【Python】直接赋值,深拷贝和浅拷贝
直接赋值: 对象的引用,也就是给对象起别名
浅拷贝: 拷贝父对象,但是不会拷贝对象的内部的子对象。
深拷贝: 拷贝父对象. 以及其内部的子对象
在之前的文章中,提到可变对象和不可变对象,接下来也是以这两者的区别进行展开
直接赋值
对于可变对象和不可变对象,将一个变量直接赋值给另外一个变量,两者 id 值一致,其实本质上是将变量量绑定到对象的过程.
>>> a=1
>>> b=a
>>> id(a) == id(b)
True
>>> c="string"
>>> d=c
>>> id(c) == id(d)
True
>>> e=[1,2,3]
>>> f=e
>>> id(e)==id(f)
True
关于修改新变量的值,对原有变量会产生的影响,在可变对象和不可变对象 中也做了讲述,这里通过几个例子,重新温习一下
不可变对象
>>> x=1
>>> y=x
>>> id(x)==id(y)
True
>>> id(1)==id(y)
True
>>>>>> id(x)
1500143776
>>> y=y+1
>>> y
2
>>> x
1
>>> id(x)==id(y)
False
>>> id(y)
1500143808
>>> id(x)
1500143776
对于不可变对象,修改赋值后的新变量,不会对原有变量造成任何影响.为什么出现这种现象呢?因为不可变对象一旦创建之后就不允许被改变.后面对 y 进行的操作,其实是重新创建一个对象并绑定的结果:
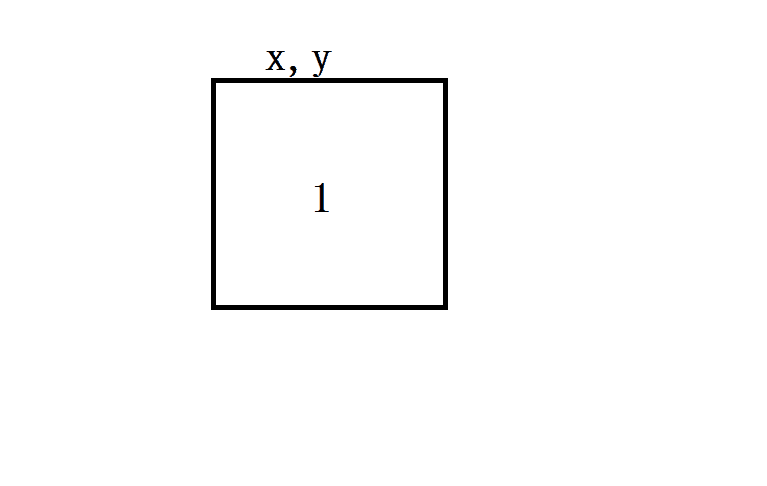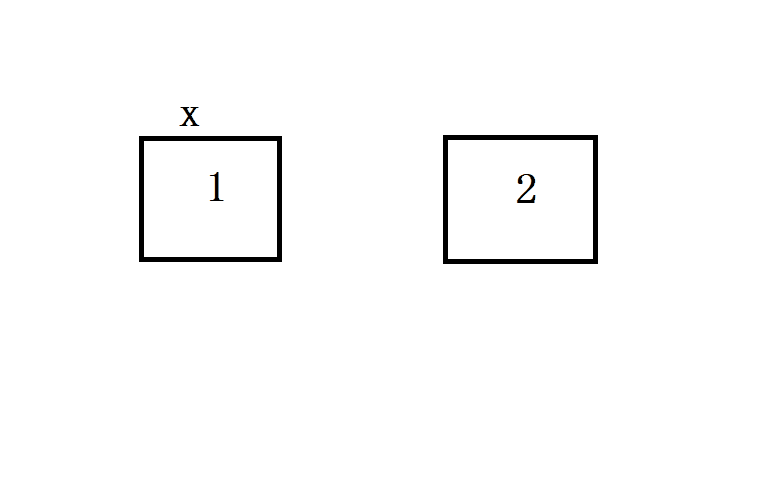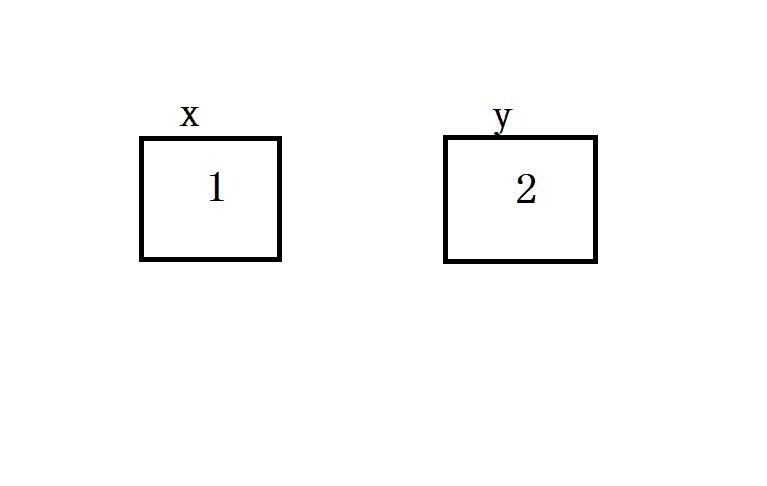
