scrapy暂停和重启,及url去重原理,telenet简单使用
一.scrapy暂停与重启
1.要暂停,就要保留一些中间信息,以便重启读取中间信息并从当前位置继续爬取,则需要一个目录存放中间信息:
scrapy crawl spider_name -s JOBDIR=dir/001——spider_name是你要爬取得spider的py文件名,JOBDIR是命令参数,即代表存放位置参数,dir是中间信息要保存的目录,001新生成的文件夹名是保存的中间信息,重启则读取该文件信息。可以将JOBDIR 设置在setting中,或写在custom_settings中,在Pycharm中都会执行,但是在Pycharm中无法发送ctrl+c,即无法将进程放入后台并暂停。
2.执行命令:scrapy crawl jobbole -s JOBDIR=jobs/001
2.1有可能会报以下错误,这是因为未进入到项目目录(crawl会搜索scrapy.cfg文件):

2.2进入目录正常运行后,ctrl+c暂停进程:
会在jobs下生成一个001文件夹生成如下图文件,request.seen是保存的已经访问了的url,spider.state是spider的状态信息,request.queue中有active.json和p0两个文件,p0是还需要继续做的request(跑完该文件就没有了)


3.重启(也是执行scrapy crawl jobbole -s JOBDIR=jobs/001):
会读取相关信息并继续执行,p0文件会减小,request.seen文件会增大(读取新的request,存入url),两次ctrl+c强制关掉,若需从新爬则可以指定新的文件夹,如jobs/002.
二.scrapy去重原理
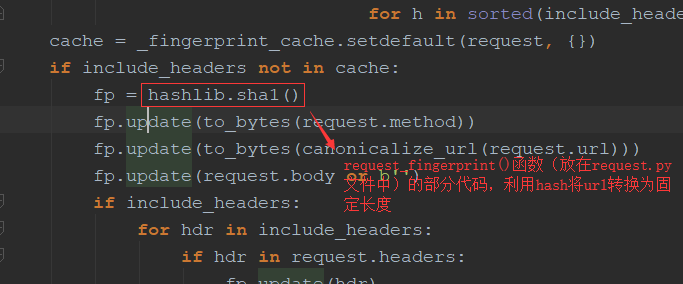
对于每一个url的请求,调度器都会根据请求得相关信息加密(request_fingerprint)得到一个指纹信息,并且将指纹信息和set()集合中的指纹信息进行比对,如果set()集合中已经存在这个数据,就不在将这个Request放入队列中。如果set()集合中没有存在这个加密后的数据,就将这个Request对象放入队列中,等待被调度。

三.telnet的简单使用
1.telnet简介:
Scrapy配有内置的telnet控制台,用于检查和控制Scrapy运行过程。telnet控制台只是在Scrapy进程中运行的常规python shell,所以你可以从中做任何事情。
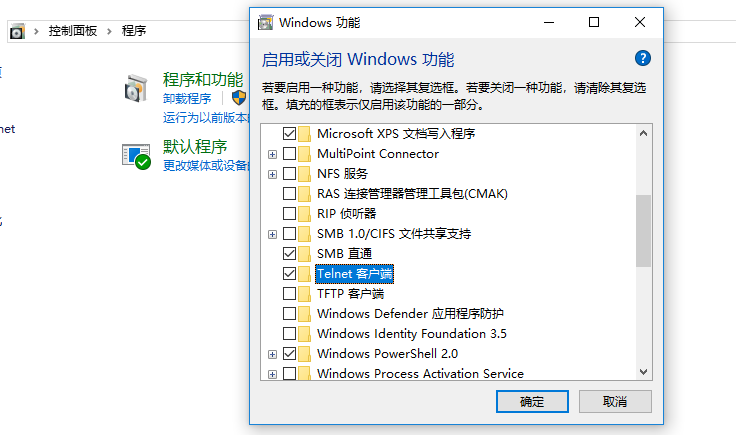
2.windows打开telnet客户端和服务端:
3.telenet连接:
telnet控制台侦听TELNETCONSOLE_PORT设置中定义的TCP端口 ,默认为6023,如下:
telenet localhost 6023
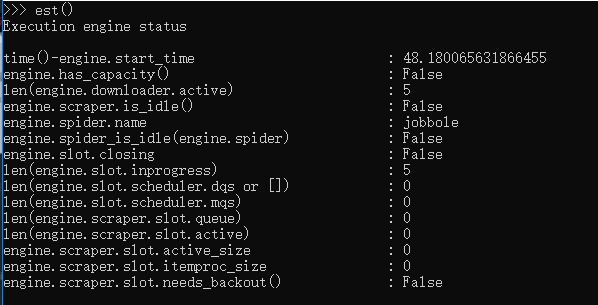
4.telenet简单使用(相当于一个python终端):
变量:

