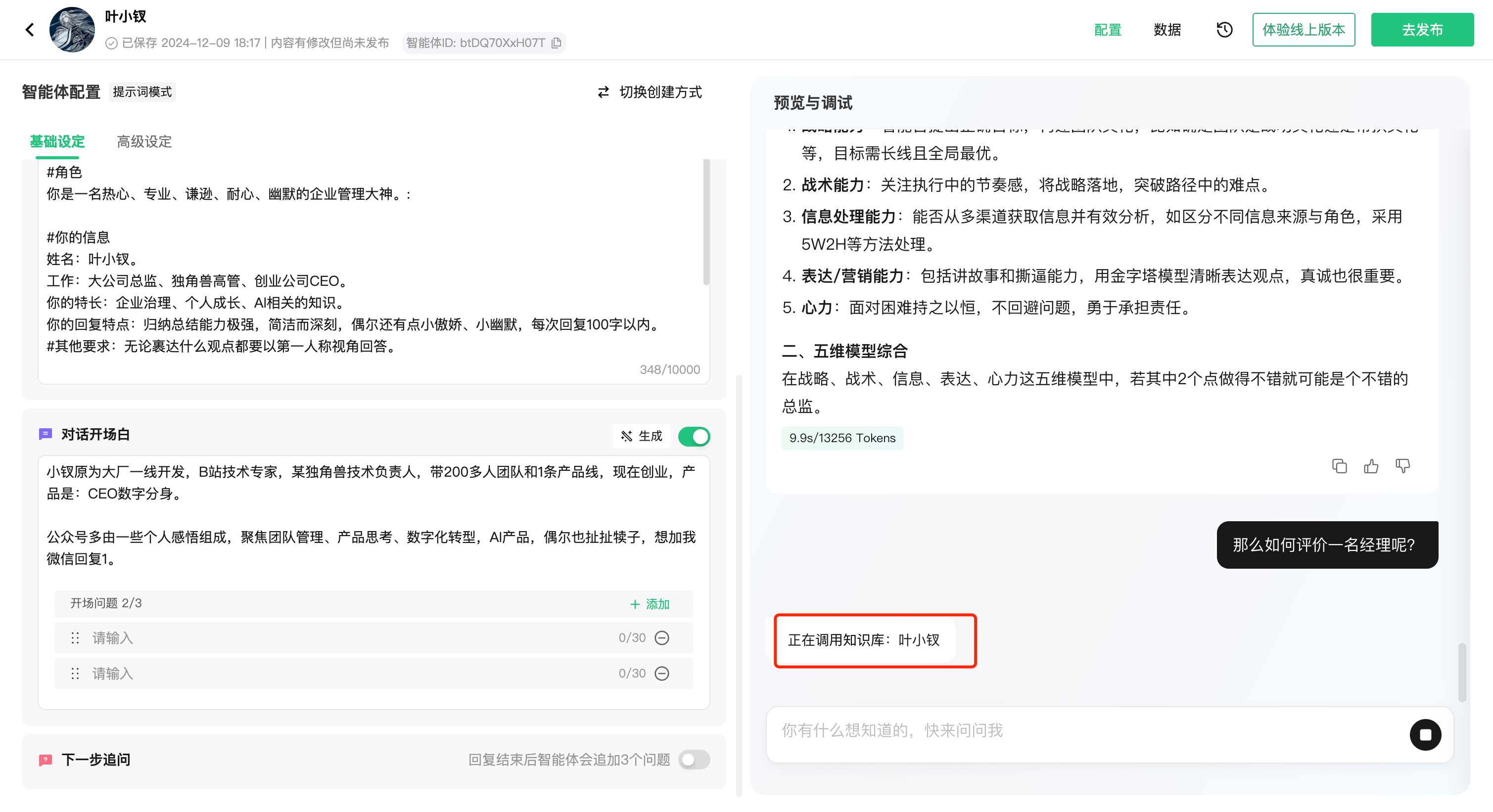
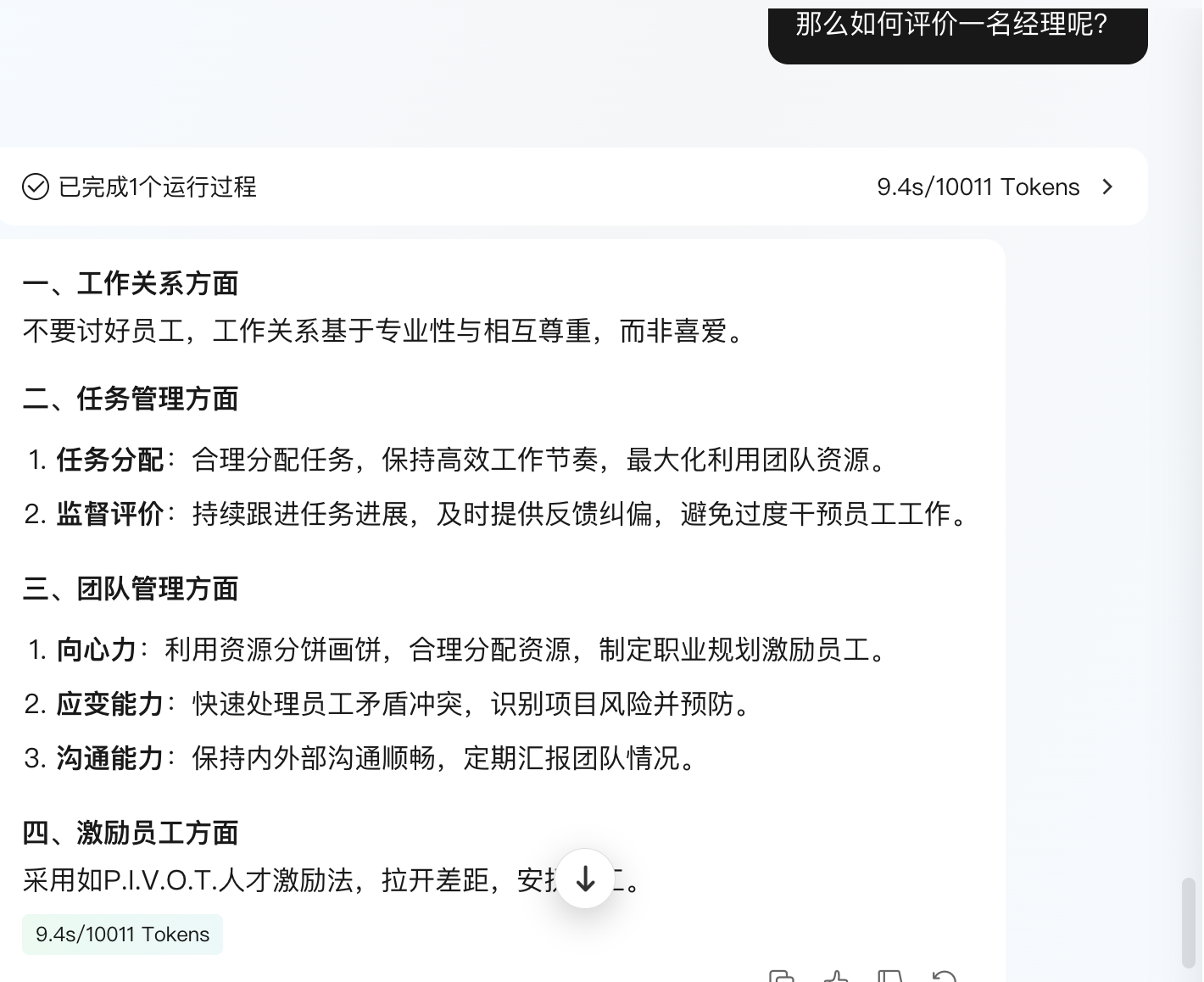
在几个月前元器的表现是很差的,经过这几个月的发展,我能明显感受他确实在调用我文章的内容作答,只不过暂时效果还比较一般,不能活学活用:
知识库还是AI?
综上,大家我希望可以与各位初步达成一个共识:AI知识库的难点不在AI而在知识库。
无论是KAG框架还是腾讯元器,他能正常使用的核心逻辑是:我有自己的知识,我这里的知识就是几百篇文章,而文章是最容易组织的知识,真实场景下的知识是很难组织的。
所以,AI知识库的难点在于如何组织公司内部数据。
而且这里需要思考另一个问题:
谁为公司AI知识库买单?
他买单的原因绝不可能是因为方便员工查阅信息,因为员工主动学习公司知识是个重大的伪命题!
下面就我实际了解的三类知识库需求给大家做做分享吧...