可变对象
>>> m=[1,2,3]
>>> n=m
>>> id(n)==id(m)
True
>>> id(m)
1772066764488
>>> id(n[0])
1772066764656
>>> n[0]=4
>>> n
[4, 2, 3]
>>> m
[4, 2, 3]
>>> id(n)==id(m)
True
>>> id(m)
1772066764488
对于可变对象,修改赋值后的变量,会对原有的变量造成影响,会导致其 value 值的改变,但是其 id 值保持不变
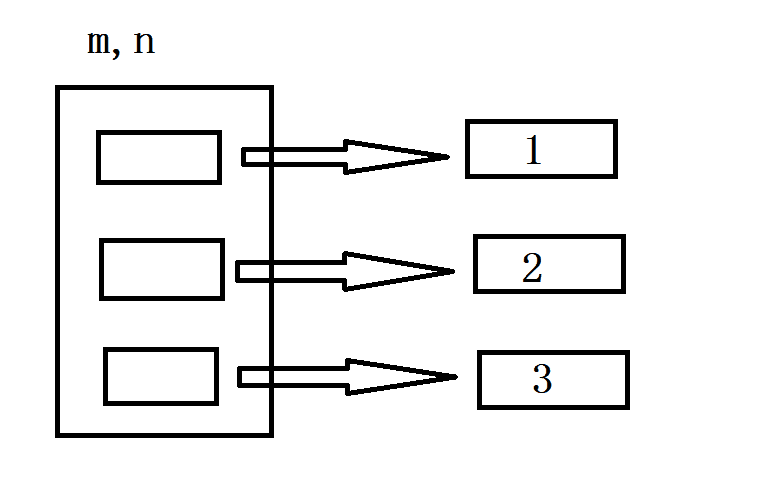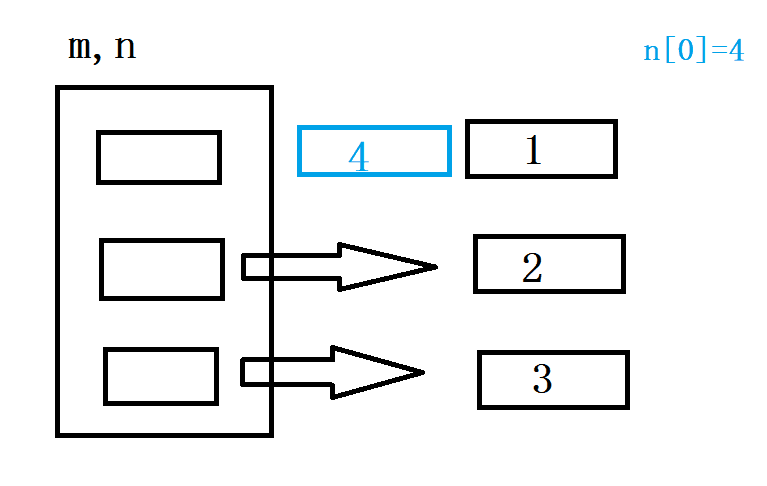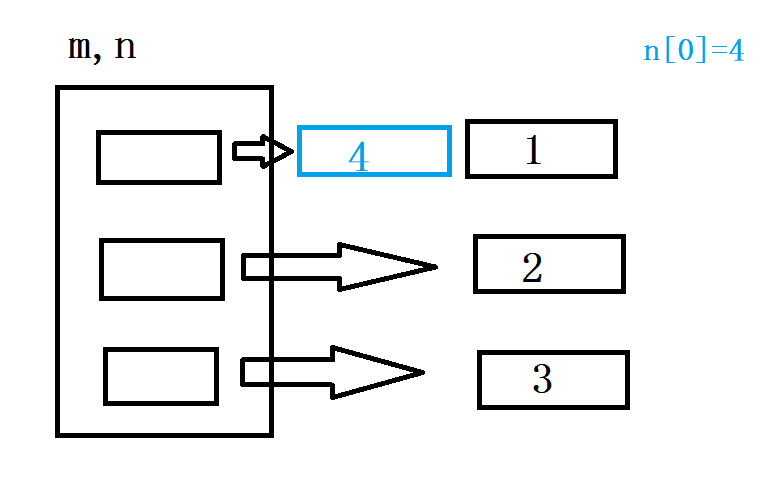
从上图不难看出,这个时候的 id(n[0]) 的值,和未修改前的 id值应该不一样,可以输出看一下
>>>id(n[0])
1772066764752 # 最初没有修改前是 1772066764656
n[0] 修改前后为什么 id 值出现改变呢? 首先需要明确一点 n[0] 绑定的是一个不可变对象,在文章的最初提到,不可变对象一旦创建就不允许修改.显然对 n[0] 进行修改,不能在绑定对象的内存上进行修改,那如何实现重新赋值呢?只能创建一个新的对象 4 ,然后将 n[0] 绑定到新的对象
浅拷贝和深拷贝
先看一下官方文档的定义
The difference between shallow and deep copying is only relevant for compound objects (objects that contain other objects, like lists or
