scrapy-splash抓取动态数据例子八
一、介绍
本例子用scrapy-splash抓取界面网站给定关键字抓取咨询信息。
给定关键字:个性化;融合;电视
抓取信息内如下:
1、资讯标题
2、资讯链接
3、资讯时间
4、资讯来源
二、网站信息
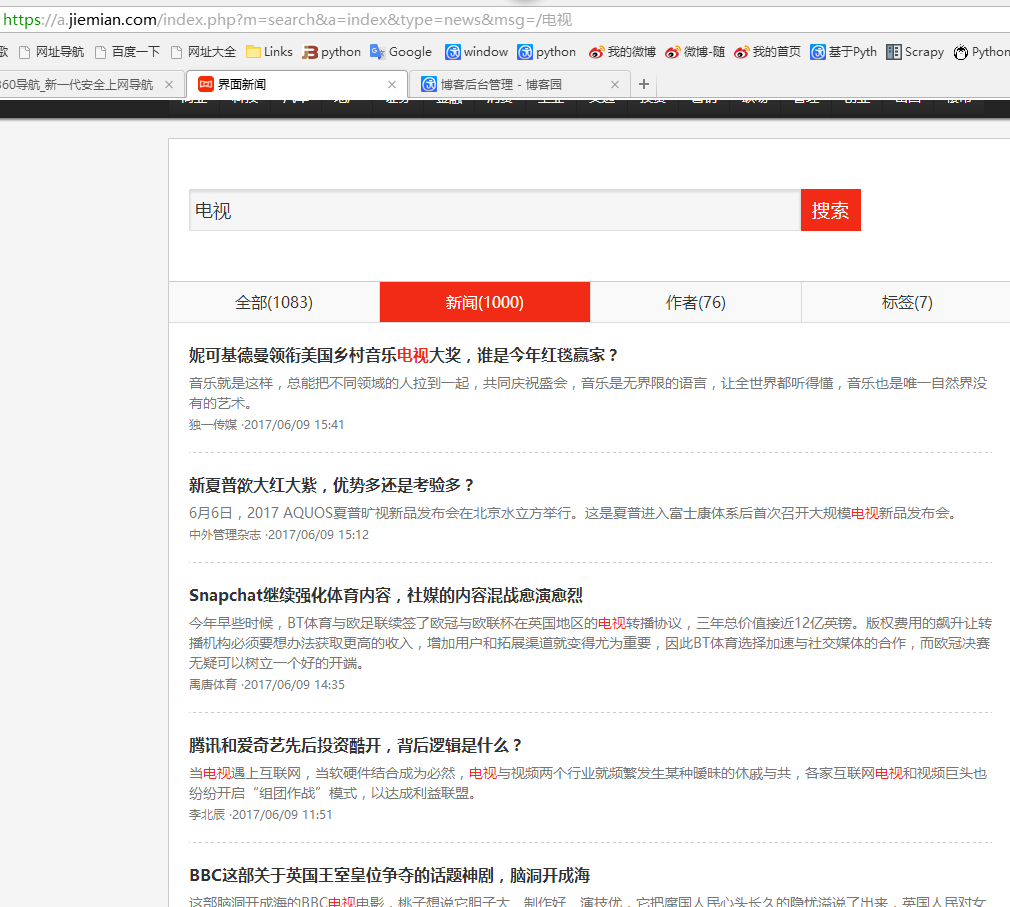
三、数据抓取
针对上面的网站信息,来进行抓取
1、首先抓取信息列表
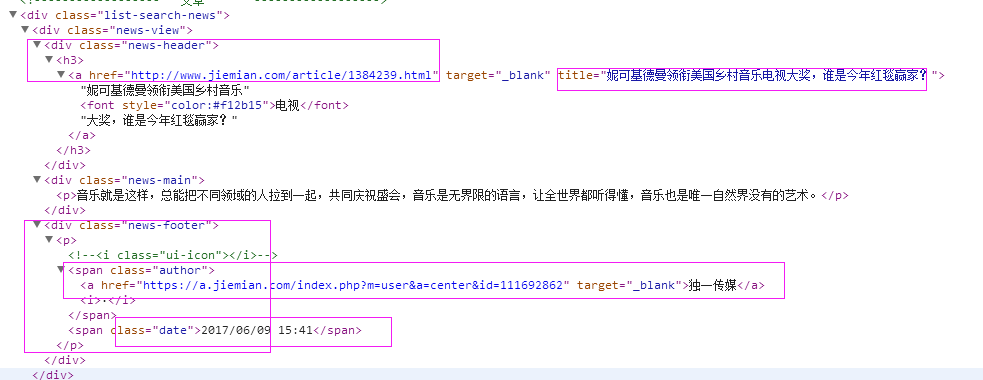
抓取代码:sels = site.xpath('//div[contains(@class,"news-view")]')
2、抓取标题
抓取代码:title = sel.xpath('.//div[@class="news-header"]/h3/a/@title')[0].extract()
3、抓取链接
抓取代码:it['url'] = sel.xpath('.//div[@class="news-header"]/h3/a/@href')[0].extract()
4、抓取日期
抓取代码:dates = sel.xpath('.//div[@class="news-footer"]/p/span[2]/text()')
5、抓取来源
抓取代码:sources =sel.xpath('.//div[@class="news-footer"]/p/span[1]/a/text()')
四、完整代码
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from scrapy.spiders import Spider
from scrapy_splash import SplashRequest
from scrapy_splash import SplashMiddleware
from scrapy.http import Request, HtmlResponse
from scrapy.selector import Selector
from scrapy_splash import SplashRequest
from splash_test.items import SplashTestItem
import IniFile
import sys
import os
import re
import time reload(sys)
sys.setdefaultencoding('utf-8') # sys.stdout = open('output.txt', 'w') class jiemianSpider(Spider):
name = 'jiemian' configfile = os.path.join(os.getcwd(), 'splash_test\spiders\setting.conf') cf = IniFile.ConfigFile(configfile)
information_keywords = cf.GetValue("section", "information_keywords")
information_wordlist = information_keywords.split(';')
websearchurl = cf.GetValue("jiemian", "websearchurl")
start_urls = []
for word in information_wordlist:
print websearchurl + word
start_urls.append(websearchurl + word) # request需要封装成SplashRequest
def start_requests(self):
for url in self.start_urls:
