C++:哈希
1.基本概念
哈希一般用来快速查找,通过hash函数将输入的键值(key)映射到某一个地址,然后就可以获得该地址的内容。
同样,如果要储存一对值(键值和数据),则也是通过hash函数获得地址来存入。见图例:
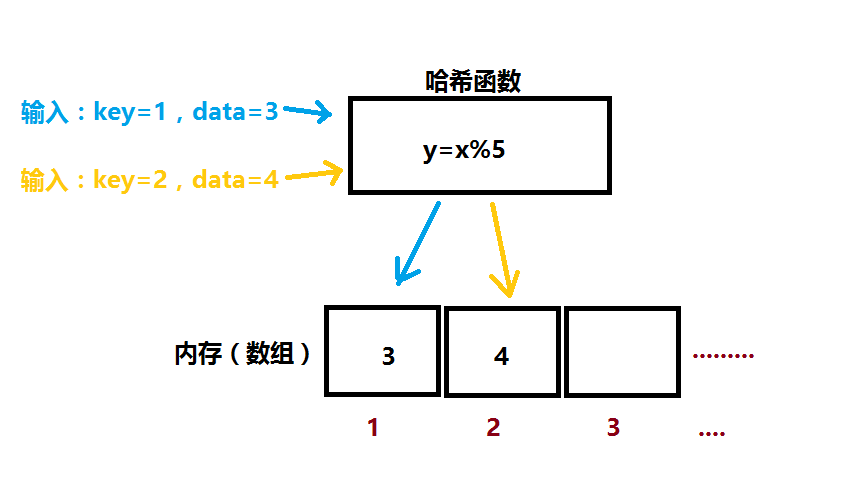
不过这其中会出现一些问题,最常见的是出现冲突。就是输入不同的key,经过hash之后得到同样的值,也就是在同一个地址要储存不同的data,
例如使用上图的hash,输入的key为1和11得到的地址都是1,则这种就是出现了冲突。
解决这种冲突的方法有多种,比如线性探测法,折叠法,链表法等等。
2.实例
下面是一个基于C++的简单的模板类,使用链表法来解决冲突。该hash类的数据结构为:
struct data
{
size_t key;
map_t content;
bool isEmpty;
data * next;
data() :isEmpty(true), next(nullptr){}
};
程序:
template<typename map_t>
class MyHash
{
public:
MyHash() :size()
{
store = new data[size];
}
MyHash(size_t s) :size(s)
{
store = new data[size];
}
~MyHash()
{
delete[]store;
}
public:
bool insert(size_t key, map_t val);
bool find(size_t key, map_t & val);
bool erase(size_t key);
void print(); private:
size_t size;
struct data
{
size_t key;
map_t content;
bool isEmpty;
data * next;
data() :isEmpty(true), next(nullptr){}
}; data * store;
size_t hash(size_t key);
}; template<typename map_t>
bool MyHash<map_t>::insert(size_t key, map_t val)
{
size_t t_k = hash(key);
if (t_k >= size || t_k < )
return false;
if (!store[t_k].isEmpty)
{
data * temp_ptr = & store[t_k];
while (temp_ptr->next!=nullptr)
{
temp_ptr = temp_ptr->next;
if (temp_ptr->key == key)
{
temp_ptr->content = val;
return true;
}
}
data *new_ = new data; new_->key = key;
new_->content = val;
new_->isEmpty = false;
new_->next = nullptr;
temp_ptr->next = new_; return true;
} data* new_ = new data;
new_->key = key;
new_->content = val;
new_->isEmpty = false;
new_->next = nullptr; store[t_k].next = new_;
store[t_k].isEmpty = false; return true;
}
template<typename map_t>
bool MyHash<map_t>::find(size_t key, map_t& val)
{
size_t t_k = hash(key);
if (t_k >= size || t_k < )
return false; data * temp_ptr = &store[t_k];
while (temp_ptr->next != nullptr)
{
temp_ptr = temp_ptr->next;
if (temp_ptr->key == key)
{
val = temp_ptr->content;
return true;
}
}
return false;
}
template<typename map_t>
bool MyHash<map_t>::erase(size_t key)
{
size_t t_k = hash(key);
if (t_k >= size || t_k < || store[t_k].isEmpty)
return false; data * temp_ptr = &store[t_k];
data * temp_ptr_ = &store[t_k];
while (temp_ptr->next!=nullptr)
{
temp_ptr_ = temp_ptr;
temp_ptr = temp_ptr->next;
if (temp_ptr->key == key)
{
temp_ptr_->next = temp_ptr->next;
delete temp_ptr;
return true;
}
} return false;
}
template<typename map_t>
void MyHash<map_t>::print()
{
for (int i = ; i < size; ++i)
{
if (!store[i].isEmpty)
{
cout << i << " : "; data * temp_ptr = &store[i];
while (temp_ptr->next != nullptr)
{
temp_ptr = temp_ptr->next;
cout << " - " << temp_ptr->content;
}
cout << endl;
}
}
} template<typename map_t>
size_t MyHash<map_t>::hash(size_t key)
{
return key%size;
}
C++:哈希的更多相关文章
- [PHP内核探索]PHP中的哈希表
在PHP内核中,其中一个很重要的数据结构就是HashTable.我们常用的数组,在内核中就是用HashTable来实现.那么,PHP的HashTable是怎么实现的呢?最近在看HashTable的数据 ...
