Spark学习进度11-Spark Streaming&Structured Streaming
Spark Streaming
Spark Streaming 介绍
批量计算

流计算

Spark Streaming 入门
Netcat 的使用

项目实例
目标:使用 Spark Streaming 程序和 Socket server 进行交互, 从 Server 处获取实时传输过来的字符串, 拆开单词并统计单词数量, 最后打印出来每一个小批次的单词数量

步骤:
package cn.itcast.streaming import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext} object StreamingWordCount { def main(args: Array[String]): Unit = {
//1.初始化
val sparkConf=new SparkConf().setAppName("streaming").setMaster("local[2]")
val ssc=new StreamingContext(sparkConf,Seconds(5))
ssc.sparkContext.setLogLevel("WARN") val lines: ReceiverInputDStream[String] = ssc.socketTextStream(
hostname = "192.168.31.101",
port = 9999,
storageLevel = StorageLevel.MEMORY_AND_DISK_SER
)
//2.数据处理
//2.1把句子拆单词
val words: DStream[String] =lines.flatMap(_.split(" "))
val tuples: DStream[(String, Int)] =words.map((_,1))
val counts: DStream[(String, Int)] =tuples.reduceByKey(_+_) //3.展示
counts.print() ssc.start() ssc.awaitTermination() } }
开始进行交互:
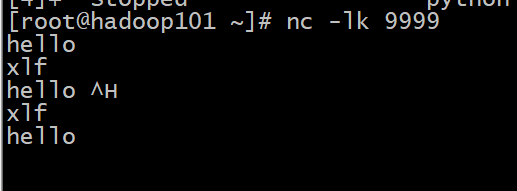
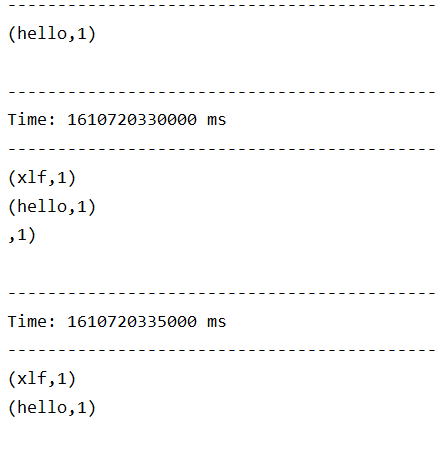
注意:
Spark Streaming 并不是真正的来一条数据处理一条
Spark Streaming 的处理机制叫做小批量, 英文叫做 mini-batch, 是收集了一定时间的数据后生成 RDD, 后针对 RDD 进行各种转换操作, 这个原理提现在如下两个地方
- 控制台中打印的结果是一个批次一个批次的, 统计单词数量也是按照一个批次一个批次的统计
- 多长时间生成一个
RDD去统计呢? 由new StreamingContext(sparkConf, Seconds(1))这段代码中的第二个参数指定批次生成的时间
Spark Streaming 中至少要有两个线程
在使用 spark-submit 启动程序的时候, 不能指定一个线程
- 主线程被阻塞了, 等待程序运行
- 需要开启后台线程获取数据
各种算子
这些算子类似
RDD, 也会生成新的DStream这些算子操作最终会落到每一个
DStream生成的RDD中
| 算子 | 释义 |
|---|---|
|
|
将一个数据一对多的转换为另外的形式, 规则通过传入函数指定 |
|
|
一对一的转换数据 |
|
|
这个算子需要特别注意, 这个聚合并不是针对于整个流, 而是针对于某个批次的数据 |
Structured Streaming
Spark 编程模型的进化过程
| 编程模型 | 解释 |
|---|---|
|
|
|
|
|
|
|
|
|
Spark Streaming 和 Structured Streaming
Spark Streaming 时代

Spark Streaming其实就是RDD的API的流式工具, 其本质还是RDD, 存储和执行过程依然类似RDD
