爬虫_淘宝(selenium)
总体来说代码还不是太完美
实现了js渲染网页的解析的一种思路
主要是这个下拉操作,不能一下拉到底,数据是在中间加载进来的,
具体过程都有写注释
from selenium import webdriver
import time
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from lxml import etree
import re
import pymongo client = pymongo.MongoClient('127.0.0.1', port=27017)
db = client.taobao_mark
collection = db.informations def search(url): # 设置无头浏览器
opt = webdriver.ChromeOptions()
opt.set_headless()
driver = webdriver.Chrome(options=opt)
driver.get(url) # 使用显示等待加载输入文本框,设置搜索关键字,以'轻薄本'为例
input_key = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, 'q')))
input_key.send_keys('轻薄本') # 显示等待加载搜索按钮,然后执行点击操作
search_btn = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, 'btn-search')))
search_btn.click() # 搜索出来的网页内容只有一行与关键字相关,剩下的都是广告
# 此时发现更多相关内容在//span[@class="see-all"]这个标签的链接中,
# 通过xpath获取链接,进行跳转
element = etree.HTML(driver.page_source)
list_page_url = element.xpath('//span[@class="see-all"]/a/@href')[0]
list_page_url = 'https://s.taobao.com/' + list_page_url
driver.close()
return list_page_url def scroll(driver):
# 如果没有进行动态加载,只能获取四分之一的内容,调用js实现下拉网页进行动态加载
for y in range(7):
js='window.scrollBy(0,600)'
driver.execute_script(js)
time.sleep(0.5) def get_detail_url(url): # 用来存储列表页中商品的的链接
detail_urls = [] opt = webdriver.ChromeOptions()
opt.set_headless()
driver = webdriver.Chrome(options=opt)
# driver = webdriver.Chrome()
driver.get(url) scroll(driver) # 通过简单处理,获取当前最大页数
max_page = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '//div[@class="total"]'))
)
text = max_page.get_attribute('textContent').strip()
max_page = re.findall('\d+', text, re.S)[0]
# max_page = int(max_page)
max_page = 1
# 翻页操作
for i in range(1, max_page+1):
print('正在爬取第%s页' % i)
# 使用显示等待获取页面跳转页数文本框
next_page_btn = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '//input[@class="input J_Input"]'))
) # 获取确定按钮,点击后可进行翻页
submit = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, '//span[@class="btn J_Submit"]'))
) next_page_btn.clear()
next_page_btn.send_keys(i)
# 这里直接点击会报错'提示不可点击',百度说有一个蒙层,
# 沉睡两秒等待蒙层消失即可点击
time.sleep(2)
