Pig安装与应用
1. 参考说明
参考文档:
http://pig.apache.org/docs/r0.17.0/start.html#build
2. 安装环境说明
2.1. 环境说明
CentOS7.4+ Hadoop2.7.5的伪分布式环境
|
主机名 |
NameNode |
SecondaryNameNode |
DataNodes |
|
centoshadoop.smartmap.com |
192.168.1.80 |
192.168.1.80 |
192.168.1.80 |
Hadoop的安装目录为:/opt/hadoop/hadoop-2.7.5
3. 安装
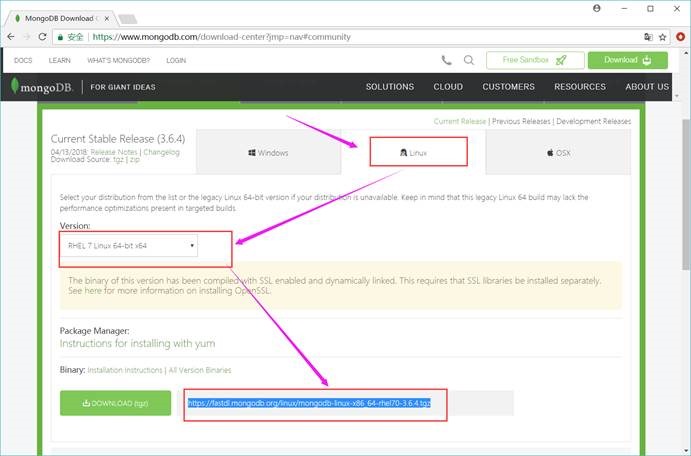
3.1. Pig下载
http://pig.apache.org/releases.html#Download
[root@server1 ~]# mkdir /opt/mongodb
[root@server1 ~]# chown -R mongodb:mongodb
/opt/mongodb/
3.2. Pig解压
将下载的pig-0.17.0.tar.gz解压到/opt/hadoop/pig-0.17.0目录下
4. 配置
4.1. 修改profile文件
vi
/etc/profile
export PIG_HOME=/opt/hadoop/pig-0.17.0
export PATH=$PATH:$PIG_HOME/bin
4.2. 将JDK升级为1.8版本
将JDK切换成1.8的版本,并修改所有与JAVA_HOME相关的变量
4.3. 修改pig的配置文件