Structured Streaming 时代
Structured Streaming其实就是Dataset的API的流式工具,API和Dataset保持高度一致
Spark Streaming 和 Structured Streaming
Structured Streaming相比于Spark Streaming的进步就类似于Dataset相比于RDD的进步另外还有一点,
Structured Streaming已经支持了连续流模型, 也就是类似于Flink那样的实时流, 而不是小批量, 但在使用的时候仍然有限制, 大部分情况还是应该采用小批量模式
在 2.2.0 以后 Structured Streaming 被标注为稳定版本, 意味着以后的 Spark 流式开发不应该在采用 Spark Streaming 了
Structured Streaming 入门案例
需求
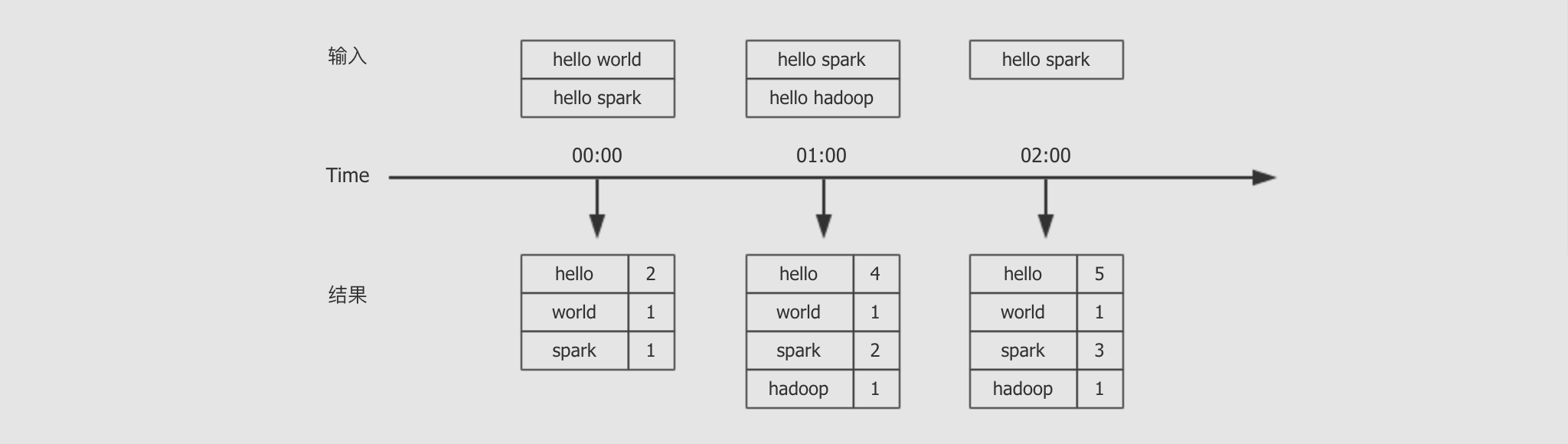
编写一个流式计算的应用, 不断的接收外部系统的消息
对消息中的单词进行词频统计
统计全局的结果
步骤:
package cn.itcast.structured import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} object SocketWordCount { def main(args: Array[String]): Unit = { //1.创建SparkSession
val spark=SparkSession.builder().master("local[5]")
.appName("structured")
.getOrCreate() spark.sparkContext.setLogLevel("WARN")
import spark.implicits._ //2.数据集的生成,数据读取
val source: DataFrame =spark.readStream
.format("socket")
.option("host","192.168.31.101")
.option("port",9999)
.load() val sourceDS: Dataset[String] = source.as[String] //3.数据的处理
val words=sourceDS.flatMap(_.split(" "))
.map((_,1))
.groupByKey(_._1)
.count()
//4.结果集的生成和输出
words.writeStream
.outputMode(OutputMode.Complete())
.format("console")
.start()
.awaitTermination() } }
交互结果:
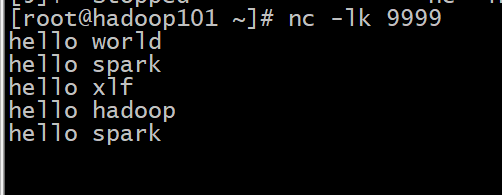
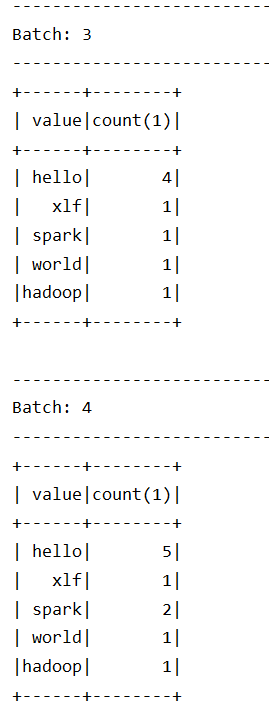
从结果集中可以观察到以下内容
Structured Streaming依然是小批量的流处理Structured Streaming的输出是类似DataFrame的, 也具有Schema, 所以也是针对结构化数据进行优化的从输出的时间特点上来看, 是一个批次先开始, 然后收集数据, 再进行展示, 这一点和
Spark Streaming不太一样
从 HDFS 中读取数据
使用 Structured Streaming 整合 HDFS, 从其中读取数据的能力
步骤
案例结构
产生小文件并推送到
HDFS流式计算统计
HDFS上的小文件运行和总结
实验步骤:
Step1:利用py产生文件源源不断向hdfs上传文件
Step2:编写 Structured Streaming 程序处理数据
py代码:
import os
for index in range(100):
content = """
{"name": "Michael"}
{"name": "Andy", "age": 30}
