Spark2.0机器学习系列之10: 聚类(高斯混合模型 GMM)
在Spark2.0版本中(不是基于RDD API的MLlib),共有四种聚类方法:
(1)K-means
(2)Latent Dirichlet allocation (LDA)
(3)Bisecting k-means(二分k均值算法)
(4)Gaussian Mixture Model (GMM)。
基于RDD API的MLLib中,共有六种聚类方法:
(1)K-means
(2)Gaussian mixture
(3)Power iteration clustering (PIC)
(4)Latent Dirichlet allocation (LDA)**
(5)Bisecting k-means
(6)Streaming k-means
多了Power iteration clustering (PIC)和Streaming k-means两种。
本文将介绍其中的一种高斯混合模型 ,Gaussian Mixture Model (GMM)。其它方法在我的Spark机器学习系列里面,都会介绍。
混合模型:通过密度函数的线性合并来表示未知模型p(x)
为什么提出混合模型,那是因为单一模型与实际数据的分布严重不符,但是几个模型混合以后却能很好的描述和预测数据。
高斯混合模型(GMM),说的是把数据可以看作是从数个高斯分布中生成出来的。虽然我们可以用不同的分布来随意地构造 XX Mixture Model ,但是 GMM是最为流行。另外,Mixture Model 本身其实也是可以变得任意复杂的,通过增加 Model 的个数,我们可以任意地逼近任何连续的概率密分布。
二维情况下高斯分布模拟产生数据的分布是椭圆,如下图:

对于下面图(a)观测数据,单一的高斯概率分布函数(一个椭圆)无法表达,仔细看图(a)近似包含三个椭圆,所以可以将三个高斯概率分布函数线性组合起来,各个函数有不同的参数N(σi,μi)和权重πi。线性组合
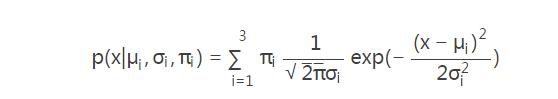
这样就能计算所有样本出现的概率了。图(b)已经明确了样本分类。 

由于在对数函数里面又有加和,我们没法直接用求导解方程的办法直接求得最大值。为了解决这个问题,采用了EM方法。
EM算法可参考我的另一篇文章
《机器学习算法(优化)之二:期望最大化(EM)算法》http://www.cnblogs.com/itboys/p/8400044.html.
EM算法模型参数估计
每个GMM由K个Gaussian component分布组成。我以一维Gaussian函数,GMM模型有3个隐含component为例,通俗的说明。
E过程: 
迭代的第t步,对于观测到的x点,那么他究竟是3个隐含的Gaussina曲线中的那一个产生的呢?应该说都有可能,只是产生的概率大小不一样而已。如图中的x点,它由N(x;μ3,σ3)产生的可能性最大,概率为π3∗N(x;μ3,σ3),假设为0.4*0.30=0.12,其次是π2∗N(x;μ2,σ2),假设为0.3*0.15=0.045,最小是π1∗N(x;μ1,σ1),假设为0.3*0.02=0.006。因此x出现总的概率是0.12+0.045+0.006=0.1656。
从另一个角度看,对于观测到的某个点x,推测是由N(x;μ3,σ3)产生的可能性有多大,自然我们认为是:0.12/0.1656=0.7246(虽然非常简单,但是理解这一点是后面E步公式得出的关键点);以此类推测,x是由N(x;μ2,σ2)产生的可能性=0.045/0.1656=0.2717,x是由N(x;μ1,σ1)产生的可能性0.006/0.1656=0.0362。

更一般地,GMM认为数据是从K个高斯函数组合而来的,即
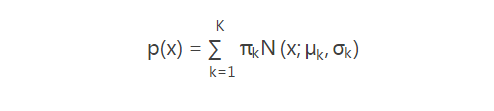
隐含K个高斯函数,K需要首先确定好。任意高斯分布定义为N(x;μk,σk),k=1,2,...K.