class instances).
A shallow copy constructs a new compound object and then (to the
extent possible) inserts the same objects into it that the
original contains.
A deep copy constructs a new compound object and then, recursively,inserts copies into it of the objects found in the original.
从文档中不难看出,上面提到深拷贝和浅拷贝两者区别在于在复合对象,那接下来也只讨论复合对象.
浅拷贝
注意到官方文档也提到对浅拷贝和深拷贝的定义,从上文中不难看出,浅拷贝构建一个复合对象,然后将原有复合对象包含的对象插入到新的复合对象中
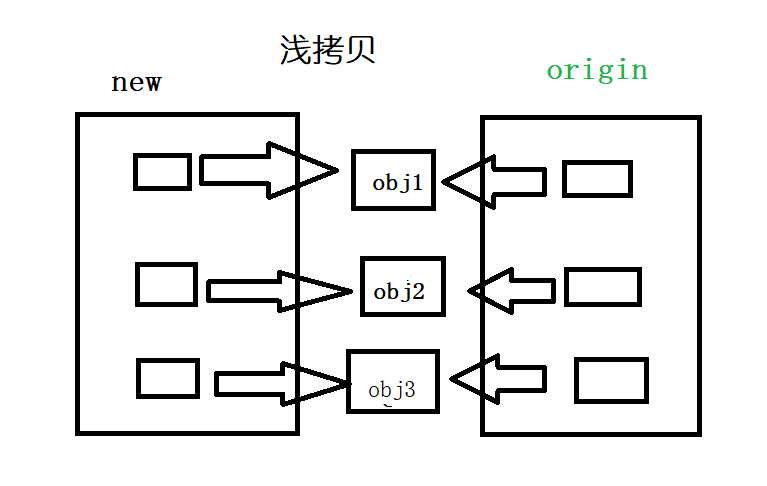
从上图不难看出,浅拷贝后,新复合对象包含的对象(可变或者不可变)的 id 值和原有对象包含的对象的 id 值相同
看一下具体例子:
>>> import copy
>>> a=[1,2,[3,4]]
>>> b=copy.copy(a)
>>> id(b[0])==id(a[0])
True
>>> id(b[2])==id(a[2])
True
>>> id(b[2][0])==id(a[2][0])
True
现在让我们试着修改一下浅拷贝后的 b 的值,在修改前,可以先思考一下,如果修改 b[0] 可能会发生什么?