{"name": "Justin", "age": 19}
"""
file_name = "/export/dataset/text{0}.json".format(index)
with open(file_name, "w") as file:
file.write(content)
os.system("/export/servers/hadoop-2.7.5/bin/hdfs dfs -mkdir -p /dataset/dataset/")
os.system("/export/servers/hadoop-2.7.5/bin/hdfs dfs -put {0} /dataset/dataset/".format(file_name))
spark处理流式文件
package cn.itcast.structured import org.apache.spark.SparkContext
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.types.{StructField, StructType} object HDFSSource { def main(args: Array[String]): Unit = { System.setProperty("hadoop.home.dir","C:\\winutil") //1.创建SparkSession
val spark=SparkSession.builder()
.appName("hdfs_source")
.master("local[6]")
.getOrCreate() //2.数据读取
val schema=new StructType()
.add("name","string")
.add("age","integer")
val source=spark.readStream
.schema(schema)
.json("hdfs://hadoop101:8020/dataset/dataset") //3.输出结果
source.writeStream
.outputMode(OutputMode.Append())
.format("console")
.start()
.awaitTermination() } }
总结

Python生成文件到HDFS, 这一步在真实环境下, 可能是由Flume和Sqoop收集并上传至HDFSStructured Streaming从HDFS中读取数据并处理Structured Streaming讲结果表展示在控制台
Spark学习进度11-Spark Streaming&Structured Streaming的更多相关文章
- 学习Spark2.0中的Structured Streaming(一)
转载自:http://lxw1234.com/archives/2016/10/772.htm Spark2.0新增了Structured Streaming,它是基于SparkSQL构建的可扩展和容 ...
- Spark学习进度-Spark环境搭建&Spark shell
Spark环境搭建 下载包 所需Spark包:我选择的是2.2.0的对应Hadoop2.7版本的,下载地址:https://archive.apache.org/dist/spark/spark-2. ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- 【Spark学习】Apache Spark配置
Spark版本:1.1.1 本文系从官方文档翻译而来,转载请尊重译者的工作,注明以下链接: http://www.cnblogs.com/zhangningbo/p/4137969.html Spar ...
- 【Spark学习】Apache Spark调优
Spark版本:1.1.0 本文系以开源中国社区的译文为基础,结合官方文档翻译修订而来,转载请注明以下链接: http://www.cnblogs.com/zhangningbo/p/4117981. ...
