HashMap 1.8
1、重要参数
和1.7中的相同,不在赘述。变化之处在于table不在是Entry类型而是Node类型,即1.8中拉链法中的节点类型变为Node。但其实结构并没有发生很大的变化,1.8中的HashMap会引入红黑树来解决Hash表冲突过多带来的退化问题,所以Node不仅仅是链表上的节点也是红黑树上的节点。当然在equal中做了一点优化,即判断equal的时候如果两个引用指向同一个对象那么直接返回相等。
1、构造器
共有四个构造器,根据构造HashMap的时候是否传入具体存储的内容可分为两类。一般使用的时候直接传入HashMap的参数并会传一个Collection进去。
一如1.7,构造器最终都是调用前签名为HashMap(int,float)的构造器。
- int initialCapacity。计算出比initialCapacity大的最小的2的幂作为threshold。同样的懒加载机制,没有设置Capacity更没有新建。不同于1.7的是initalCapacity向上取2幂后的结果作为Capacity,1.8中直接作为threshold。
- float loadFatory。
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and the default load factor (0.75).
*
* @param initialCapacity the initial capacity.
* @throws IllegalArgumentException if the initial capacity is negative.
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
/**
* Constructs a new <tt>HashMap</tt> with the same mappings as the
* specified <tt>Map</tt>. The <tt>HashMap</tt> is created with
* default load factor (0.75) and an initial capacity sufficient to
* hold the mappings in the specified <tt>Map</tt>.
*
* @param m the map whose mappings are to be placed in this map
* @throws NullPointerException if the specified map is null
*/
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
2、put
老大难的put方法,底层调用的是putVal方法。极简主义的编码风格让这段代码看起来晦涩且又长又硬。
内容因为红黑树的引入略有区别,但总体的结构和1.7类似
- 判断是否是第一次使用HashMap,如果是那么就先初始化table。
- 把Key为Null的KV对放在同一个地方
- 放入节点
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i; (1)
if ((tab = table) == null || (n = tab.length) == 0) (2)
n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
(1):声明了一些变量为了后续使用,包括代表数组的tab,新插入节点p,以及两个整形变量n i
(2):懒加载机制,不传值的构造器新建HashMap的时候没有创建数组,需要在第一次使用的时候初始化数组
2.1 第一次使用初始化数组
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
当tab为null或者tab的长度为0的时候,需要调用resize方法,resize方法既可以用来初始化一个空的数组也可以用来扩容,这里resize被用来扩容,扩容完毕后n的值为新数组的长度。这里用了两个条件判断是否需要扩容,table==null很好理解,为什么还要tab.length==0呢?
采用无参的构造器新建一个HashMapdebug跟踪扩容的过程,跟踪进入resize方法,因为使用的无参构造器,所以当第一次使用HashMap即没有初始化table的时候,oldTabl=null oldCap=0 oldThr=0,因此resize方法执行到第二个else。


扩容结束后的结果,然后返回。

再次使用指定初始容量的构造器新建HashMap观察扩容过程。指定initialCapacity为15。当第一次来到扩容的时候oldThr变成了16,oldCap由于原始数组没有被初始化所以仍然是0。这个结果和上面分析构造器中initialCapacity的作用相同即作为参考来选择初始Threshold。
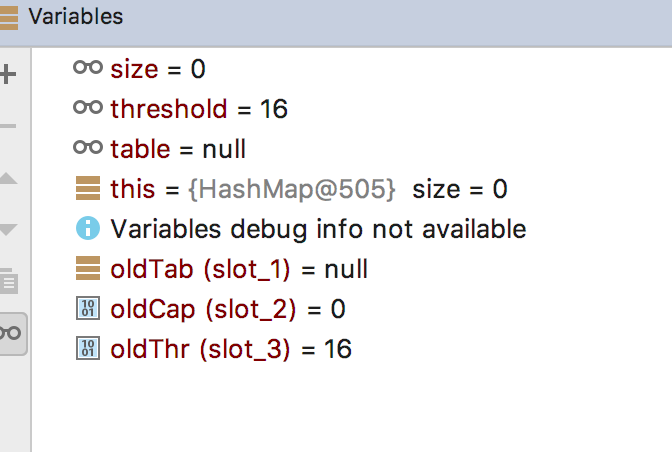
继续往下走,来到rezise的第二个else的时候,新数组的newCap已经是oldThr,看到这里才恍然大悟:initialCapacity果然是用来设置容量的!!!