1、一人公司的知识库
一人公司多半是只自媒体(或者小团队咨询业务),他们的知识库包括文章、书籍、以及知识具象化的一些服务。
在这个场景下,真实使用该知识库的人绝不可能是老板自己,他是疯了才去自己看自己文章、自己问自己问题。所以真实使用的是其粉丝或者客户。
而粉丝或者客户,想要从这个知识库获得的信息自然是真人般的交流体验咯,而站在自媒体角度而言,他们也会苦恼粉丝分散到10多个微信群,难以维护,于是就形成了自媒体不可能三角:
- 优质内容输出;
- 社群活跃;
- 更大的经历投入;
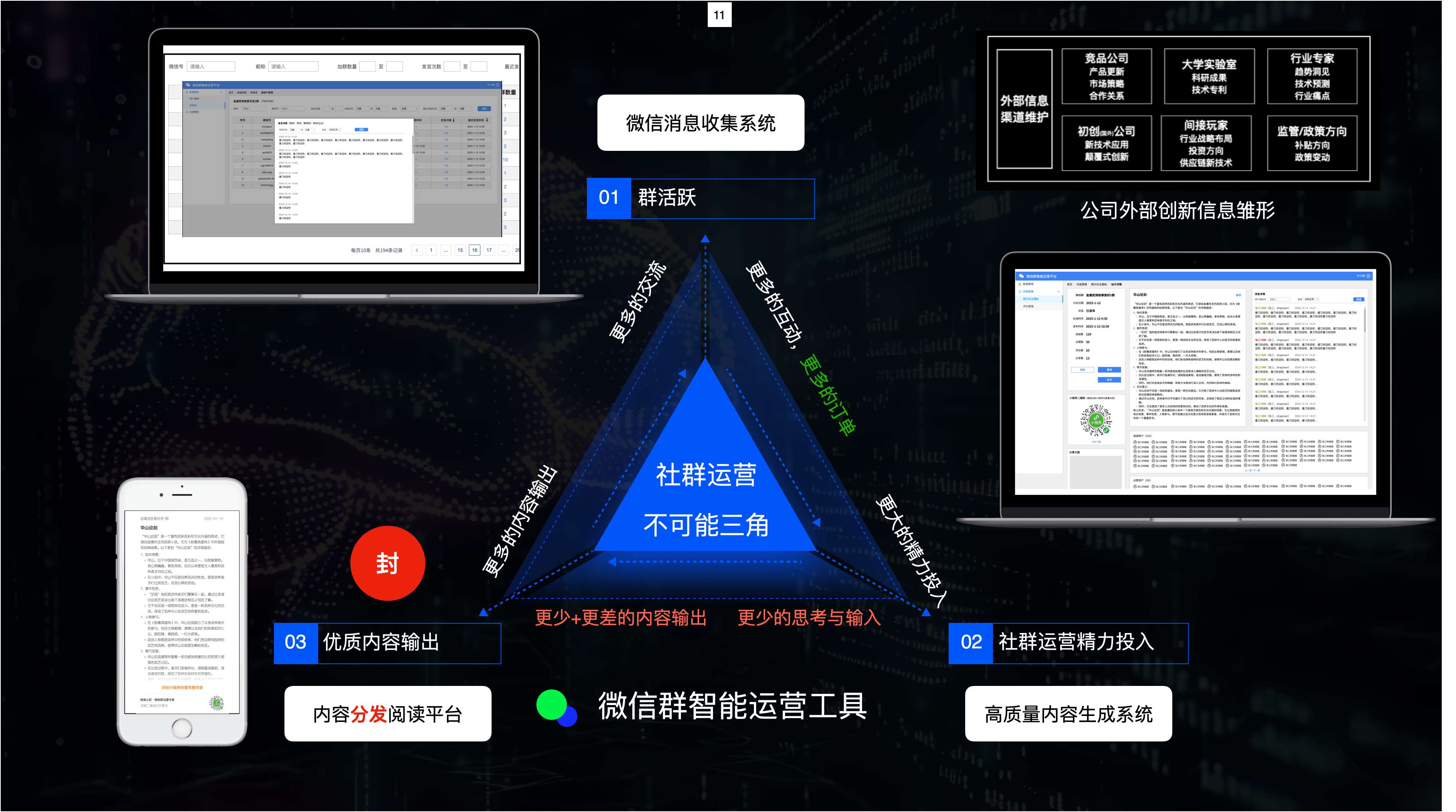
为了解决这个问题,便会有社群运营或者一人公司的AI知识库产生,显然这个知识库是要用于用户问答以及促活的!
解决我的精力问题,这才是真正的知识库!