由于 b[0] = 1,很显然 1 属于不可变对象,那么根据对不可变变量修改的规则,则 b[0] 会绑定到新的变量上,而 a[0] 的由于没有修改,则保持不变,真的是这样吗?让我们验证一下
>>> b[0]=5
>>> b
[5, 2, [3, 4]]
>>> a
[1, 2, [3, 4]]
接下来我们要尝试修改一下 b[2],由于 b[2] 绑定的对象是 list,属于可变对象,按照上面说的可变对象修改的规则,则修改后的 b[2] 的 id 值保持不变,但是其 value 值会发生改变. 同样的让我们通过例子验证一下
>>> id(b[2])
4300618568
>>> b[2][0]=6
>>> id(b[2])
4300618568
>>> b
[5, 2, [6, 4]]
>>> a
[1, 2, [6, 4]]
由于 b[2] 和 a[2] 绑定同一个可变对象,很显然对 b[2] 的修改同样会映射到 a[2] 上
深拷贝
深拷贝构建一个复合对象,然后递归的将原有复合包含的对象的副本插入到新的复合对象中
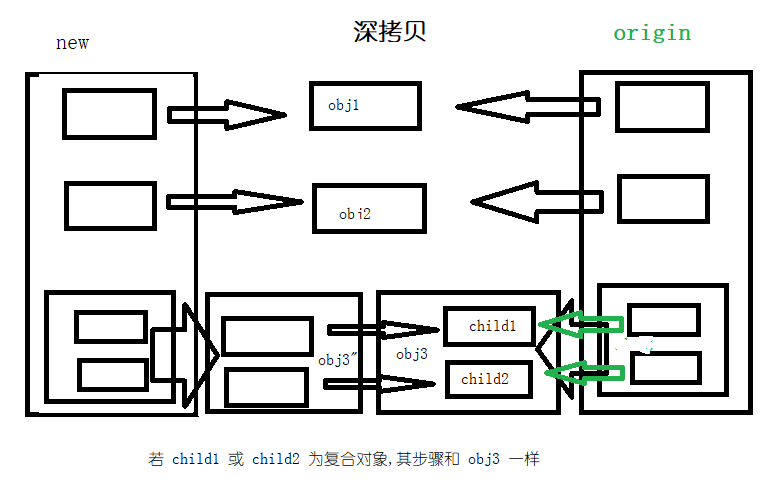
若上图所示,深拷贝后,新的复合对象包含的对象,若对象为不可变对象,则 id 值保持不变,若对象为可变对象,则 id 值发生改变
看一个例子:
>>> import copy
>>> a=[1,2,[3,4]]
>>> b=copy.deepcopy(a)
>>> id(b[0])==id(a[0])
True
>>> id(b[2])==id(a[0])
False
>>> id(b[2][0])==id(a[2][0])
True
接下来让我们修改一下变量 b,这里就不在修改不可变对象 b[0] 和 b[1] 了,因为结果很明显,对 a 不会产生任何影响,我们来修改 b[2],那么修改 b[2] 会对 a[2] 产生影响吗?很明显答案是不会,因为深拷贝就相当于克隆出了一个全新的个体,两者不再有任何关系
>>> b[2][0]=5
>>> b
[1, 2, [5, 4]]
>>> a
[1, 2, [3, 4]]
【Python】直接赋值,深拷贝和浅拷贝的更多相关文章
- **Python中的深拷贝和浅拷贝详解
Python中的深拷贝和浅拷贝详解 这篇文章主要介绍了Python中的深拷贝和浅拷贝详解,本文讲解了变量-对象-引用.可变对象-不可变对象.拷贝等内容. 要说清楚Python中的深浅拷贝,需要 ...
- python中的深拷贝与浅拷贝
深拷贝和浅拷贝 浅拷贝的时候,修改原来的对象,浅拷贝的对象不会发生改变. 1.对象的赋值 对象的赋值实际上是对象之间的引用:当创建一个对象,然后将这个对象赋值给另外一个变量的时候,python并没有拷 ...
- 浅谈python 复制(深拷贝,浅拷贝)
博客参考:点击这里 python中对象的复制以及浅拷贝,深拷贝是存在差异的,这儿我们主要以可变变量来演示,不可变变量则不存在赋值/拷贝上的问题(下文会有解释),具体差异如下文所示 1.赋值: a=[1 ...
- python中的深拷贝和浅拷贝
python的复制,深拷贝和浅拷贝的区别 在python中,对象赋值实际上是对象的引用.当创建一个对象,然后把它赋给另一个变量的时候,python并没有拷贝这个对象,而只是拷贝了这个对象的引用 一 ...