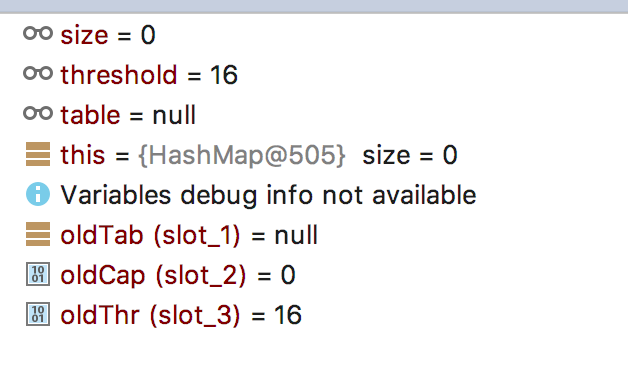
再往下走的结果都和上面相同了根据threshold和newCap计算出newThr,并返回新建的数组。

总结起来在1.8中如果在新建HashMap的时候传入了一个int参数作为数组的容量,它是经过这样一系列过程最终影响到数组的容量。
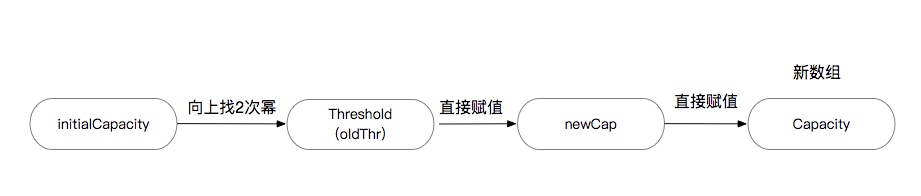
其实从可读性的角度来说,JDK工程师这么起变量名字是有待商榷的,明明是InitialCapacity却赋值给了Threshold。但是从另一个角度来说InitialCapacity只有在初始化数组的时候才会用,也就是说他只使用一次,如果为了只使用一次的变量还单独在HashMap类里存储起来是一种浪费,所以他们通过这种丧失了可读性的方式,换来了内存使用的高效性。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
(1)
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
2.2 没有发生哈希冲突
没有发生哈希冲突直接把新Node放到table[i]处。
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
2.3 发生了哈希冲突
在上一步的if判断中,p指向了table[i]处的节点,在这里又声明了一个e引用。
如果待插入的节点和p指向的节点相同,那么就让e指向p。
如果不相同且p指向的table[i]是树节点,那么就执行插入树节点的方法putTreeVal,并让e指向该方法的返回值。
如果上述都不满足就说明p节点是一个普通的节点,那么和1.7中的思路类似,遍历链表上的节点并找到合适的插入位置,在这一步骤中并没有给引用e赋值。
执行完上述三步后,如果e!=null说明此时存在了一个和待插入节点完全相同的节点,处理逻辑也和1.7相同,用新的值覆盖旧的值并返回旧的值。
HashMap 1.8的更多相关文章
- HashMap与TreeMap源码分析
1. 引言 在红黑树--算法导论(15)中学习了红黑树的原理.本来打算自己来试着实现一下,然而在看了JDK(1.8.0)TreeMap的源码后恍然发现原来它就是利用红黑树实现的(很惭愧学了Ja ...
- HashMap的工作原理
HashMap的工作原理 HashMap的工作原理是近年来常见的Java面试题.几乎每个Java程序员都知道HashMap,都知道哪里要用HashMap,知道HashTable和HashMap之间 ...
- 计算机程序的思维逻辑 (40) - 剖析HashMap
前面两节介绍了ArrayList和LinkedList,它们的一个共同特点是,查找元素的效率都比较低,都需要逐个进行比较,本节介绍HashMap,它的查找效率则要高的多,HashMap是什么?怎么用? ...