vi
/opt/hadoop/pig-0.17.0/conf/pig.properties
exectype=mapreduce
4.4. 修改mapred-site.xml以启用jobhistory
vi
/opt/hadoop/hadoop-2.7.5/etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.1.80:10020</value>
</property>
5. 启动Hadoop
5.1. 启动YARN与HDFS
cd
/opt/hadoop/hadoop-2.7.5/sbin
start-all.sh
5.2. 启动historyserver
cd
/opt/hadoop/hadoop-2.7.5/sbin
mr-jobhistory-daemon.sh start historyserver
6. 应用Pig工具
6.1. 导入文件到HDFS中
hadoop
fs -mkdir -p /input/ncdc/micro-tab
hadoop
fs -copyFromLocal sample.txt /input/ncdc/micro-tab/sample.txt
6.2. 启动运行Pig的交互式Shell环境
cd
/opt/hadoop/pig-0.17.0/bin
pig
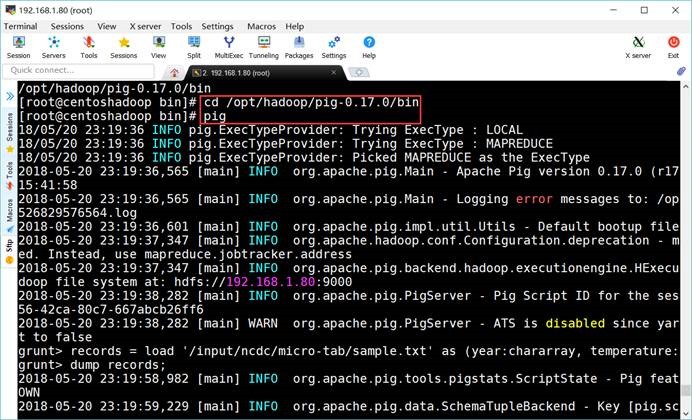
6.3. 运行任务
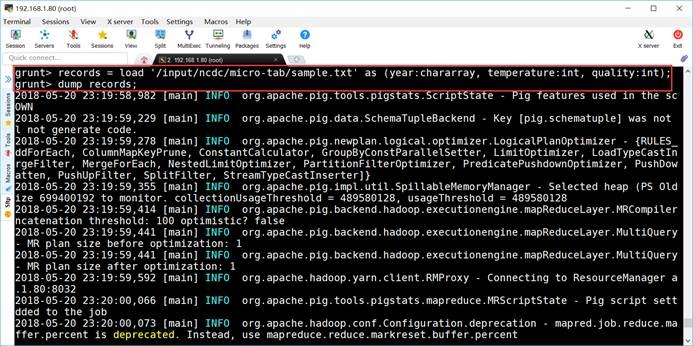
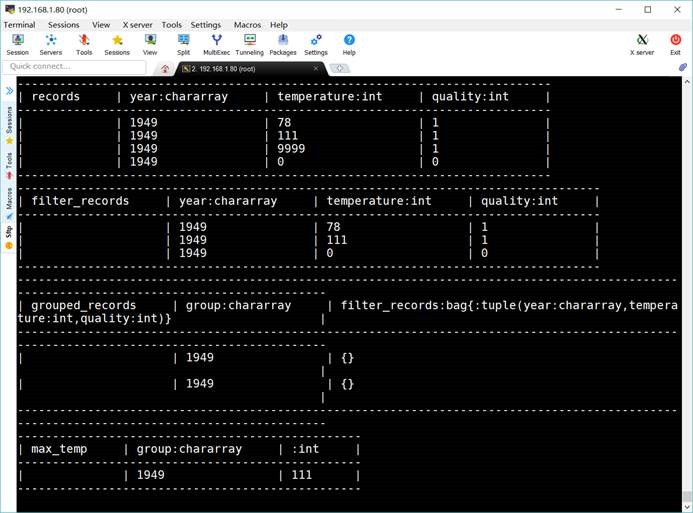
