Spark学习进度11-Spark Streaming&Structured Streaming
Spark Streaming
Spark Streaming 介绍
批量计算

流计算

Spark Streaming 入门
Netcat 的使用

项目实例
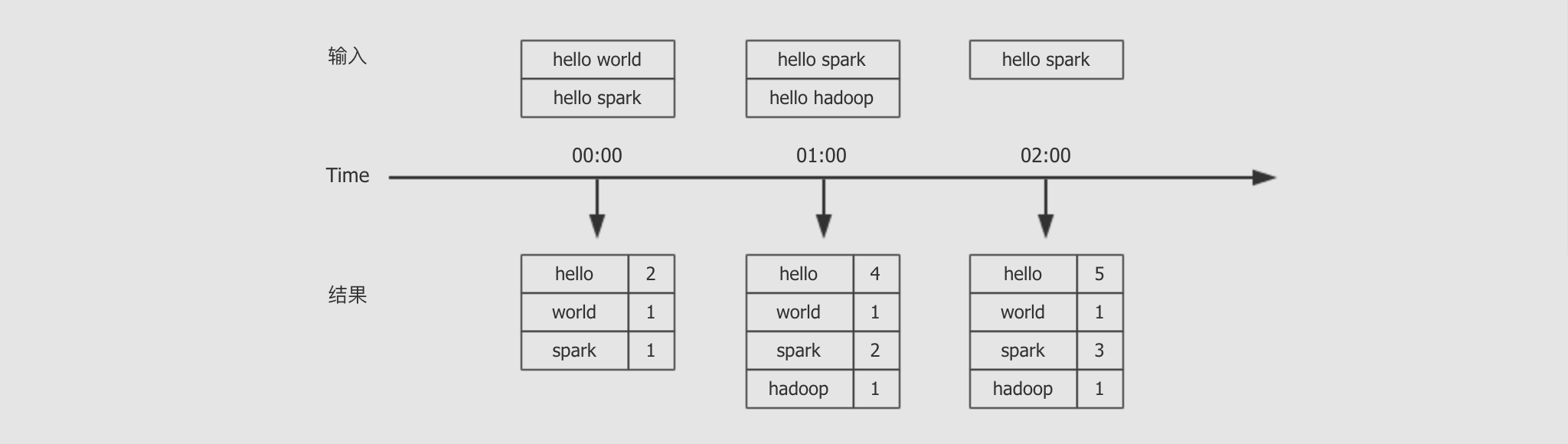
目标:使用 Spark Streaming 程序和 Socket server 进行交互, 从 Server 处获取实时传输过来的字符串, 拆开单词并统计单词数量, 最后打印出来每一个小批次的单词数量

步骤:
package cn.itcast.streaming import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext} object StreamingWordCount { def main(args: Array[String]): Unit = {
//1.初始化
val sparkConf=new SparkConf().setAppName("streaming").setMaster("local[2]")
val ssc=new StreamingContext(sparkConf,Seconds(5))
ssc.sparkContext.setLogLevel("WARN") val lines: ReceiverInputDStream[String] = ssc.socketTextStream(
hostname = "192.168.31.101",
port = 9999,
storageLevel = StorageLevel.MEMORY_AND_DISK_SER
)
//2.数据处理
//2.1把句子拆单词
val words: DStream[String] =lines.flatMap(_.split(" "))
val tuples: DStream[(String, Int)] =words.map((_,1))
val counts: DStream[(String, Int)] =tuples.reduceByKey(_+_) //3.展示
counts.print() ssc.start() ssc.awaitTermination() } }
开始进行交互:
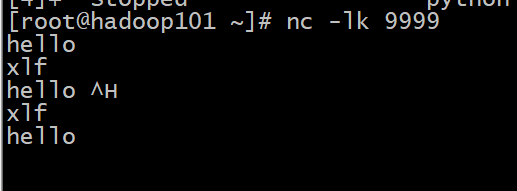
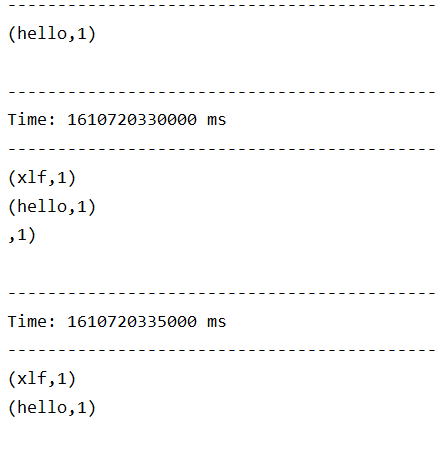
注意:
Spark Streaming 并不是真正的来一条数据处理一条
Spark Streaming 的处理机制叫做小批量, 英文叫做 mini-batch, 是收集了一定时间的数据后生成 RDD, 后针对 RDD 进行各种转换操作, 这个原理提现在如下两个地方
- 控制台中打印的结果是一个批次一个批次的, 统计单词数量也是按照一个批次一个批次的统计
- 多长时间生成一个
RDD去统计呢? 由new StreamingContext(sparkConf, Seconds(1))这段代码中的第二个参数指定批次生成的时间
Spark Streaming 中至少要有两个线程
在使用 spark-submit 启动程序的时候, 不能指定一个线程
- 主线程被阻塞了, 等待程序运行
- 需要开启后台线程获取数据
各种算子
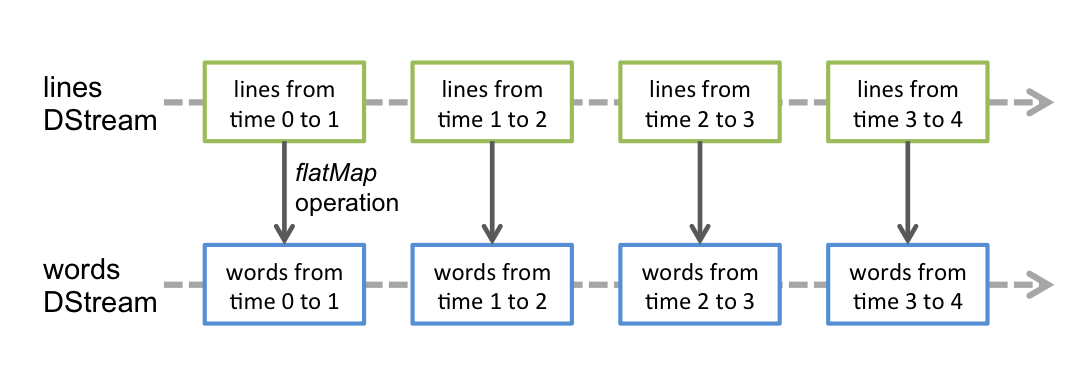
这些算子类似
RDD, 也会生成新的DStream这些算子操作最终会落到每一个
DStream生成的RDD中
| 算子 | 释义 |
|---|---|
|
|
将一个数据一对多的转换为另外的形式, 规则通过传入函数指定 |
|
|
一对一的转换数据 |
