Python爬虫教程-22-lxml-etree和xpath配合使用
Python爬虫教程-22-lxml-etree和xpath配合使用
- lxml:python 的HTML/XML的解析器
- 官网文档:https://lxml.de/
- 使用前,需要安装安 lxml 包
- 功能:
- 1.解析HTML:使用 etree.HTML(text) 将字符串格式的 html 片段解析成 html 文档
- 2.读取xml文件
- 3.etree和XPath 配合使用
lxml 的安装
- 【PyCharm】>【file】>【settings】>【Project Interpreter】>【+】 >【lxml】>【install】
- 具体操作截图:
lxml-etree 的使用
- 案例v25文件:https://xpwi.github.io/py/py爬虫/py25etree.py
- 用 lxml 来解析HTML代码
# 先安装lxml
# 用 lxml 来解析HTML代码
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="0.html">item 0 </a></li>
<li class="item-1"><a href="1.html">item 1 </a></li>
<li class="item-2"><a href="2.html">item 2 </a></li>
<li class="item-3"><a href="3.html">item 3 </a></li>
<li class="item-4"><a href="4.html">item 4 </a></li>
<li class="item-5"><a href="5.html">item 5 </a></li>
</ul>
</div>
'''
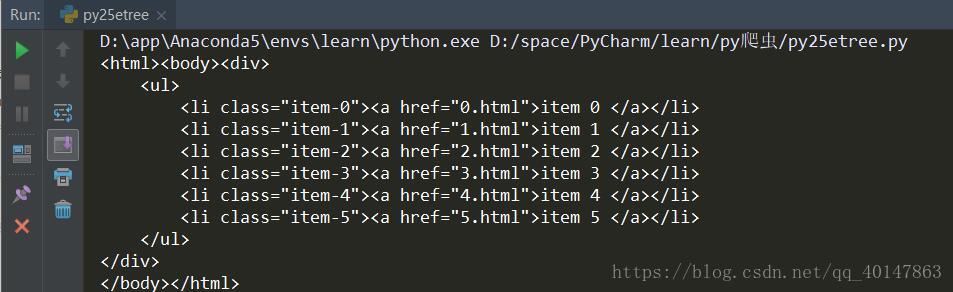
# 利用 etree.HTML 把字符串解析成 HTML 文件
html = etree.HTML(text)
s = etree.tostring(html).decode()
print(s)
运行结果
lxml-etree 的使用
- 案例v26etree2文件:https://xpwi.github.io/py/py爬虫/py26etree2.py
- 读取xml文件:
# lxml-etree读取文件
from lxml import etree
xml = etree.parse("./py24.xml")
sxml = etree.tostring(xml, pretty_print=True)
print(sxml)
运行结果

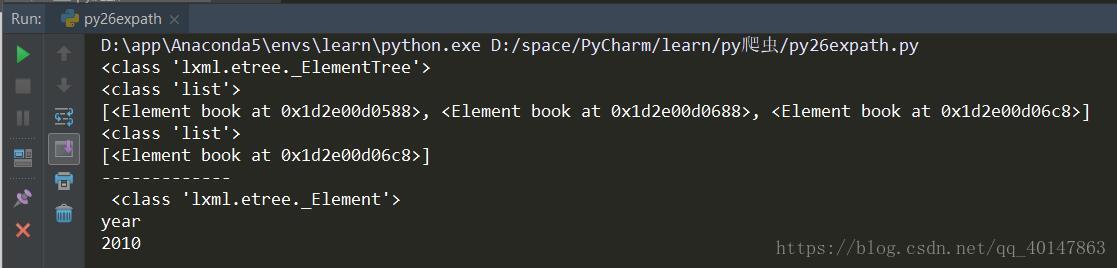
etree和XPath 配合使用
- 案例v26expath.文件:https://xpwi.github.io/py/py爬虫/py26expath.py
- etree和XPath 配合使用:
# lxml-etree读取文件
from lxml import etree
xml = etree.parse("./py24.xml")
print(type(xml))
# 查找所有 book 节点
rst = xml.xpath('//book')
print(type(rst))
print(rst)
# 查找带有 category 属性值为 sport 的元素
rst2 = xml.xpath('//book[@category="sport"]')
print(type(rst2))
print(rst2)
# 查找带有category属性值为sport的元素的book元素下到的year元素
rst3 = xml.xpath('//book[@category="sport"]/year')
rst3 = rst3[0]
print('-------------\n',type(rst3))
print(rst3.tag)
print(rst3.text)
运行结果
etree和XPath 配合使用结果
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-22-lxml-etree和xpath配合使用的更多相关文章
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-33-scrapy shell 的使用
本篇详细介绍 scrapy shell 的使用,也介绍了使用 xpath 进行精确查找 Python爬虫教程-33-scrapy shell 的使用 scrapy shell 的使用 条件:我们需要先 ...