(1)E:对于观测点xi,是由第k个component产生的概率为
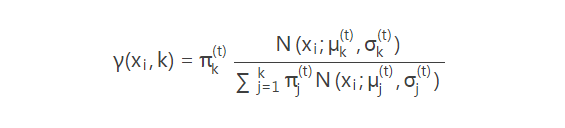
(2)M:xi可以看作是有各部分加和而成的,其中由第k个component产生部分自然为:γ(xi,k)xi,所以可以认为第k个component产生了如下的数据:

这样就完成了参数的更新,重复E步骤进行下一次迭代,直到算法收敛。
模型参数K设置及聚类结果评估
大家可能会想到,上图(a)中的数据分布太具有实验性质了,实际中那有这样的数据,但GMM牛逼的地方就在于通过增加 Model 的个数(也就是组成成分的数量K,其实就是我们的分类个数),可以任意地逼近任何连续的概率密分布。所以呢,理论上是绝对支持的,而实际上呢,对于多维特征数据我们往往难以可视化,所以难把握的地方也就在这里,如何选取K 值?换句化说聚类(无监督分类)拿什么标准如何评估模型的好坏?因为如果对结果有好评价指标的话,那么我们就可以实验不同的K,选出最优的那个K就好了,到底有没有呢?
这个话题又比较长,有人认为聚类的评估一定要做预先标注,没有Index总是让人觉得不靠谱,不是很让人信服。但是也有不同学者提出了大量的评估方法,主要是考虑到不同聚类算法的目标函数相差很大,有些是基于距离的,比如k-means,有些是假设先验分布的,比如GMM,LDA,有些是带有图聚类和谱分析性质的,比如谱聚类,还有些是基于密度的,所以难以拿出一个统一的评估方法,但是正是有这么些个原理上的不同,记着不与算法本身的原理因果颠倒的情况下,那么针对各类方法还是可以提出有针对性的评价指标的,如k-means的均方根误差。其实更应该嵌入到问题中进行评价,很多实际问题中,聚类仅仅是其中的一步,可以对比不聚类的情形(比如人为分割、随机分割数据集等等),所以这时候我们评价『聚类结果好坏』,其实是在评价『聚类是否能对最终结果有好的影响』。(本部分来综合了知乎上的部分问答:如有不妥之处,敬请告知。http://www.zhihu.com/question/19635522)
关于聚类的评估问题,我计划再写另外一篇文章《Spark聚类结果评估浅析》,不知道能否写好。
CSDN上还有文章可参考: 聚类算法初探(七)聚类分析的效果评测 http://blog.csdn.net/itplus/article/details/10322361
//训练模型
val gmm=new GaussianMixture().setK().setMaxIter().setSeed(1L)
val model=gmm.fit(dataset) //输出model参数
for(i<- until model.getK){
println("weight=%f\nmu=%s\nsigma=\n%s\n" format(model.weights(i), model.gaussians(i).mean, model.gaussians(i).cov))
//weight是各组成成分的权重
//nsigma是样本协方差矩阵
//mu(mean)是各类质点位置
参考文献:
(1)混合高斯模型算法http://www.cnblogs.com/CBDoctor/archive/2011/11/06/2236286.html
(2) 聚类算法初探(七)聚类分析的效果评测 http://blog.csdn.net/itplus/article/details/10322361
(3)知乎 http://www.zhihu.com/question/19635522
(4)Rachel-Zhang的CSDN博客GMM的EM算法实现 http://blog.csdn.net/abcjennifer/article/details/8198352
(5)漫谈 Clustering (3): Gaussian Mixture Model http://blog.pluskid.org/?p=39
Spark2.0机器学习系列之10: 聚类(高斯混合模型 GMM)的更多相关文章
- Spark2.0机器学习系列之11: 聚类(幂迭代聚类, power iteration clustering, PIC)
在Spark2.0版本中(不是基于RDD API的MLlib),共有四种聚类方法: (1)K-means (2)Latent Dirichlet all ...
- Spark2.0机器学习系列之1: 聚类算法(LDA)
在Spark2.0版本中(不是基于RDD API的MLlib),共有四种聚类方法: (1)K-means (2)Latent Dirichlet allocation (LDA) ...