scrapy暂停和重启,及url去重原理,telenet简单使用的更多相关文章
- scrapy 爬虫的暂停与重启
暂停爬虫项目 首先在项目目录下创建一个文件夹用来存放暂停爬虫时的待处理请求url以及其他的信息.(文件夹名称:job_info) 在启动爬虫项目时候用pycharm自带的终端启动输入下面的命令: sc ...
- 第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启 scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的UR ...
- 三十二 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的URL不在爬取 实现暂停与重启记录状态 1.首先cd进入到scrapy项目里 2.在scrapy项 ...
- 【转】larbin中的url去重算法
1.bloom filter算法 传说中,larbin使用bloom filter算法来进行url去重.那我们就先来了解下bloom filter算法好了. [以下转自:http://hi.baidu ...
- [原创]手把手教你写网络爬虫(7):URL去重
手把手教你写网络爬虫(7) 作者:拓海 摘要:从零开始写爬虫,初学者的速成指南! 封面: 本期我们来聊聊URL去重那些事儿.以前我们曾使用Python的字典来保存抓取过的URL,目的是将重复抓取的UR ...
- 爬虫URL去重
这个要看你想抓取的网页数量是哪种规模的.如果是千万以下用hash表, set, 布隆过滤器基本可以解决,如果是海量的......嗯我也没做过海量的,不过hash表之类的就别想了,内存根本不够,分割线下 ...
- URL去重与文章去重的一些基本方法
一.url去重url存到数据库所有url放到set中(一亿条占用9G内存)md5之后放到set中(一亿条占用2,3G的内存)scrapy采用的就是类似方法bitmap方法(url经过hash后映射到b ...
- URL 去重的 6 种方案!(附详细实现代码)
URL 去重在我们日常工作中和面试中很常遇到,比如这些: 可以看出,包括阿里,网易云.优酷.作业帮等知名互联网公司都出现过类似的面试题,而且和 URL 去重比较类似的,如 IP 黑/白名单判断等也经常 ...
- [爬虫学习笔记]基于Bloom Filter的url去重模块UrlSeen
Url Seen用来做url去重.对于一个大的爬虫系统,它可能已经有百亿或者千亿的url,新来一个url如何能快速的判断url是否已经出现过非常关键.因为大的爬虫系统可能一秒钟就会下载 ...
随机推荐
- SpringBoot注册登录(三):注册--验证账号密码是否符合格式及后台完成注册功能
SpringBoot注册登录(一):User表的设计点击打开链接SpringBoot注册登录(二):注册---验证码kaptcha的实现点击打开链接 SpringBoot注册登录(三):注册 ...
- jquery懒加载插件 jquery_lazyload 下载
每天学习一点点 编程PDF电子书.视频教程免费下载:http://www.shitanlife.com/code https://pan.baidu.com/s/1UbOeyL_AaSNN_KMA4M ...
- 【转】dos下 和 批处理中的 for 语句的基本用法
for 语句的基本用法 : 最复杂的for 语句,也有其基本形态,它的模样是这样的: 在cmd 窗口中:for %I in (command1) do command2 在批处理文件中:for % ...
- Python:Day04
数学运算符: + 加 - 减 * 乘 ** 指数运算 / 除 // 整除 % 取余 比较运算符: > 大于 < 小于 >= 大于等于 <= 小于等于 == ...
- ubantu服务器配置ss
阿里云 ubantu16.0(自带pip) 服务端 $ apt-get install python-pip $ pip install shadowsocks $ vim /etc/shadowso ...
- (四)surging 微服务框架使用系列之网关 转载
一.什么是API网关 API网关是一个服务器,是系统对外的唯一入口.API网关封装了系统内部架构,为每个客户端提供一个定制的API.API网关方式的核心要点是,所有的客户端和消费端都通过统一的网关接入 ...
- ORA-19566: exceeded limit of 0 corrupt blocks for file E:\xxxx\<datafilename>.ORA.
How to Format Corrupted Block Not Part of Any Segment (Doc ID 336133.1) To BottomTo Bottom In this D ...
- sql注入的防护
一.严格的数据类型 在Java,C#等高级语言中,几乎不存在数字类型注入,而对于PHP,ASP等弱类型语言,就存在了危险. 防御数字型注入相对简单,如果不需要输入字符型数据,则可以用is_numeri ...
- 线程概念( 线程的特点,进程与线程的关系, 线程和python理论知识,线程的创建)
参考博客: https://www.cnblogs.com/xiao987334176/p/9041318.html 线程概念的引入背景 进程 之前我们已经了解了操作系统中进程的概念,程序并不能单独运 ...
- Insider Dev Tour(2018.06.28)
时间:2018.06.28地点:北京金茂万丽酒店