- 【Spark学习】Apache Spark项目简介
引言:本文直接翻译自Spark官方网站首页 Lightning-fast cluster computing 从Spark官方网站给出的标题可以看出:Spark——像闪电一样快的集群计算 Apache ...
- 【Spark学习】Apache Spark安全机制
Spark版本:1.1.1 本文系从官方文档翻译而来,转载请尊重译者的工作,注明以下链接: http://www.cnblogs.com/zhangningbo/p/4135808.html 目录 W ...
- Spark学习笔记-使用Spark History Server
在运行Spark应用程序的时候,driver会提供一个webUI给出应用程序的运行信息,但是该webUI随着应用程序的完成而关闭端口,也就是 说,Spark应用程序运行完后,将无法查看应用程序的历史记 ...
- Spark 学习笔记之 Spark history Server 搭建
在hdfs上建立文件夹/directory hadoop fs -mkdir /directory 进入conf目录 spark-env.sh 增加以下配置 export SPARK_HISTORY ...
随机推荐
- C++异常之三 异常处理接口声明
异常处理接口声明 1 一般为了方便程序员阅读代码,提高程序的可读性,会将函数中的异常类型声明至函数头后方,不用一行一行的找抛出内容: 2 这里要注意一点,这属于C++的标准语法,但在VS中这个操作不被 ...
- Jmeter(7)参数化csv data set config
接口测试同一变量或同一组变量不同值时,可通过csv data set config配置数据 1.创建文本文件,写入参数值,一个或一组值为一行,保存为.csv文件 2.创建测试计划,配置元件添加csv ...
- Fastjson 1.2.47 远程命令执行漏洞复现
前言 这个漏洞出来有一段时间了,有人一直复现不成功来问我,就自己复现了下,顺便简单记录下这个漏洞原理,以便后面回忆. 复现过程 网上已经有很多文章了,这里就不在写了.主要记录一下复现过程中遇到的问题 ...
- vue 事件基本用法
事件基本用法 事件的函数都定义在VUE实例中的methods中,当然也可以直接写在元素内,但是这并不利于后期的维护,需要注意的是:在methods定义的函数内想要引用插值内容,需要使用this,不然就 ...
- windows 上的MySQL默认字符集设置踩过的坑
前言: 前几天刚买了新电脑,装上MySQL有几天了,今天没事试了一下,发现默认字符集没有修改,还是默认的latin1,折腾了大半天,终于搞好了. 这是我成功设置后的结果图: 命令式直接在MySQL界面 ...
- css精髓:这些布局你都学废了吗?
前言 最近忙里偷闲,给自己加油充电的时候,发现自己脑海中布局这块非常的凌乱混杂,于是花了一些时间将一些常用的布局及其实现方法整理梳理了出来,在这里,分享给大家. 单列布局 单列布局是最常用的一种布局, ...
- 多任务-python实现-迭代器相关(2.1.12)
@ 目录 1.需求 2.斐波那契数列演示 3.并不是只有for循环能接收可迭代数据类型,list,tuple也可以 1.需求 类比 早上起来吃包子 1.买1年的包子,放在冰箱,每天拿一个 2.每天下楼 ...
- matplotlib的学习4-设置坐标轴
import matplotlib.pyplot as plt import numpy as np x = np.linspace(-3, 3, 50) y1 = 2*x + 1 y2 = x**2 ...
- Spring Boot 2.4版本前后的分组配置变化及对多环境配置结构的影响
前几天在<Spring Boot 2.4 对多环境配置的支持更改>一文中,给大家讲解了Spring Boot 2.4版本对多环境配置的配置变化.除此之外,还有一些其他配置变化,所以今天我们 ...
- 手写算法-python代码实现KNN
原理解析 KNN-全称K-Nearest Neighbor,最近邻算法,可以做分类任务,也可以做回归任务,KNN是一种简单的机器学习方法,它没有传统意义上训练和学习过程,实现流程如下: 1.在训练数据 ...