- Java集合专题总结(1):HashMap 和 HashTable 源码学习和面试总结
2017年的秋招彻底结束了,感觉Java上面的最常见的集合相关的问题就是hash--系列和一些常用并发集合和队列,堆等结合算法一起考察,不完全统计,本人经历:先后百度.唯品会.58同城.新浪微博.趣分 ...
- 学习Redis你必须了解的数据结构——HashMap实现
本文版权归博客园和作者吴双本人共同所有,转载和爬虫请注明原文链接博客园蜗牛 cnblogs.com\tdws . 首先提供一种获取hashCode的方法,是一种比较受欢迎的方式,该方法参照了一位园友的 ...
- HashMap与HashTable的区别
HashMap和HashSet的区别是Java面试中最常被问到的问题.如果没有涉及到Collection框架以及多线程的面试,可以说是不完整.而Collection框架的问题不涉及到HashSet和H ...
- JDK1.8 HashMap 源码分析
一.概述 以键值对的形式存储,是基于Map接口的实现,可以接收null的键值,不保证有序(比如插入顺序),存储着Entry(hash, key, value, next)对象. 二.示例 public ...
- HashMap 源码解析
HashMap简介: HashMap在日常的开发中应用的非常之广泛,它是基于Hash表,实现了Map接口,以键值对(key-value)形式进行数据存储,HashMap在数据结构上使用的是数组+链表. ...
- java面试题——HashMap和Hashtable 的区别
一.HashMap 和Hashtable 的区别 我们先看2个类的定义 public class Hashtable extends Dictionary implements Map, Clonea ...
- 再谈HashMap
HashMap是一个高效通用的数据结构,它在每一个Java程序中都随处可见.先来介绍些基础知识.你可能也知 道,HashMap使用key的hashCode()和equals()方法来将值划分到不同的桶 ...
随机推荐
- 在Java中进行序列化和反序列化
对象序列化的目标是将对象保存在磁盘中,或者允许在网络中直接传输对象. 对象序列化允许把内存中的Java对象转换成平台无关的二进制流,从而允许把这种二进制流持久保存在磁盘上或者通过网络将这种二进制流传输 ...
- 【 js 工具 】如何在Github Pages搭建自己写的页面?
最近发现 github 改版了,已没有像原来的 Launch automatic page generator 这样的按钮等,所以我对我的文章也进行了修正,对于新版来说,步骤更加简单了.欢迎享用. - ...
- #WEB安全基础 : HTML/CSS | 0x2初识a标签
教你点厉害玩意,尝尝HTML的厉害! 我为了这节课写了一些东西,你来看看
- angular 分页插件的使用
html: <pagination total-items="totalItems" ng-model="currentPage" items-per-p ...
- 【读书笔记】iOS-更改编辑器键的绑定
一,Xcode-->Preferences--->Key Bindings. 参考资料:<Xcode实战开发>
- 16.Odoo产品分析 (二) – 商业板块(9) – 网站生成器(1)
查看Odoo产品分析系列--目录 安装"电子商务"模块时,该模块会自动安装,但网站生成器是电子商务的前提,因此,先分析该模块,在下面就是对电子商务模块的分析. 1. 编辑网站 安装 ...
- 小程序实践(一):主页tab选项实现
官方文档 效果图: 实现底部Tab选项,只需要在项目根目录下的app.json下修改 如图: ----------------------------------------------------- ...
- apache php mysql 安装
推荐参考这里:http://www.myhack58.com/Article/sort099/sort0100/2012/35578_3.htm
- Java synchronized解析
多线程三大特性: 可见性.原子性.有序性 synchronize的特性: 1.同一时刻只有一个线程访问临界资源 2.其它未获取到锁执行权的线程必须排队等待 3.保证共享资源的原子性.可见性和有序性 4 ...
- Testlink1.9.17使用方法( 第三章 初始配置[配置用户、产品] )
第三章 初始配置(配置用户.产品) 一. 设置用户 QQ交流群:585499566 在TestLink系统中,每个用户都可以维护自己的私有信息.admin可以创建用户,但不能看到其它用户的密码.在用户 ...