grunt> records = load
'/input/ncdc/micro-tab/sample.txt' as (year:chararray, temperature:int,
quality:int);
grunt> dump records;

6.4. 退出
grunt> \q
6.5. 显示模式
cd
/opt/hadoop/pig-0.17.0/bin
pig
grunt> records = LOAD
'/input/ncdc/micro-tab/sample.txt' as (year:chararray, temperature:int,
quality:int);
grunt> DUMP
records;
grunt> DESCRIBE records
records:
{year: chararray,temperature: int,quality: int}
grunt>
6.6. 过滤数据
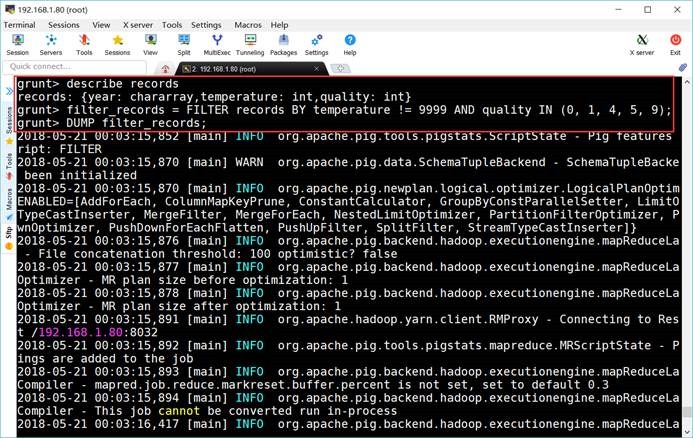
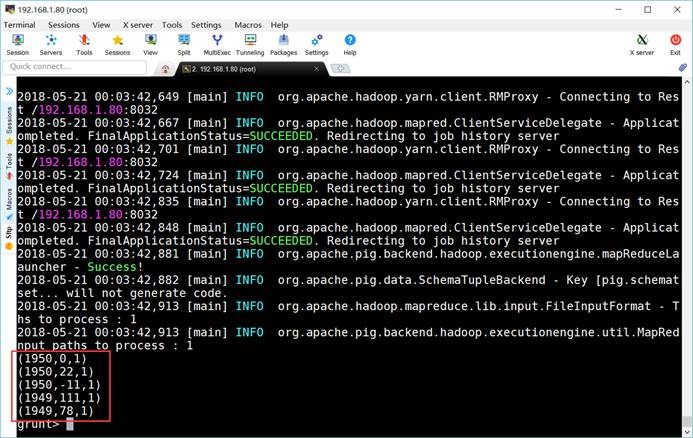
grunt> filter_records =
FILTER records BY temperature != 9999 AND quality IN (0, 1, 4, 5,
9);
grunt> DUMP
filter_records;
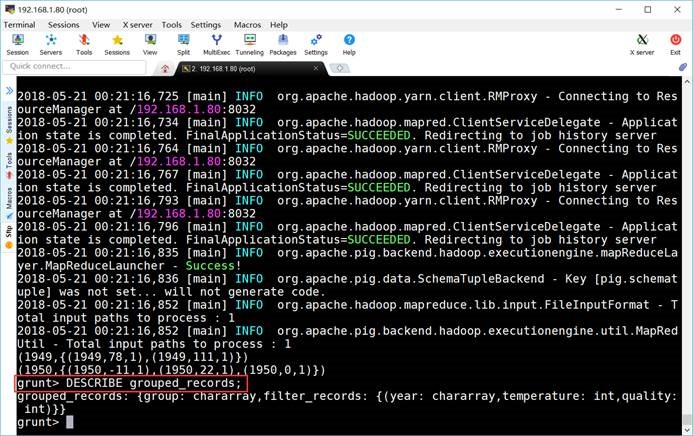
6.7. 分组记录
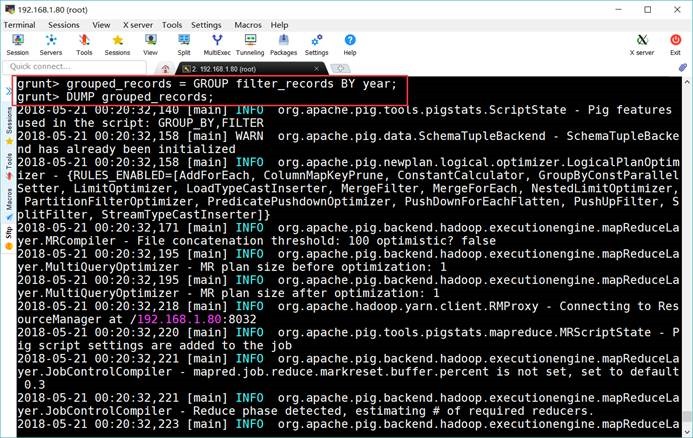