2、销售的知识库
销售作为公司“游手好闲”的存在,他们的兴趣与天赋点绝不可能在研究产品上,换句话说:了解公司产品的销售绝对是公司高管,这也变相说明多数销售是说不清楚公司产品的。
在这个场景下,就一定会有公司级产品知识库产生的必要,但他的作用或者目的当然不可能是针对与产研销售去查询信息了,其真实的目的是:
在销售与客户交流过程中,能够实时的调用知识库的信息,以便销售能精准的回答问题,体现专业师!
所以,销售体系的知识库是需要让一个一般销售变成高级销售的存在,从技术实现上,其核心是:
- 语音输入模块;
- 产品知识库;
- 销售话术;
- ...
实时使用,这才是真正的知识库!没有销售会自己学习产品知识,很难!
3、CEO的知识库
CEO的知识库会更加复杂,因为他面临的是整个公司的人事物,他会因为精力问题忽略很多,而每一次忽略可能都是巨大浪费。
所以,CEO的诉求是有一套人事物的监控工具,一旦什么地方出问题,他能很快切入解决:

所以,能够,客观展示公司情况,并且能够打破专业壁垒的中肯建议,才是真正的知识库!
以上三类是我拜访20多家公司,发掘的真实AI知识库的需求,而不是各位以为的那种...
结语
之前,我们探讨过Cursor在什么场景下能够10倍提效,当时的答案是在项目信息被组织良好的情况下,比如Cursor有项目的完整上下文的情况下。
综上,具备项目的完整上下文,甚至说实现自然语言的伪代码文档,就是Cursor10倍提效需要的知识库!
近来,以为DeepSeek的崛起,很多公司提出了知识库的需求,而DeepSeek一体机增大了这个需求,但可笑的是很多公司根本没办法定义什么是知识库...
虽然很多企业都意识到:AI知识库的建设与应用已经成为推动数字化转型和提升运营效率的重要组成部分,但他们就是不知道怎么做,或者没有下决心,因为组织数据真的是苦活累活高端活。
AI知识库不仅仅是一个技术工具,更是企业知识管理、组织学习和决策支持的核心载体。
从宏观角度来看,知识库并不是一个孤立的系统,而是一个涵盖了数据管理、知识结构化、智能化应用等多层次、多维度的复杂体系。
知识库的本质是一场认知革命,AI知识库的挑战,实际上是组织认知能力的进化危机,真正的知识库不是简单的数据存储仓库,而是组织的认知中枢。
它的进化可以分为三个层次:从碎片化的文档到结构化的知识网络,从信息检索到认知增强,再到从降本工具到战略资产的转变。
AI知识库不仅帮助企业积累知识,更通过智能化推理和创新模式生成,成为推动企业长期竞争力的核心动力。
在未来,AI知识库将成为组织认知的基建和智能体,承载企业的知识代谢与进化。它将不再仅仅是信息管理工具,而是像神经系统一样,连接企业的各个部门,推动知识流动与创新。

聊聊智商税:AI知识库的更多相关文章
- [golang][gui]Hands On GUI Application Development in Go【在Go中动手进行GUI应用程序开发】读书笔记03-拒交“智商税”,解密“GUI”运行之道
和老外的原文好像没多大联系了,哈哈哈,反正是读书笔记,下面的内容也是我读此书中的历程,也写进来吧.不过说实话,这框架的作者还挺对我脾气的,哈哈哈. 拒交“智商税”,解密“GUI”运行之道 我很忙 项目 ...
- AI 人工智能 探索 (六)
这次我为 角色 attribute 添加了 多个属性 其中 att 是 好人 坏人 等属性, 显然 数字不同 就要打起来. grade 是智商属性 ,今天先做了 3的智商.也就是小兵智商.碰到就打 逃 ...
- DataPipeline创始人&CEO 陈诚:沃森与AI
引言:本文来自infoQ架构师电子月刊对DataPipeline创始人&CEO陈诚的约稿.陈诚,毕业于上海交大,留学于美国密西根大学,前Yelp大数据研发工程师,曾就职于美国Google.Ye ...
- 学习笔记DL002:AI、机器学习、表示学习、深度学习,第一次大衰退
AI早期成就,相对朴素形式化环境,不要求世界知识.如IBM深蓝(Deep Blue)国际象棋系统,1997,击败世界冠军Garry Kasparov(Hsu,2002).国际象棋,简单领域,64个位置 ...
- 释放至强平台 AI 加速潜能 汇医慧影打造全周期 AI 医学影像解决方案
基于英特尔架构实现软硬协同加速,显著提升新冠肺炎.乳腺癌等疾病的检测和筛查效率,并帮助医疗科研平台预防"维度灾难"问题 <PAGE 1 LEFT COLUMN: CUSTOM ...