|
|
这个算子需要特别注意, 这个聚合并不是针对于整个流, 而是针对于某个批次的数据 |
Structured Streaming
Spark 编程模型的进化过程
| 编程模型 | 解释 |
|---|---|
|
|
|
|
|
|
|
|
|
Spark Streaming 和 Structured Streaming
Spark Streaming 时代

Spark Streaming其实就是RDD的API的流式工具, 其本质还是RDD, 存储和执行过程依然类似RDD
Structured Streaming 时代
Structured Streaming其实就是Dataset的API的流式工具,API和Dataset保持高度一致
Spark Streaming 和 Structured Streaming
Structured Streaming相比于Spark Streaming的进步就类似于Dataset相比于RDD的进步另外还有一点,
Structured Streaming已经支持了连续流模型, 也就是类似于Flink那样的实时流, 而不是小批量, 但在使用的时候仍然有限制, 大部分情况还是应该采用小批量模式
在 2.2.0 以后 Structured Streaming 被标注为稳定版本, 意味着以后的 Spark 流式开发不应该在采用 Spark Streaming 了
Structured Streaming 入门案例
需求
编写一个流式计算的应用, 不断的接收外部系统的消息
对消息中的单词进行词频统计
统计全局的结果
步骤:
package cn.itcast.structured import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} object SocketWordCount { def main(args: Array[String]): Unit = { //1.创建SparkSession
val spark=SparkSession.builder().master("local[5]")
.appName("structured")
.getOrCreate() spark.sparkContext.setLogLevel("WARN")
import spark.implicits._ //2.数据集的生成,数据读取
val source: DataFrame =spark.readStream
.format("socket")
.option("host","192.168.31.101")
.option("port",9999)
.load() val sourceDS: Dataset[String] = source.as[String] //3.数据的处理
val words=sourceDS.flatMap(_.split(" "))
.map((_,1))
.groupByKey(_._1)
.count()
//4.结果集的生成和输出
words.writeStream
.outputMode(OutputMode.Complete())
.format("console")
.start()
.awaitTermination() } }
交互结果:
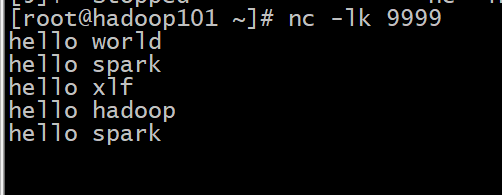
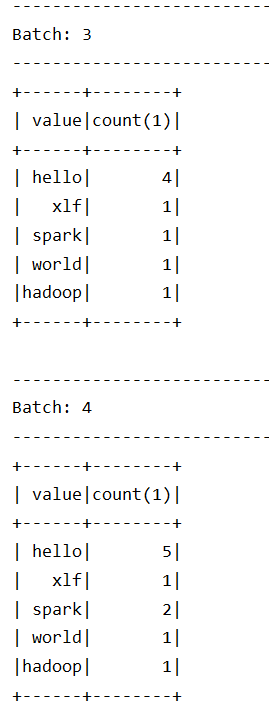
从结果集中可以观察到以下内容
Structured Streaming依然是小批量的流处理Structured Streaming的输出是类似DataFrame的, 也具有Schema, 所以也是针对结构化数据进行优化的从输出的时间特点上来看, 是一个批次先开始, 然后收集数据, 再进行展示, 这一点和