- 001 说说Python中的深拷贝和浅拷贝
在Python编程中忽略深拷贝和浅拷贝可能会造成未知的风险. 比如我们打算保存一份原始对象的副本作为上一状态的记录,此后修改原始对象数据时,若是副本对象的数据也发生改变,那么这就是一个严重的错误. 注 ...
- Python 对象的深拷贝与浅拷贝 -- (转)
本文内容是在<Python核心编程2>上看到的,感觉很有用便写出来,给大家参考参考! 浅拷贝 首先我们使用两种方式来拷贝对象,一种是切片,另外一种是工厂方法.然后使用id函数来看看它们的标 ...
- Python list的深拷贝和浅拷贝
深拷贝和浅拷贝 列表存储数据,列表拷贝就是数据备份 浅拷贝 优点:占用内存较少 缺点:修改深层数据,会影响原数据 深拷贝 优点:修改数据,互不影响 缺点:占用内存较大 ""&quo ...
- Python赋值语句与深拷贝、浅拷贝的区别
参考:http://stackoverflow.com/questions/17246693/what-exactly-is-the-difference-between-shallow-copy-d ...
- python中的深拷贝和浅拷贝理解
在python中,对象赋值实际上是对象的引用.当创建一个对象,然后把它赋给另一个变量的时候,python并没有拷贝这个对象,而只是拷贝了这个对象的引用.以下分两个思路来分别理解浅拷贝和深拷贝: 利用切 ...
随机推荐
- 线性表 & 散列表
线性表: 数据排成一条线一样的机构,每个线性表上的数据最多只有前后两个方向, 包括 数组,链表,队列,栈. 非线性表 : 数据之间并不是简单的前后关系,有二叉树.图等. 散列表(基于 数组支持按照下标 ...
- matplotlib 示例
示例1 import numpy as np import matplotlib.pyplot as plt #plt.rcParams['font.family'] = ['sans-serif'] ...
- 【Spring Cloud 系列】 二、Spring Cloud Eureka 的第一印象
Eureka : 翻译翻译,找到了!(惊讶语气) Spring CLoud 中的 Spring Cloud Eureka,用于 分布式项目中的服务治理.是对Netflix 套件中的Eureka 的二次 ...
- 在SpringMVC获取客户端传递的数据的方式
在处理请求的方法中,加入相对应的形参,保证形参参数名和传递的数据的参数名保持一致,就能够自动赋值 value:当不满足赋值条件时,可以使用value属性,指定映射关系 required:设置形参是否必 ...
- CocosCreator实现微信排行榜
1. 概述 不管是在现实生活还是当今游戏中,各式各样的排名层出不穷.如果我们做好一款游戏,却没有实现排行榜,一定是不完美的.排行榜不仅是玩家了解自己实力的途径,也是游戏运营刺激用户留存的一种途径.在微 ...
- IDEA优化内存配置,可提高启动和运行速度
找到IDEA安装的bin目录 打开idea.exe.vmoptions 文件 关键的三个参数的说明 1. -Xms 是最小启动内存参数 2. -Xmx 是最大运行内存参数 3.-XX:Reserved ...
- mysql HAVING用法
原文链接:https://www.cnblogs.com/mr-wuxiansheng/p/11188733.html having字句可以让我们筛选分组之后的各种数据,where字句在聚合前先筛选记 ...
- HotCorner-让Windows 10拥有macOS的触发角特性!
目录 简介 软件功能 下载 安装 卸载 使用 License 作者 FAQ 简介 macOS上有一个很方便的功能:"触发角".通过这个功能可以设置当鼠标移动到屏幕的四个角时的触发事 ...
- OpenCV开发笔记(六十四):红胖子8分钟带你深入了解SURF特征点(图文并茂+浅显易懂+程序源码)
若该文为原创文章,未经允许不得转载原博主博客地址:https://blog.csdn.net/qq21497936原博主博客导航:https://blog.csdn.net/qq21497936/ar ...
- 大众点评cat实时监控简介及部署
简介 背景 CAT(Central Application Tracking)是由吴其敏(前大众点评首席架构师,现携程架构负责人)主导设计基于Java开发打造的实时应用监控平台,为大众点评网提供了全面 ...