index = url.rfind('=')
yield SplashRequest(url
, self.parse
, args={'wait': ''},
meta={'keyword': url[index + 1:]}
) def Comapre_to_days(self,leftdate, rightdate):
'''
比较连个字符串日期,左边日期大于右边日期多少天
:param leftdate: 格式:2017-04-15
:param rightdate: 格式:2017-04-15
:return: 天数
'''
l_time = time.mktime(time.strptime(leftdate, '%Y-%m-%d'))
r_time = time.mktime(time.strptime(rightdate, '%Y-%m-%d'))
result = int(l_time - r_time) / 86400
return result def date_isValid(self, strDateText): currentDate = time.strftime('%Y-%m-%d')
datePattern = re.compile(r'\d{4}-\d{1,2}-\d{1,2}')
dt = strDateText.replace('/', '-')
strDate = re.findall(datePattern, dt)
if len(strDate) == 1:
if self.Comapre_to_days(currentDate, strDate[0]) == 0:
return True, currentDate
return False, '' def parse(self, response):
site = Selector(response) sels = site.xpath('//div[contains(@class,"news-view")]')
keyword = response.meta['keyword']
item_list = []
for sel in sels:
dates = sel.xpath('.//div[@class="news-footer"]/p/span[2]/text()')
flag,date =self.date_isValid(dates[0].extract())
title = sel.xpath('.//div[@class="news-header"]/h3/a/@title')[0].extract()
if flag and title.find(keyword)>-1:
it = SplashTestItem()
it['title'] = title
it['url'] = sel.xpath('.//div[@class="news-header"]/h3/a/@href')[0].extract()
it['date'] = date
it['keyword'] = keyword
sources =sel.xpath('.//div[@class="news-footer"]/p/span[1]/a/text()')
if len(sources)>0:
it['source'] = sources[0].extract()
item_list.append(it)
return item_list
scrapy-splash抓取动态数据例子八的更多相关文章
- scrapy-splash抓取动态数据例子一
目前,为了加速页面的加载速度,页面的很多部分都是用JS生成的,而对于用scrapy爬虫来说就是一个很大的问题,因为scrapy没有JS engine,所以爬取的都是静态页面,对于JS生成的动态页面都无 ...