Spark Streaming不太一样
从 HDFS 中读取数据
使用 Structured Streaming 整合 HDFS, 从其中读取数据的能力
步骤
案例结构
产生小文件并推送到
HDFS流式计算统计
HDFS上的小文件运行和总结
实验步骤:
Step1:利用py产生文件源源不断向hdfs上传文件
Step2:编写 Structured Streaming 程序处理数据
py代码:
import os
for index in range(100):
content = """
{"name": "Michael"}
{"name": "Andy", "age": 30}
{"name": "Justin", "age": 19}
"""
file_name = "/export/dataset/text{0}.json".format(index)
with open(file_name, "w") as file:
file.write(content)
os.system("/export/servers/hadoop-2.7.5/bin/hdfs dfs -mkdir -p /dataset/dataset/")
os.system("/export/servers/hadoop-2.7.5/bin/hdfs dfs -put {0} /dataset/dataset/".format(file_name))
spark处理流式文件
package cn.itcast.structured import org.apache.spark.SparkContext
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.types.{StructField, StructType} object HDFSSource { def main(args: Array[String]): Unit = { System.setProperty("hadoop.home.dir","C:\\winutil") //1.创建SparkSession
val spark=SparkSession.builder()
.appName("hdfs_source")
.master("local[6]")
.getOrCreate() //2.数据读取
val schema=new StructType()
.add("name","string")
.add("age","integer")
val source=spark.readStream
.schema(schema)
.json("hdfs://hadoop101:8020/dataset/dataset") //3.输出结果
source.writeStream
.outputMode(OutputMode.Append())
.format("console")
.start()
.awaitTermination() } }
总结

Python生成文件到HDFS, 这一步在真实环境下, 可能是由Flume和Sqoop收集并上传至HDFSStructured Streaming从HDFS中读取数据并处理Structured Streaming讲结果表展示在控制台
Spark学习进度11-Spark Streaming&Structured Streaming的更多相关文章
- 学习Spark2.0中的Structured Streaming(一)
转载自:http://lxw1234.com/archives/2016/10/772.htm Spark2.0新增了Structured Streaming,它是基于SparkSQL构建的可扩展和容 ...
