梯度下降(Gradient descent)
首先,我们继续上一篇文章中的例子,在这里我们增加一个特征,也即卧室数量,如下表格所示:

因为在上一篇中引入了一些符号,所以这里再次补充说明一下:
x‘s:在这里是一个二维的向量,例如:x1(i)第i间房子的大小(Living area),x2(i)表示的是第i间房子的卧室数量(bedrooms).
在我们设计算法的时候,选取哪些特征这个问题往往是取决于我们个人的,只要能对算法有利,尽量选取。
对于假设函数,这里我们用一个线性方程(在后面我们会说到运用更复杂的假设函数):hΘ(x) = Θ0+Θ1x1+Θ2x2
这里,θi为参数,也称为权值(weights)。我们假定x0 = 1。因此上述可以表示为矩阵形式:
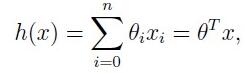

梯度下降法是按下面的流程进行的:
1)首先对θ赋值,这个值可以是随机的,也可以让θ是一个全零的向量。
2)改变θ的值,使得J(θ)按梯度下降的方向进行减少。
如下图:

上图表示的是参数Θ和代价函数J(Θ)的关系图,深蓝色为全局最小,浅蓝色为局部最小,红色则表示J(Θ)有一个较大的取值,而梯度下降算法就是我们给定一个初始的Θ值,然后按照梯度下降的原则不断更新Θ值,使得J(Θ)向更低的方向进行移动。算法的结束将是在θ下降到无法继续下降为止。上面两条线代表我们给定两个初值,我们发现一条到达局部最小,即浅蓝色,而一条到达全局最小,即深蓝色。所以从这里我们可以看出,初始值的选择对梯度下降的影响很大。


如果 α 太大,那么梯度下降法可能会越过最低点,甚至可能无法收敛, 下一次迭代又移动了一大步,越过一次,又越过一次,一次次越过最低点,直到你发现实际上离最低点越来越远,所以,如果 α 太大,它会导致无法收敛,甚至发散。
批量梯度下降算法(batch gradient descent)



随机梯度下降算法(stochastic gradient descent)
当样本集数据量m很大时,由于每次在进行批量梯度下降时都需要用到所有的训练样本,所以开销就会很大,这个时候我们更多时候使用随机梯度下降算法(stochastic gradient descent),算法如下所示:

在进行随机梯度下降算法时,我们每次迭代都只选取一个训练样本,这样当我们迭代到若干样本的时候Θ就已经迭代到最优解了。
正规方程(The Normal equations)
梯度下降给我们提供了一种最小化J的方法,除了梯度下降,正规方程也是一种很好求解Θ的方法,这里只给出结论,如下

