collect_list/collect_set(列转行)
Hive中collect相关的函数有collect_list和collect_set。
它们都是将分组中的某列转为一个数组返回,不同的是collect_list不去重而collect_set去重。
做简单的实验加深理解,创建一张实验用表,存放用户每天点播视频的记录:
|
1
2
3
4
5
|
create table t_visit_video ( username string, video_name string) partitioned by (day string)row format delimited fields terminated by ','; |
在本地文件系统创建测试数据文件:
|
1
2
3
4
5
6
7
8
|
张三,大唐双龙传李四,天下无贼张三,神探狄仁杰李四,霸王别姬李四,霸王别姬王五,机器人总动员王五,放牛班的春天王五,盗梦空间 |
将数据加载到Hive表:
|
1
|
load data local inpath '/root/hive/visit.data' into table t_visit_video partition (day='20180516'); |
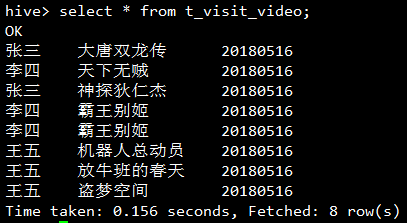
按用户分组,取出每个用户每天看过的所有视频的名字:
|
1
|
select username, collect_list(video_name) from t_visit_video group by username ; |

但是上面的查询结果有点问题,因为霸王别姬实在太好看了,所以李四这家伙看了两遍,这直接就导致得到的观看过视频列表有重复的,所以应该增加去重,使用collect_set,其与collect_list的区别就是会去重:
|
1
|
select username, collect_set(video_name) from t_visit_video group by username; |

李四的观看记录中霸王别姬只出现了一次,实现了去重效果。
突破group by限制
还可以利用collect来突破group by的限制,Hive中在group by查询的时候要求出现在select后面的列都必须是出现在group by后面的,即select列必须是作为分组依据的列,但是有的时候我们想根据A进行分组然后随便取出每个分组中的一个B,代入到这个实验中就是按照用户进行分组,然后随便拿出一个他看过的视频名称即可:
|
1
|
select username, collect_list(video_name)[0] from t_visit_video group by username; |

video_name不是分组列,依然能够取出这列中的数据。
collect_list/collect_set(列转行)的更多相关文章
- hive行转列,列转行
实例一:来源: https://www.cnblogs.com/kimbo/p/6208973.html 行转列 (对某列拆分,一列拆多行) 使用函数:lateral view explode(spl ...
- Databricks 第11篇:Spark SQL 查询(行转列、列转行、Lateral View、排序)
本文分享在Azure Databricks中如何实现行转列和列转行. 一,行转列 在分组中,把每个分组中的某一列的数据连接在一起: collect_list:把一个分组中的列合成为数组,数据不去重,格 ...
- Hive(八)【行转列、列转行】
目录 一.行转列 相关函数 concat concat_ws collect_set collect_list 需求 需求分析 数据准备 写SQL 二.列转行 相关函数 split explode l ...
- 大数据学习day28-----hive03------1. null值处理,子串,拼接,类型转换 2.行转列,列转行 3. 窗口函数(over,lead,lag等函数) 4.rank(行号函数)5. json解析函数 6.jdbc连接hive,企业级调优
1. null值处理,子串,拼接,类型转换 (1) 空字段赋值(null值处理) 当表中的某个字段为null时,比如奖金,当你要统计一个人的总工资时,字段为null的值就无法处理,这个时候就可以使用N ...
- hive SQL 行转列 和 列转行
一.行转列的使用 1.问题 hive如何将 a b 1a b 2a b 3c d 4c d ...
- Hive之行转列与列转行
行转列 原始数据: 需求: 把星座和血型一样的人归类到一起.结果如下: 射手座,A 大海|凤姐 白羊座,A 孙悟空|猪八戒 白羊座,B 宋宋 实现: vi person_info.txt 孙悟空 白羊 ...
- Spark基于自定义聚合函数实现【列转行、行转列】
一.分析 Spark提供了非常丰富的算子,可以实现大部分的逻辑处理,例如,要实现行转列,可以用hiveContext中支持的concat_ws(',', collect_set('字段'))实现.但是 ...
- hive中的列转行和行转列
1.列转行 1.1 相关函数的说明: concat(string1,string,...) //连接括号内字符串,数量不限. concat_ws(separator,string1,string2,. ...
- Oracle行转列、列转行的Sql语句总结
多行转字符串 这个比较简单,用||或concat函数可以实现 SQL Code 12 select concat(id,username) str from app_userselect i ...
- sql的行转列(PIVOT)与列转行(UNPIVOT)
在做数据统计的时候,行转列,列转行是经常碰到的问题.case when方式太麻烦了,而且可扩展性不强,可以使用 PIVOT,UNPIVOT比较快速实现行转列,列转行,而且可扩展性强 一.行转列 1.测 ...
随机推荐
- 删除CSDN点击“阅读更多”按钮跳转到登录界面的功能
manifest.json { "manifest_version": 2, "name": "Helper2", "versio ...
- sphinx-doc的中文搜索
第一,你的系统需要安装jieba类库, pip install jieba 第二,接下来修改sphinx的conf.py文件,为项目设置为中文的搜索配置. # Language to be used ...
- SSAS 内部错误:操作未能成功
错误 -1056964601 : 内部错误: 操作未能成功,已终止. HY0008 是数据源的问题,设置数据源的虚拟连接就可以了
- 最强大的跨语言调用生成工具:Swig 快速实用教程
swig是一个生成其他高级语言调用c和C++代码的工具,比如,大家都知道java的jni,可能没写过,因为非常麻烦,swig可以帮助生成这样的代码,编译生成的代码后,它会生成java类和c代码文件.分 ...
- SVN设置全局忽略提交文件或者目录
在目录中右击选择TortoiseSVN -> 设置 -> 常规设置 -> 全局忽略样式 修改全局忽略样式(可以设置忽略的文件或者目录,以空格隔开):*.o *.lo *.la *.a ...
- Jenkins获取运行job的用户名
1. Jenkins获取运行job的用户名 需要安装user build vars plugin 插件,然后就可以取到$BUILD_USER_ID变量. user build vars plugin下 ...
- 一个applicationContext 加载错误导致的阻塞解决小结
问题为对接一个sso的验证模块,正确的对接姿势为,接入一个 filter, 然后接入一个 SsoListener . 然而在接入之后,却导致了应用无法正常启动,或者说看起来很奇怪,来看下都遇到什么样的 ...
- 将double或则float类型保留小数
DecimalFormat df=new DecimalFormat("0.0");//“0.00” df.format(price);
- CentOS7+Mono5.2.0.224 +Jexus5.8.3.0 布署 Asp.Net MVC (vs2017)
背景: 比起大神我们只是差远了,只知道一味的找找看,找的资料不少,但真不知道哪一个是正确的. 之前一个文章也写了怎么安装 Jexus 但始终只有是html的静态页面可以asp.net 都不行(http ...
- java提高(2)---正则表达式(1)常用符号
正则表达式---常用符号 首先声明,我这里列表的是经常使用的一些符号,如果你想得到全部,那建议你通过API中,搜索Pattern类,会得到所有符号. 字符类 [abc] a.b 或 c(简单类) [^ ...