- Spark学习进度-Spark环境搭建&Spark shell
Spark环境搭建 下载包 所需Spark包:我选择的是2.2.0的对应Hadoop2.7版本的,下载地址:https://archive.apache.org/dist/spark/spark-2. ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- 【Spark学习】Apache Spark配置
Spark版本:1.1.1 本文系从官方文档翻译而来,转载请尊重译者的工作,注明以下链接: http://www.cnblogs.com/zhangningbo/p/4137969.html Spar ...
- 【Spark学习】Apache Spark调优
Spark版本:1.1.0 本文系以开源中国社区的译文为基础,结合官方文档翻译修订而来,转载请注明以下链接: http://www.cnblogs.com/zhangningbo/p/4117981. ...
- 【Spark学习】Apache Spark项目简介
引言:本文直接翻译自Spark官方网站首页 Lightning-fast cluster computing 从Spark官方网站给出的标题可以看出:Spark——像闪电一样快的集群计算 Apache ...
- 【Spark学习】Apache Spark安全机制
Spark版本:1.1.1 本文系从官方文档翻译而来,转载请尊重译者的工作,注明以下链接: http://www.cnblogs.com/zhangningbo/p/4135808.html 目录 W ...
- Spark学习笔记-使用Spark History Server
在运行Spark应用程序的时候,driver会提供一个webUI给出应用程序的运行信息,但是该webUI随着应用程序的完成而关闭端口,也就是 说,Spark应用程序运行完后,将无法查看应用程序的历史记 ...
- Spark 学习笔记之 Spark history Server 搭建
在hdfs上建立文件夹/directory hadoop fs -mkdir /directory 进入conf目录 spark-env.sh 增加以下配置 export SPARK_HISTORY ...
随机推荐
- CSP-S2020复赛游记
[本文经过删改] 前一个月 没做什么 NOIP 的题,感觉这些题对我这个做黄题封顶的人不是很友好. 前一天 考了场模拟赛,全场最低分 89,感觉信心满满. 退役那天 到了 XJ,发现没人可以面基,想着 ...
- 题解-CF429C Guess the Tree
题面 CF429C Guess the Tree 给一个长度为 \(n\) 的数组 \(a_i\),问是否有一棵树,每个节点要么是叶子要么至少有两个儿子,而且 \(i\) 号点的子树大小是 \(a_i ...
- 操作系统精髓与设计原理(九)——I/O管理和磁盘调度
文章目录 I/O设备 I/O功能组织 直接存储器访问 操作系统设计问题 设计目标 IO功能的逻辑结构 I/O缓冲 单缓冲 双缓冲 循环缓冲 缓冲的作用 磁盘调度 磁盘性能参数 磁盘调度策略 先进先出 ...
- 别再说你不懂什么是API了
API 全称 Application Programming Interface, 即应用程序编程接口. 看到这里,急性子的小白同学马上就憋不住了:这不管是英文还是中文我每个字都懂啊,只是凑一块就不知 ...
- mysql批量刷新用户密码
不知道用户密码,并且不改变用户密码的情况下,批量刷新MySQL数据库用户的密码 select concat('alter user \'',user,'\'@\'',host,'\' identifi ...
- jenkins 配置任务
新建筑任务 ""imuke 建一个自由风格的 要执行python .py程序,我们需要把.py所在的目录设置进去 如果保存的是在svn,需要把他的地址放进去 如图: 设置自动构建时 ...
- CentOS7部署GeoServer
CentOS7部署GeoServer 一.安装JDK81.下载jdk1.8 wget http://download.oracle.com/otn-pub/java/jdk/8u181-b13/96a ...
- html怎么在网页标题栏上添加图标
需要先把图片格式转换为.ico类型在这个网址在线转换很方便:https://www.easyicon.net/covert/在<head></head>加一行来显示图标(注意, ...
- vs2010新特性
下面列出了一些新的功能:1.代码编辑器新的代码编辑器使代码更易于阅读.可以通过按 CTRL 并滚动鼠标轮放大文本.此外,单击 Visual C# 或 Visual Basic 中的符号时该符号的所有实 ...
- Argo CD使用指南:如何构建一套完整的GitOps?
随着Kubernetes继续将自己确立为容器编排的行业标准,为你的应用和工具找到使用声明式模型的有效方法是成功的关键.在这篇文章中,我们将在AWS中建立一个K3s Kubernetes集群,然后使用A ...