梯度下降(Gradient descent)的更多相关文章
- 机器学习(1)之梯度下降(gradient descent)
机器学习(1)之梯度下降(gradient descent) 题记:最近零碎的时间都在学习Andrew Ng的machine learning,因此就有了这些笔记. 梯度下降是线性回归的一种(Line ...
- 梯度下降(Gradient Descent)小结 -2017.7.20
在求解算法的模型函数时,常用到梯度下降(Gradient Descent)和最小二乘法,下面讨论梯度下降的线性模型(linear model). 1.问题引入 给定一组训练集合(training se ...
- 梯度下降(gradient descent)算法简介
梯度下降法是一个最优化算法,通常也称为最速下降法.最速下降法是求解无约束优化问题最简单和最古老的方法之一,虽然现在已经不具有实用性,但是许多有效算法都是以它为基础进行改进和修正而得到的.最速下降法是用 ...
- (二)深入梯度下降(Gradient Descent)算法
一直以来都以为自己对一些算法已经理解了,直到最近才发现,梯度下降都理解的不好. 1 问题的引出 对于上篇中讲到的线性回归,先化一个为一个特征θ1,θ0为偏置项,最后列出的误差函数如下图所示: 手动求解 ...
- CS229 2.深入梯度下降(Gradient Descent)算法
1 问题的引出 对于上篇中讲到的线性回归,先化一个为一个特征θ1,θ0为偏置项,最后列出的误差函数如下图所示: 手动求解 目标是优化J(θ1),得到其最小化,下图中的×为y(i),下面给出TrainS ...
- 机器学习中的数学(1)-回归(regression)、梯度下降(gradient descent)
版权声明: 本文由LeftNotEasy所有,发布于http://leftnoteasy.cnblogs.com.如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任. 前言: ...
- 回归(regression)、梯度下降(gradient descent)
本文由LeftNotEasy所有,发布于http://leftnoteasy.cnblogs.com.如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任. 前言: 上次写过一篇 ...
- 吴恩达深度学习:2.3梯度下降Gradient Descent
1.用梯度下降算法来训练或者学习训练集上的参数w和b,如下所示,第一行是logistic回归算法,第二行是成本函数J,它被定义为1/m的损失函数之和,损失函数可以衡量你的算法的效果,每一个训练样例都输 ...
- (3)梯度下降法Gradient Descent
梯度下降法 不是一个机器学习算法 是一种基于搜索的最优化方法 作用:最小化一个损失函数 梯度上升法:最大化一个效用函数 举个栗子 直线方程:导数代表斜率 曲线方程:导数代表切线斜率 导数可以代表方向, ...
随机推荐
- [置顶]
记最近一次Nodejs全栈开发经历
背景: 前段时间大部门下新成立了一个推广百度OCR.文字识别.图像识别等科技能力在金融领域应用的子部门.因为部门刚成立,基础设施和人力都是欠缺的.当时分到我们部门的任务是抽调一个人做新部门主站前端开发 ...
- html2canvas 截屏 兼容手机端
<template> <div> <!--<input type="button" id="btnsavaImg" valu ...
- iOS中数组遍历的方法及比较
数组遍历是编码中很常见的一种需求,我们来扒一拔iOS里面都有什么样的方法来实现,有什么特点. 因为ios是兼容C语言的,所以c语言里面的最最常见的for循环遍历是没有问题的. 本文中用的数组是获取的系 ...
- pandas.read_csv()参数(转载)
文章转载地址 pandas.read_csv参数整理 读取CSV(逗号分割)文件到DataFrame 也支持文件的部分导入和选择迭代 更多帮助参见:http://pandas.pydata.org/p ...
- Redis安全性配置
最近Redis刚爆出一个安全性漏洞,我的服务器就“光荣的”中招了.黑客攻击的基本方法是: 扫描Redis端口,直接登录没有访问控制的Redis 修改Redis存盘配置:config set dir / ...
- ranch分析学习(三)
接着上一篇继续研究 上一篇结尾的时候,我们谈到了连接,监听两个监督树,今天我们就来看看这两个监督树和他们的工作者都是干什么的,怎么实现的.文件编号接上篇. 6. ranch_acceptors_sup ...
- xcopy 提示文件 还是目录
xcopy /y a.jpg .\pics\b.jpg很多次,但xcopy总是问我“文件名还是目录名”gg了一下,发现答案可以这样通过管道来做echo f | xcopy /y a.jpg .\pic ...
- PHP---文件上传与下载
转自http://www.cnblogs.com/lazycat-cz/p/4113037.html 安全性能---水平不够 ╮(╯_╰)╭ 文件上传--->就是将本地的文件上传到服务器上.(H ...
- LOJ2424 NOIP2015 子串 【DP】*
LOJ2424 NOIP2015 子串 LINK 题目大意是给你两个序列,在a序列中选出k段不重叠的子串组成b序列,问方案数 首先我们不考虑相邻的两段,把所有相邻段当成一段进行计算 然后设dpi,j, ...
- CnetOS7使用yum方式安装nginx
之前一直使用源码包安装,但是对于需要一直进行重新安装的测试环境来说安装起来还是过于麻烦了.今天搜索发现能够进行yum方式的安装,特此记录. 新建yum文件,yum源是nginx的官网. # vim / ...