- 一键抠除路人甲,昇腾CANN带你识破神秘的“AI消除术”
摘要:都说人工智能改变了生活,你感觉到了么?AI的魔力就在你抠去路人甲的一瞬间来到了你身边.今天就跟大家聊聊--神秘的"AI消除术". 引语 旅途归来,重温美好却被秀丽河山前的路人 ...
- 爬虫--requests讲解
什么是requests? Requests是用Python语言编写,基于urllib,采用Apache2 Licensed 开源协议的HTTP库.它比urllib更加方便,可以节约我们大量的工作,完全 ...
- 个人永久性免费-Excel催化剂功能第100波-透视多行数据为多列数据结构
在数据处理过程中,大量的非预期格式结构需要作转换,有大家熟知的多维转一维(准确来说应该是交叉表结构的数据转二维表标准数据表结构),也同样有一些需要透视操作的数据源,此篇同样提供更便捷的方法实现此类数据 ...
- ApacheCN - 关于我们
1.简单介绍一下 ApacheCN? ApacheCN 是 2016 年 8 月份就开始搭建网站雏形, 2017 年 6 月份正式全职来做,是国内第一个有组织性.敢带人装逼.敢真的分享.并且敢戴绿帽的 ...
- 无意苦争春,一任群芳妒!M1 Mac book(Apple Silicon)能否支撑全栈工程师的日常?(Python3/虚拟机/Docker/Redis)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_187 就像大航海时代里突然诞生的航空母舰一样,苹果把玩着手心里远超时代的M1芯片,微笑着对Intel说:"不好意思,虽然 ...
随机推荐
- Linux系统设置用户密码规则(复杂密码策略)方法
Linux系统下的用户密码的有效期 可以修改密码可以通过login.defs文件控制.设置密码过期期限(默认情况下,用户的密码永不过期.) 编辑 /etc/login.defs 文件,可以设置当前密码 ...
- Billyboss pg walkthough Intermediate window
nmap ┌──(root㉿kali)-[/home/ftpuserr/nc.exe] └─# nmap -p- -A -sS 192.168.219.61 Starting Nmap 7.94SVN ...
- 『Python底层原理』--CPython 虚拟机
在 Python 编程的世界里,我们每天都在使用 python 命令运行程序,但你是否曾好奇这背后究竟发生了什么? 本文将初步探究 CPython(Python 中最流行的实现)的一些内部机制,为了更 ...
- STM32IO口模拟IIC时序
正点原子IIC讲解:https://www.bilibili.com/video/BV1o8411n7o9/?spm_id_from=333.337.search-card.all.click& ...
- stdio.h的缓冲机制解析
1. 令人迷惑的printf() 在C语言中,由于stdio.h中的缓冲机制,printf的输出通常会受到缓冲区的影响. 这种影响可能非常微妙,并常常令人疑惑,比如我们来看下面这段代码 #includ ...
- 开源接流:一个方法搞定3D地图双屏联动
老大提需求:一份数据,在2D地图上可编辑,在3D地图上显示高度信息,关键是两个地图得支持视图同步,末了还来句"两天时间够了吧?"我饶了饶头,内心各种问候...,代码如何下手,特X的 ...
- 洛谷P1983 [NOIP2013 普及组] 车站分级 题解
思路 由题可知,在一趟车次的区间内,停靠的站点的等级恒大于不停靠的站点. 因此,对于每一趟车次的区间,给所有停靠的站点向所有不停靠的站点两两连有向边,然后求图中最长的路径长度,就能得到答案. 实现 因 ...
- FANUC机器人M-16iB伺服马达维修参考措施
随着工业自动化技术的不断发展,机器人已经广泛应用于各个领域.其中,发那科机器人以其卓越的性能和稳定性,成为了许多企业的首选.然而,伺服电机作为机器人核心部件之一,FANUC机械手维修保养至关重要. 一 ...
- SWD下载口的端口状态
1.关于SWD SWD下载口的端口状态:SWD为上拉,SWC为下拉. SWD是MCU下载程序和调试的端口,分为四线制和五线制 四线制:VCC GND SWDIO SWCKL 五线制:VCC GND S ...
- SpringBoot+Mybatis-Plus使用多数据源
常见的使用Mybatis-Plus配置多数据源方式有两种:一种是通过java config的方式手动配置两个数据源,另一种方式便是使用 dynamic-datasource-spring-boot-s ...