- scrapy-splash抓取动态数据例子七
一.介绍 本例子用scrapy-splash抓取36氪网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子六
一.介绍 本例子用scrapy-splash抓取中广互联网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子五
一.介绍 本例子用scrapy-splash抓取智能电视网网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站 ...
- scrapy-splash抓取动态数据例子四
一.介绍 本例子用scrapy-splash抓取微众圈网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- scrapy-splash抓取动态数据例子三
一.介绍 本例子用scrapy-splash抓取今日头条网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子二
一.介绍 本例子用scrapy-splash抓取一点资讯网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子十六
一.介绍 本例子用scrapy-splash爬取梅花网(http://www.meihua.info/a/list/today)的资讯信息,输入给定关键字抓取微信资讯信息. 给定关键字:数字:融合:电 ...
- scrapy-splash抓取动态数据例子十五
一.介绍 本例子用scrapy-splash爬取电视之家(http://www.tvhome.com/news/)网站的资讯信息,输入给定关键字抓取微信资讯信息. 给定关键字:数字:融合:电视 抓取信 ...
随机推荐
- EF框架的优点是什么?
在.Net Framework SP1微软包含一个实体框架(Entity Framework),此框架可以理解成微软的一个ORM产品.用于支持开发人员通过对概念性应用程序模型编程(而不是直接对关系存储 ...
- python判断一个对象是可迭代?
1.介绍一下如何判断一个对象是可迭代的? 通过collections模块的Iterable类型判断: >>> from collections import Iterable > ...
- thinkphp下实现ajax无刷新分页
1.前言 作为一名php程序员,我们开发网站主要就是为了客户从客户端进行体验,在这里,thinkphp框架自带的分页类是每次翻页都要刷新一下整个页面,这种翻页的用户体验显然是不太理想的,我们希望每次翻 ...
- Linux操作命令(三)
本次实验将介绍 Linux 命令中 more.less.head.tail 命令的用法. more less head tail 1.more ·more功能类似cat,cat命令是将整个文件的内容从 ...
- Linux操作命令(二)
本次实验将介绍 Linux 命令中 mkdir.rm.mv.cp.cat.nl 命令的用法. 1.mkdir mkdir命令用来创建指定名称的目录,要求创建目录的用户在当前目录中具有写权限,并且指定的 ...
- POJ 3660 Cow Contest (dfs)
Cow Contest Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 11129 Accepted: 6183 Desc ...
- CAS无锁操作
https://coolshell.cn/articles/8239.html 主要讲的是<Implementing Lock-Free Queues>的论点,具体直接看论文最好.这里总结 ...
- Flask实战第56天:板块管理
cms布局 编辑 cms_boards.html {% block main_content %} <div class="top-box"> <button c ...
- JavaScript中的Array数组详解
ECMAScript中的数组与其他多数语言中的数组有着相当大的区别,虽然数组都是数据的有序列表,但是与其他语言不同的是,ECMAScript数组的每一项可以保存任何类型的数据.也就是说,可以用数组的第 ...
- HDU 5967 小R与手机(动态树)
[题目链接] http://acm.hdu.edu.cn/showproblem.php?pid=5967 [题目大意] 给出一张图,每个点仅连一条有向边,或者不连, 要求查询在可更改有向边的情况每个 ...