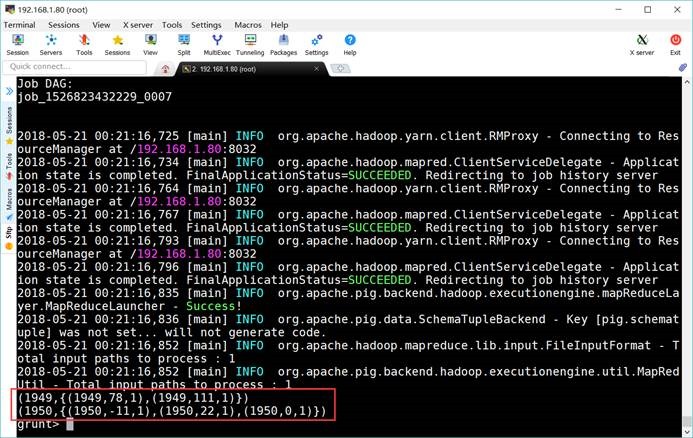
grunt> grouped_records =
GROUP filter_records BY year;
grunt> DUMP
grouped_records;
grunt> DESCRIBE
grouped_records;
grouped_records: {group: chararray,filter_records:
{(year: chararray,temperature: int,quality: int)}}
grunt>
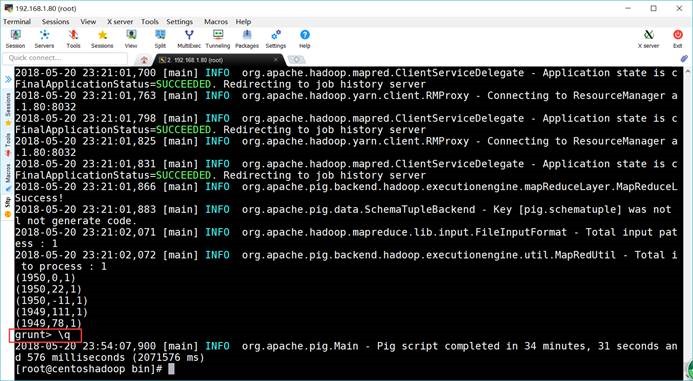
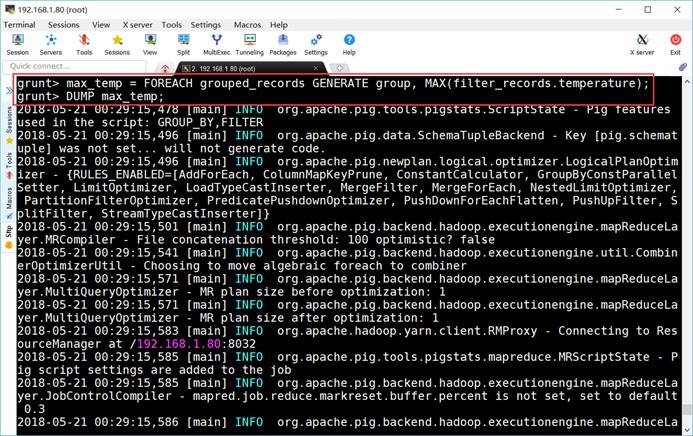
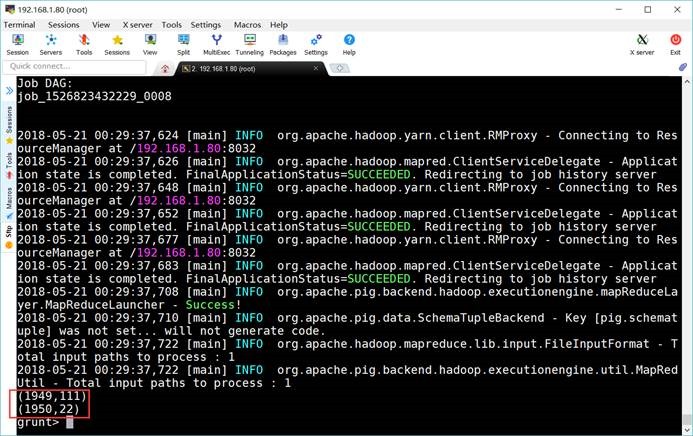
6.8. 计算最大值
grunt> max_temp = FOREACH
grouped_records GENERATE group, MAX(filter_records.temperature);
grunt> DUMP
max_temp;
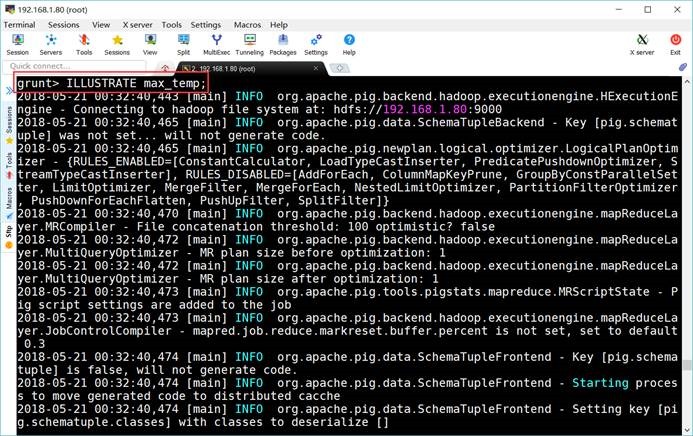
6.9. 查看执行过程
grunt> ILLUSTRATE max_temp;
Pig安装与应用的更多相关文章
- 大数据之pig安装
大数据之pig安装 1.下载 pig download 2. 解压安装 mapreduce模式安装: 1:设置HADOOP_HOME,如果pig所在节点不是集群中的节点,那就需要把集群中使用的hado ...