submit.click()
scroll(driver) urls = WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located((By.XPATH, '//a[@class="img-a"]'))
)
for url in urls:
detail_urls.append(url.get_attribute('href'))
driver.close()
# 返回所有商品链接列表
return detail_urls def parse_detail(detail_urls):
parameters = []
opt = webdriver.ChromeOptions()
opt.set_headless()
driver = webdriver.Chrome(options=opt)
for url in detail_urls:
parameter = {} print('正在解析网址%s' % url)
driver.get(url)
html = driver.page_source
element = etree.HTML(html) # 名字name
name = element.xpath('//div[@class="spu-title"]/text()')
name = name[0].strip()
parameter['name'] = name # 价格price
price = element.xpath('//span[@class="price g_price g_price-highlight"]/strong/text()')[0]
price = str(price)
parameter['price'] = price # 特点specials
b = element.xpath('//div[@class="item col"]/text()')
specials = []
for i in b:
if re.match('\w', i, re.S):
specials.append(i)
parameter['specials'] = specials param = element.xpath('//span[@class="param"]/text()')
# 尺寸
size = param[0]
parameter['size'] = size
# 笔记本CPU
cpu = param[1]
parameter['cpu'] = cpu
# 显卡
graphics_card = param[2]
parameter['graphics_card'] = graphics_card
# 硬盘容量
hard_disk = param[3]
parameter['hard_disk'] = hard_disk
# 处理器主频
processor = param[4]
parameter['processor'] = processor
# 内存容量
memory = param[5]
parameter['memory'] = memory
parameter['url'] = url
print(parameter)
print('='*50)
save_to_mongo(parameter)
parameters.append(parameter)
return parameters def save_to_mongo(result):
try:
if collection.insert(result):
print('success save to mongodb', result)
except Exception:
print('error to mongo') def main():
url = 'https://www.taobao.com/'
list_page_url = search(url)
detail_urls = get_detail_url(list_page_url)
parameters = parse_detail(detail_urls) if __name__ == '__main__':
main()
运行结果
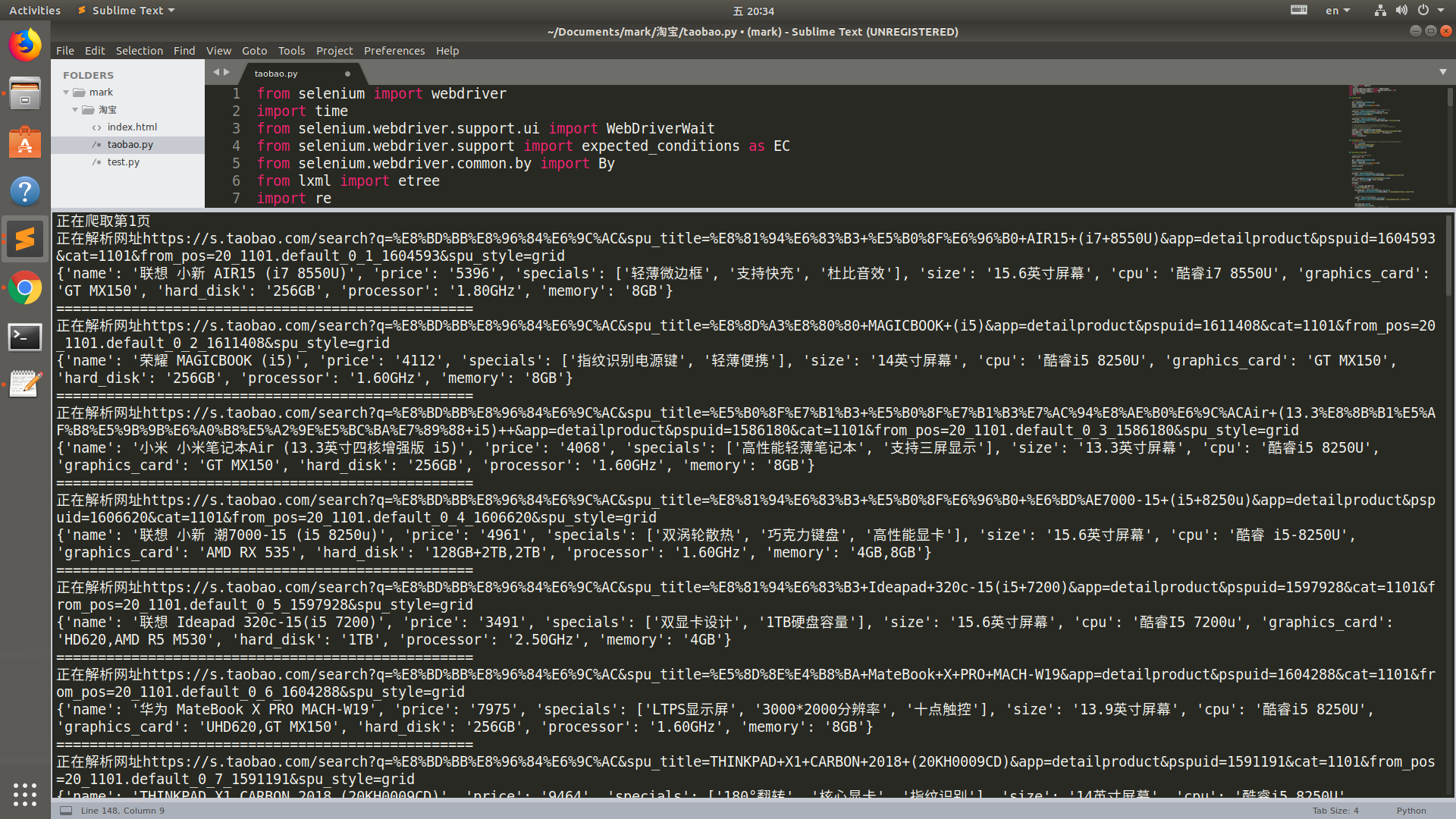
数据库

爬虫_淘宝(selenium)的更多相关文章
- Python爬虫 获得淘宝商品评论
自从写了第一个sina爬虫,便一发不可收拾.进入淘宝评论爬虫正题: 在做这个的时候,也没有深思到底爬取商品评论有什么用,后来,爬下来了数据.觉得这些数据可以用于帮助分析商品的评论,从而为用户选择商品提 ...