- java单向加密算法小结(2)--MD5哈希算法
上一篇文章整理了Base64算法的相关知识,严格来说,Base64只能算是一种编码方式而非加密算法,这一篇要说的MD5,其实也不算是加密算法,而是一种哈希算法,即将目标文本转化为固定长度,不可逆的字符 ...
- Java 哈希表运用-LeetCode 1 Two Sum
Given an array of integers, find two numbers such that they add up to a specific target number. The ...
- 网络安全——Base64编码、MD5、SHA1-SHA512、HMAC(SHA1-SHA512)哈希
据说今天520是个好日子,为什么我想起的是502.500.404这些?还好服务器没事! 一.Base64编码 Base64编码要求把3个8位字节(3*8=24)转化为4个6位的字节(4*6=24),之 ...
- Oracle 哈希连接原理
<基于Oracle的sql优化>里关于哈希连接的原理介绍如下: 哈希连接(HASH JOIN)是一种两个表在做表连接时主要依靠哈希运算来得到连接结果集的表连接方法. 在Oracle 7.3 ...
- SQL连接操作符介绍(循环嵌套, 哈希匹配和合并连接)
今天我将介绍在SQLServer 中的三种连接操作符类型,分别是:循环嵌套.哈希匹配和合并连接.主要对这三种连接的不同.复杂度用范例的形式一一介绍. 本文中使用了示例数据库AdventureWorks ...
- BZOJ 3555: [Ctsc2014]企鹅QQ [字符串哈希]【学习笔记】
3555: [Ctsc2014]企鹅QQ Time Limit: 20 Sec Memory Limit: 256 MBSubmit: 2046 Solved: 749[Submit][Statu ...
- [bzoj3207][花神的嘲讽计划Ⅰ] (字符串哈希+主席树)
Description 背景 花神是神,一大癖好就是嘲讽大J,举例如下: “哎你傻不傻的![hqz:大笨J]” “这道题又被J屎过了!!” “J这程序怎么跑这么快!J要逆袭了!” …… 描述 这一天D ...
- minHash最小哈希原理
minHash最小哈希原理 收藏 初雪之音 发表于 9个月前 阅读 208 收藏 9 点赞 1 评论 0 摘要: 在数据挖掘中,一个最基本的问题就是比较两个集合的相似度.通常通过遍历这两个集合中的所有 ...
- .net的一致性哈希实现
最近在项目的微服务架构推进过程中,一个新的服务需要动态伸缩的弹性部署,所有容器化示例组成一个大的工作集群,以分布式处理的方式来完成一项工作,在集群中所有节点的任务分配过程中,由于集群工作节点需要动态增 ...
随机推荐
- PKU 2002 Squares(二维点哈希+平方求余法+链地址法)
题目大意:原题链接 给定平面上的N个点,求出这些点一共可以构成多少个正方形. 解题思路: 若正方形为ABCD,A坐标为(x1, y1),B坐标为(x2, y2),则很容易可以推出C和D的坐标.对于特定 ...
- c++之旅:继承
继承 继承有关于权限的继承,多继承和虚继承 权限继承 权限继承有公有继承,保护继承和私有继承 公有继承 公有继承可以继承父类的public和protected属性和方法 #include <io ...
- 基础知识总结之 jdk部分
第一次安装jdk 按照操作走完 会出现 C:\Program Files\Java\jdk1.8.0_91 和 C:\Program Files\Java\jre1.8.0_91 两个目录 (平级目 ...
- Object的各种方法
Object的一些知识点总结 1.hasOwnProperty obj.hasOwnProperty(prop) 参数 prop: 要检测的属性字符串名称或者Symbol 返回值 用来判断一个对象是否 ...
- 延迟环境变量扩展(bat)
延迟环境变量扩展(bat) 之前遇到一些环境变量的问题,简单记录下 From:http://www.cnblogs.com/dongzhiquan/archive/2012/09/05/2671218 ...
- RocEDU.阅读.写作《苏菲的世界》书摘
我们在成长的过程当中,似乎失去了对这世界的好奇心.也正因此,我们丧失了某种极为重要的能力(这也是一种哲学家们想要使人们恢复的能力).因为,在我们内心的某处,有某个声音告诉我们:生命是一种很庞大的.神秘 ...
- iOS开发进阶 - 项目的本地化处理(多语言开发)
移动端访问不佳,请访问我的个人博客 最近项目本地化,需要支持多国语言,下面将本地化的步骤记录下来,方便查找使用,步骤很简单,有些地方也有坑,希望大家看后少走弯路~~ 什么是本地化 本地化说直白点就是多 ...
- Tomcat的配置,设置内存,获取用户IP
一.修改配置文件 tomcat配置文件路径/tomcat/bin/server.xml # shutdown指定终止Tomcat服务器运行时,发给Tomcat 服务器的shutdown监听端口的字符串 ...
- mysql类似递归的一种操作进行层级查询
select device_id,device_type,COUNT(1) count from ( select t1.device_id,t1.device_type,DATE_SUB(t1.re ...
- Mybatis中使用自定义的类型处理器处理枚举enum类型
知识点:在使用Mybatis的框架中,使用自定义的类型处理器处理枚举enum类型 应用:利用枚举类,处理字段有限,可以用状态码,代替的字段,本实例,给员工状态字段设置了一个枚举类 状态码,直接赋值给对 ...