- Pig安装及简单使用(pig版本0.13.0,Hadoop版本2.5.0)
原文地址:http://www.linuxidc.com/Linux/2014-03/99055.htm 我们用MapReduce进行数据分析.当业务比较复杂的时候,使用MapReduce将会是一个很 ...
- Hadoop:pig 安装及入门示例
pig是hadoop的一个子项目,用于简化MapReduce的开发工作,可以用更人性化的脚本方式分析数据. 一.安装 a) 下载 从官网http://pig.apache.org下载最新版本(目前是0 ...
- Hadoop之Pig安装
Pig可以看做是Hadoop的客户端软件,使用Pig Latin语言可以实现排序.过滤.求和.分组等操作. Pig的安装步骤: 一.去Pig的官方网站下载.http://pig.apache.org/ ...
- Pig安装
环境: hadoop-2.4.1.jdk1.6.0_45.pig-0.12.1 1.下载pig并解压 tar -xzvf pig-0.12.1.tar.gz 2.设置环境变量 export PIG ...
- pig安装配置
pig的安装配置很简单,只需要配置一下环境变量和指向hadoop conf的环境变量就行了 1.上传 2.解压 3.配置环境变量 Pig工作模式 本地模式:只需要配置PATH环境变量${PIG_HOM ...
- 阿里云ECS服务器部署HADOOP集群(五):Pig 安装
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建. 1 环境介绍 一台阿里云ECS服务器:master 操作系统:CentOS 7.3 Hadoop ...
- pig安装配置及实例
一.前提 1. hadoop集群环境配置好(本人hadoop版本:hadoop-2.7.3) 2. windows基础环境准备: jdk环境配置.esclipse环境配置 二.搭建pig环境 1.下载 ...
- hadoop,hbase,pig安装
注意端口,办公网只能访问8000-9000的端口 pig的一些lib文件版本 /home/map/hadoop/lib下一些98.5的lib没删除
随机推荐
- 汉诺塔问题(C++版)
题目描述 Description 约19世纪末,在欧州的商店中出售一种智力玩具,在一块铜板上有三根杆,最左边的杆上自上而下.由小到大顺序串着由64个圆盘构成的塔.目的是将最左边杆上的盘全部移到中间的杆 ...
- 【bzoj4240】 有趣的家庭菜园 树状数组
这一题最终要构造的序列显然是一个单峰序列 首先有一个结论:一个序列通过交换相邻的元素,进行排序,最少的交换次数为该序列的逆序对个数 (该结论很久之前打表意外发现的,没想到用上了.....) 考虑如何构 ...
- IQKeyboardManager 问题锦集
Keep UINavigationBar at the top (Don't scroll with keyboard) (#21, #24) If you don't want to hide th ...
- MySQL命令行导入sql文件时出现乱码解决方案
Note: sql> source F:weibo.sql(执行相关sql文件) sql> select * from sina into outfile "/weibo.txt ...
- 【bat/cmd】脚本开发
0. 开篇 bat/cmd 均是window操作系统下,两者都是通过文本方式编辑,创建以及查看.均是命令的集合.bat与cmd有什么区别呢 ? 1) cmd文件允许使用的命令比bat多,但是只有在wi ...
- 安卓Android Support Design Library——Snackbar
介绍: Snackbar是Android Support Design Library库支持的一个控件,用于在界面下面提示一些关键信息,跟Toast不同的地方是SnackBar允许用户向右滑动消除它, ...
- 【Java并发编程】:生产者—消费者模型
生产者消费者问题是线程模型中的经典问题:生产者和消费者在同一时间段内共用同一存储空间,生产者向空间里生产数据,而消费者取走数据. 这里实现如下情况的生产--消费模型: 生产者不断交替地生产两组数据“姓 ...
- jenkins自动部署tomcat
关于部署的3种思路: 远程部署(jenkins编译部署到远程服务器): 安装ssh插件 ssh插件配置 添加远程jenkins服务器节点: 本地部署(与jenkins在同一服务器): 关于maven构 ...
- hibernate的配置文件,使用XML方式
<?xml version="1.0" encoding="UTF-8"?> <!-- 标准的XML文件的起始行,version='1.0'表 ...
- 为android游戏开发-准备的地图编辑器-初步刷地图
采用多文理混合,单页面支持8张文理进行刷绘