- Python爬虫教程-25-数据提取-BeautifulSoup4(三)
Python爬虫教程-25-数据提取-BeautifulSoup4(三) 本篇介绍 BeautifulSoup 中的 css 选择器 css 选择器 使用 soup.select 返回一个列表 通过标 ...
- Python爬虫教程-24-数据提取-BeautifulSoup4(二)
Python爬虫教程-24-数据提取-BeautifulSoup4(二) 本篇介绍 bs 如何遍历一个文档对象 遍历文档对象 contents:tag 的子节点以列表的方式输出 children:子节 ...
- Python爬虫教程-23-数据提取-BeautifulSoup4(一)
Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据,查看文档 https://www.crummy.com/software/BeautifulSoup/bs4/doc. ...
- Python爬虫教程-21-xpath 简介
本篇简单介绍 xpath 在python爬虫方面的使用,想要具体学习 xpath 可以到 w3school 查看 xpath 文档 xpath文档:http://www.w3school.com.cn ...
- Python爬虫教程-18-页面解析和数据提取
本篇针对的数据是已经存在在页面上的数据,不包括动态生成的数据,今天是对HTML中提取对我们有用的数据,去除无用的数据 Python爬虫教程-18-页面解析和数据提取 结构化数据:先有的结构,再谈数据 ...
- Python爬虫教程-21-xpath
本篇简单介绍 xpath 在python爬虫方面的使用,想要具体学习 xpath 可以到 w3school 查看 xpath 文档 Python爬虫教程-21-xpath 什么是 XPath? XPa ...
随机推荐
- 高阶篇:4.3)FTA故障树分析法-DFMEA的另外一张脸
本章目的:明确什么是FTA,及与DFMEA的关系. 1.FTA定义 故障树分析(FTA) 其一:故障树分析(Fault Tree Analysis,简称FTA)又称事故树分析,是安全系统工程中最重要的 ...
- Linux下安装渗透测试框架Metasploit
我们先来说一种方法,直接从github来下载: git clone --depth=1 git://github.com/rapid7/metasploit-framework metasploit ...
- 【linux】如何查看文件的创建、修改时间
本篇博文旨在介绍Linux下查看文件时间的方法:并介绍如何使用touch指令来进行文件时间的创建以及修改 如何查看文件的时间信息利用stat指令查看文件信息 三种时间的介绍ATime ——文件的最近访 ...
- Locust源码目录结构及模块作用
Locust源码目录结构及模块作用如下: 参考文章:https://blog.csdn.net/biheyu828/article/details/84031942
- 第十次 Scrum Meeting
第十次 Scrum Meeting 写在前面 会议时间 会议时长 会议地点 2019/4/16 14:30 30min 新主楼F座2F 附Github仓库:WEDO 例会照片 工作情况总结 人员 上阶 ...
- vue中实现国际化--语言切换(转载)
https://segmentfault.com/a/1190000011800593
- crypto-js计算文件的sha256值
1. 要在浏览器中计算出文件的sha256或md5值,基本思路就是使用HTML5的FileReader接口把文件读取到内存(readAsArrayBuffer),然后获取文件的二进制内容,然后获取文件 ...
- 谈 Python 程序和 C 程序的整合 (转载)
http://www.ibm.com/developerworks/cn/linux/l-cn-pythonandc/ 概览 Python 是一种用于快速开发软件的编程语言,它的语法比较简单,易于掌握 ...
- 【Docker】Dockerfile使用apt-get来安装jdk
前面谈过使用wget来从oracle下载jdk安装文件是使用了cookie欺骗的方法来越过身份验证来使用Dockerfile在ubuntu内安装oracle版本的jdk的. 然而正道还是用apt-ge ...
- java.security.MessageDigest的使用之生成安全令牌!
时候,我们需要产生一个数据,这个数据保存了用户的信息,但加密后仍然有可能被人使用,即便他人不确切的了解详细信息... 好比,我们在上网的时候,很多网页都会有一个信息,是否保存登录信息,以便下次可以直接 ...