Kmeans聚类算法原理与实现
Kmeans聚类算法
1 Kmeans聚类算法的基本原理
K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
假设要把样本集分为k个类别,算法描述如下:
(1)适当选择k个类的初始中心,最初一般为随机选取;
(2)在每次迭代中,对任意一个样本,分别求其到k个中心的欧式距离,将该样本归到距离最短的中心所在的类;
(3)利用均值方法更新该k个类的中心的值;
(4)对于所有的k个聚类中心,重复(2)(3),类的中心值的移动距离满足一定条件时,则迭代结束,完成分类。
Kmeans聚类算法原理简单,效果也依赖于k值和类中初始点的选择。
2 算法结构与实现方法
Kmeans算法相对比较简单,本次算法实现采用C++语言,作为面向对象设计语言,为保证其良好的封装性以及代码重用性。软件包含三个部分,即kmeans.h,kmeans.cpp和main.cpp。
在kmeans.h中,首先定义一个类,class KMeans,由于本算法实现需要对外部数据进行读取和存储,一次定义了一个容器Vector,其中数据类型为结构体st_point,包含三维点坐标以及一个char型的所属类的ID。其次为函数的声明。
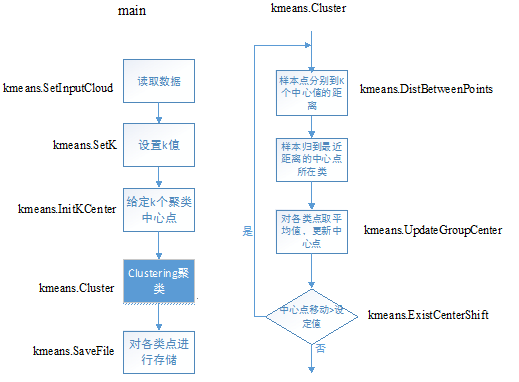 图4.1 程序基本机构与对应函数
图4.1 程序基本机构与对应函数
在kmeans.cpp中具体给出了不同功能的公有函数,如图_1中所示,函数比较细化,便于后期应用的扩展,比较具体是聚类函数:cluster,其中严格根据kmeans基本原理,聚类的相似度选用的是最简单的欧式距离,而迭代的结束判定条件选用两次中心值之间的偏差是否大于给定Dist_near_zero值。具体参见程序源代码。
3 数据描述
本次算法实验采用数据为三维点云数据,类似于实验室中三维激光扫描仪器所采得数据,形式上更为简单,整齐有规律,在cloudcompare中显示出来,如下图:

图4.2 数据原始图
数据为三维坐标系下的三个点云集,分别为球体,园面以及正方体,而test.txt文件中是一组三维的点集,是混乱的,聚类算法要做的便是将其中分类存储起来。很自然的,聚类中K值选择了3。
在软件实现时,建立了一个含有结构体类型的容器,对原始数据进行读取。
typedef struct st_point
{ st_pointxyz pnt; //st_pointxyz 为三维点结构类型数据 stru st_pointxyz
int groupID;
st_point () { }
st_point(st_pointxyz &p, int id)
{pnt = p;
groupID = id;
}
}st_point;
该数据结构类型中包含三维点数据以及所分类的ID,数据容器为vector<st_point>。
4 算法描述与源码分析
本节重点分析项目中culster聚类函数的具体代码,由于C++语言较适用于大型程序编写,本算法又相对简单,因此未免冗长,具体完整程序见项目源程序。下面只分析Kmeans原理中(2)(3)步骤的程序实现。
如下面程序源代码:
bool KMeans::Cluster()
{
std::vector<st_pointxyz> v_center(mv_center.size()); do
{
for (int i = , pntCount = mv_pntcloud.size(); i < pntCount; ++i)
{
double min_dist = DBL_MAX;
int pnt_grp = ;
for (int j = ; j < m_k; ++j)
{
double dist = DistBetweenPoints(mv_pntcloud[i].pnt, mv_center[j]);
if (min_dist - dist > 0.000001)
{
min_dist = dist;
pnt_grp = j;
}
}
m_grp_pntcloud[pnt_grp].push_back(st_point(mv_pntcloud[i].pnt, pnt_grp));
} //保存上一次迭代的中心点
for (size_t i = ; i < mv_center.size(); ++i)
{
v_center[i] = mv_center[i];
} if (!UpdateGroupCenter(m_grp_pntcloud, mv_center))
{
return false;
}
if (!ExistCenterShift(v_center, mv_center))
{
break;
}
for (int i = ; i < m_k; ++i){
m_grp_pntcloud[i].clear();
} } while (true); return true;
}
5 算法结果分析
原数据文件test.txt中的数据被分为三类,分别存储在文件k_1,k_2,k_3中,我们对三个聚类后所得数据点云进行颜色添加后显示在cloudcompare上,得下面的显示图:

图4.3 Kmeans聚类结果
上图是在给定的初始三个聚类中心点为{ 0, 0, 0 },{ 2.5, 2.5, 2.5 },{ 3, 3, -3 }的情况下得到的结果。这是比较理想的,再看下图:

图4.4 改变初始聚类中心后的结果
本结果对应的初始三个中心点为{ 2, 2, 2 },{ -2.5, 2.5, 2.5 },{ 3, -3, -3 },很明显,数据聚类并不理想,这说明K-Means算法一定程度上初始聚类种子点,这个聚类种子点太重要,不同的随机种子点会有得到完全不同的结果。
上面改动了初始点,下面给出当k=4的聚类结果,分别取了两组不同的初始点集:

图4.5.1 k=4聚类结果1

图4.5.2 k=4聚类结果
由上述聚类结果可知,当k增加时,选取聚类初始点合适,可以得到满意的结果,如5_1所示,与最初结果相比只是将球点云聚类成了两部分,而5_2与5_1相比结果很不理想,由颜色可以看出,图中只有两类,另外两类是空的,说明k值不当,初始值不当的情况下,聚类是会失败的。
综上实验结果分析可以看出,kmeans聚类算法是一类非常快捷的聚类算法,效果也很明显,局部性较好,容易并行化,对大规模数据集很有意义。但比较依赖于k值得选定与初始聚类中心点的选择,所以该算法比较适合有人工参与的较大型聚类场合。
工程源码:http://pan.baidu.com/s/1ntN6Pjb
Kmeans聚类算法 - 开源中国社区 http://www.oschina.net/code/snippet_588162_50491
参考文献
[1] Hartigan J A, Wong M A. Algorithm AS 136: A k-means clustering algorithm[J]. Applied statistics, 1979: 100-108.
Kmeans聚类算法原理与实现的更多相关文章
- 【转】K-Means聚类算法原理及实现
k-means 聚类算法原理: 1.从包含多个数据点的数据集 D 中随机取 k 个点,作为 k 个簇的各自的中心. 2.分别计算剩下的点到 k 个簇中心的相异度,将这些元素分别划归到相异度最低的簇.两 ...
- K-Means 聚类算法原理分析与代码实现
前言 在前面的文章中,涉及到的机器学习算法均为监督学习算法. 所谓监督学习,就是有训练过程的学习.再确切点,就是有 "分类标签集" 的学习. 现在开始,将进入到非监督学习领域.从经 ...
- 第十三篇:K-Means 聚类算法原理分析与代码实现
前言 在前面的文章中,涉及到的机器学习算法均为监督学习算法. 所谓监督学习,就是有训练过程的学习.再确切点,就是有 "分类标签集" 的学习. 现在开始,将进入到非监督学习领域.从经 ...
- K-Means聚类算法原理
K-Means算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛.K-Means算法有大量的变体,本文就从最传统的K-Means算法讲起,在其基础上讲述K-Means的优化变体 ...
- 机器学习中K-means聚类算法原理及C语言实现
本人以前主要focus在传统音频的软件开发,接触到的算法主要是音频信号处理相关的,如各种编解码算法和回声消除算法等.最近切到语音识别上,接触到的算法就变成了各种机器学习算法,如GMM等.K-means ...
- 03-01 K-Means聚类算法
目录 K-Means聚类算法 一.K-Means聚类算法学习目标 二.K-Means聚类算法详解 2.1 K-Means聚类算法原理 2.2 K-Means聚类算法和KNN 三.传统的K-Means聚 ...
- BIRCH聚类算法原理
在K-Means聚类算法原理中,我们讲到了K-Means和Mini Batch K-Means的聚类原理.这里我们再来看看另外一种常见的聚类算法BIRCH.BIRCH算法比较适合于数据量大,类别数K也 ...
- 一步步教你轻松学K-means聚类算法
一步步教你轻松学K-means聚类算法(白宁超 2018年9月13日09:10:33) 导读:k-均值算法(英文:k-means clustering),属于比较常用的算法之一,文本首先介绍聚类的理 ...
- 图像处理中kmeans聚类算法C++实现
Kmeans聚类算法是十分常用的聚类算法,给定聚类的数目N,Kmeans会自动在样本数据中寻找N个质心,从而将样本数据分为N个类别.下面简要介绍Kmeans聚类原理,并附上自己写的Kmeans聚类算法 ...
随机推荐
- C#中委托演变的的三个阶段
命名函数 匿名方法 lambda表达式 委托是一种可以把引用存储为函数的类型,定义了委托后,就可以声明该委托类型的变量,接着把这个变量初始化为与委托有相同返回类型和参数列表的函数引用,之后就可以使用委 ...
- STL---deque(双端队列)
Deque是一种优化了的.对序列两端元素进行添加和删除操作的基本序列容器.它允许较为快速地随机访问,但它不像vector 把所有的对象保存在一块连续的内存块,而是采用多个连续的存储块,并且在一个映射结 ...
- Django CRM __contains与__icontains区别
http://www.yihaomen.com/article/python/199.htm operators = { 'exact': '= %s', 'iexact': 'LIKE %s', ' ...
- struts2 模型驱动
public class User3Action extends ActionSupport implements ModelDriven<User> { private User use ...
- MySQL表中数据的迁移
INSERT INTO `crm_attachment`(OPERATOR_ID,ATTACHMENT_ID,TYPE ) SELECT APPLICATION_ID ,ATTACHMENT_ID,' ...
- cxGrid的使用方法
来源 http://www.cnblogs.com/djcsch2001/archive/2010/07/19/1780573.html 1. 去掉GroupBy栏 cxGrid1DBTable ...
- ABAP 单位转换函数
CALL FUNCTION 'UNIT_CONVERSION_SIMPLE' EXPORTING input = wa_all-btg ...
- [转]Android下拉刷新完全解析,教你如何一分钟实现下拉刷新功能
版权声明:本文出自郭霖的博客,转载必须注明出处. 转载请注明出处:http://blog.csdn.net/guolin_blog/article/details/9255575 最近项目中需要用到L ...
- Effective C++ -----条款42:了解typename的双重意义
声明template参数时,前缀关键字class和typename可互换. 请使用关键字typename标识嵌套从属类型名称:但不得在base class lists(基类列)或member init ...
- 【编程题目】输入一个单向链表,输出该链表中倒数第 k 个结点
第 13 题(链表):题目:输入一个单向链表,输出该链表中倒数第 k 个结点.链表的倒数第 0 个结点为链表的尾指针.链表结点定义如下: struct ListNode {int m_nKey;Lis ...