- python:爬虫获取淘宝/天猫的商品信息
[需求]输入关键字,如书包,可以搜索出对应商品的信息,包括:商品标题.商品链接.价格范围:且最终的商品信息需要符合:包邮.价格差不会超过某数值 #coding=utf-8 ""&q ...
- Python 爬虫知识点 - 淘宝商品检索结果抓包分析(续一)
通过前一节得出地址可能的构建规律,如下: https://s.taobao.com/search?data-key=s&data-value=44&ajax=true&_ksT ...
- Python 爬虫知识点 - 淘宝商品检索结果抓包分析
一.抓包基础 在淘宝上搜索“Python机器学习”之后,试图抓取书名.作者.图片.价格.地址.出版社.书店等信息,查看源码发现html-body中没有这些信息,分析脚本发现,数据存储在了g_page_ ...
- 手动爬虫之淘宝笔记本栏(ptyhon3)
1.这次爬虫用到了之前封装的Url_ProxyHelper类,源代码如下 import urllib.request as ur class Url_ProxyHelper: def __init__ ...
- [PHP] 编写爬虫获取淘宝网上所有的商品分类以及关键属性 销售属性 非关键属性数据
参考文章地址:https://blog.csdn.net/zhengzizhi/article/details/80716608 http://open.taobao.com/apitools/api ...
- Python 爬虫知识点 - 淘宝商品检索结果抓包分析(续二)
一.URL分析 通过对“Python机器学习”结果抓包分析,有两个无规律的参数:_ksTS和callback.通过构建如下URL可以获得目标关键词的检索结果,如下所示: https://s.taoba ...
- Python post请求模拟登录淘宝并爬取商品列表
一.前言 大概是一个月前就开始做淘宝的爬虫了,从最开始的用selenium用户配置到selenium模拟登录,再到这次的post请求模拟登录.一共是三篇博客,记录了我爬取淘宝网的经历.期间也有朋友向我 ...
- 学习用java基于webMagic+selenium+phantomjs实现爬虫Demo爬取淘宝搜索页面
由于业务需要,老大要我研究一下爬虫. 团队的技术栈以java为主,并且我的主语言是Java,研究时间不到一周.基于以上原因固放弃python,选择java为语言来进行开发.等之后有时间再尝试pytho ...
随机推荐
- python学习第十篇——while 的灵活运用
sandwiches_orders = ['apple','banana','mango',"apple","watermelon"] finished_san ...
- [2019BUAA软工助教]Alpha阶段无人转出申请审核结果
[2019BUAA软工助教]Alpha阶段无人转出申请审核结果 一.队伍信息 队伍名 项目 人数 红太阳 社团 8(6+2) pureman 博客园 6 水哥牛逼 招募 6 葫芦娃 拖拽Pytorch ...
- Glad to see you! CodeForces - 810D (交互+二分)
This is an interactive problem. In the output section below you will see the information about flush ...
- Jmeter之发送请求入参必须使用编码格式、Jmeter之发送Delete请求可能入参需要使用编码格式
这里的其中一个属性值必须要先编码再传参才可以,具体可以通过抓包分析观察:
- #Leetcode# 985. Sum of Even Numbers After Queries
https://leetcode.com/problems/sum-of-even-numbers-after-queries/ We have an array A of integers, and ...
- Laravel5 创建自定义门面(Facade)
门面为应用服务容器中的绑定类提供了一个“静态”接口.Laravel 内置了很多门面,你可能在不知道的情况下正在使用它们.Laravel 的门面作为服务容器中底层类的“静态代理”,相比于传统静态方法,在 ...
- [转帖]linux 清空history以及记录原理
linux 清空history以及记录原理 自己的linux 里面总是一堆 乱七八槽输错的命令 用这个办法 可以清空 linux的内容. 清爽一些. 1.当前session执行的命令,放置缓存中,执行 ...
- 使用docker化的nginx 反向代理 docker化的GSCloud 的方法
1. 首先将nginx 的image pull 下来. docker pull nginx 2. 将最近的可用的 参数文件 复制过来当一个目录 mkdir /nginx ssh root@linuxs ...
- linux重装后配一些库
#先要设置软件源 sudo apt-get update sudo apt-get upgrade #播放器 sudo apt-get install smplayer qt sudo apt-get ...
- 动态SQL1
If标签 动态SQL可以说是MyBatis最强大之处了,这块的应用主要有四个方面if,choose,trim和foreach,接下来先说说if. 顾名思义,if是用来判断条件的,现在假设我们有个需求, ...