- Spark2.0机器学习系列之9: 聚类(k-means,Bisecting k-means,Streaming k-means)
在Spark2.0版本中(不是基于RDD API的MLlib),共有四种聚类方法: (1)K-means (2)Latent Dirichlet allocation (LDA) ...
- Spark2.0机器学习系列之12: 线性回归及L1、L2正则化区别与稀疏解
概述 线性回归拟合一个因变量与一个自变量之间的线性关系y=f(x). Spark中实现了: (1)普通最小二乘法 (2)岭回归(L2正规化) (3)La ...
- Spark2.0机器学习系列之7: MLPC(多层神经网络)
Spark2.0 MLPC(多层神经网络分类器)算法概述 MultilayerPerceptronClassifier(MLPC)这是一个基于前馈神经网络的分类器,它是一种在输入层与输出层之间含有一层 ...
- Spark2.0机器学习系列之6:GBDT(梯度提升决策树)、GBDT与随机森林差异、参数调试及Scikit代码分析
概念梳理 GBDT的别称 GBDT(Gradient Boost Decision Tree),梯度提升决策树. GBDT这个算法还有一些其他的名字,比如说MART(Multiple Addi ...
- Spark2.0机器学习系列之3:决策树
概述 分类决策树模型是一种描述对实例进行分类的树形结构. 决策树可以看为一个if-then规则集合,具有“互斥完备”性质 .决策树基本上都是 采用的是贪心(即非回溯)的算法,自顶向下递归分治构造. 生 ...
- Spark2.0机器学习系列之2:基于Pipeline、交叉验证、ParamMap的模型选择和超参数调优
Spark中的CrossValidation Spark中采用是k折交叉验证 (k-fold cross validation).举个例子,例如10折交叉验证(10-fold cross valida ...
- Spark2.0机器学习系列之5:随机森林
概述 随机森林是决策树的组合算法,基础是决策树,关于决策树和Spark2.0中的代码设计可以参考本人另外一篇博客: http://www.cnblogs.com/itboys/p/8312894.ht ...
随机推荐
- JavaScript重载
在Javascript 中,每个函数都有一个隐含的对象arguments,表示给函数 实际传给的参数 ,那么我们可以用 arguments来实现函数的重载 <!DOCTYPE html PUBL ...
- 【转】【iOS测试系列】常用测试小插件的使用
背景介绍 由于iOS系统的限制,在非越狱的自动化测试中无法实现一些常用的功能,比如不同应用之间来回切换.模拟全局的点击事件等等.但是在越狱的环境下,这些限制就不存在了,我们可以利用各种小插件来实现我们 ...
- C++ new delete操作符
//new delete操作符 #define _CRT_SECURE_NO_WARNINGS #include<iostream> using namespace std; /* 1.n ...
- 关于Unity中的transform组件(三)
game_root节点下右一个Cube子节点,和一个Sphere节点,脚本挂载在game_root下 四元数:(1)Quaternion rot (2)this.cube.rotation 欧拉角:V ...
- ubuntu vnc安装
VNC(Virtual Network Computing),为一种使用RFB协议的屏幕画面分享及远程操作软件.此软件借由网络,可发送键盘与鼠标的动作及即时的屏幕画面. 1. 安装vnc服务器 sud ...
- 嵌入式开发之davinci--- 8148/8168/8127 中的二维图像处理内存tiler 铺瓷砖
http://blog.csdn.net/shanghaiqianlun/article/details/7619603
- 【BZOJ】1088: [SCOI2005]扫雷Mine(递推)
http://www.lydsy.com/JudgeOnline/problem.php?id=1088 脑残去想递推去了... 对于每一个第二列的格子,考虑多种情况,然后转移.....QAQ 空间可 ...
- linux改动登陆主机提示信息
寻常管理着130多台Linux物理主机.真正搞清楚每一台主机的IP信息.应用部署比較麻烦! 所以在部署之初,必须规划好: 写一个脚本.把主机IP.管理员联系方法,应用部署等主机信息放在.sh里面 sh ...
- centos7安装avahi
sudo yum install avahi sudo yum install avahi-tools 转自: http://unix.stackexchange.com/questions/1829 ...
- hdu 1147:Pick-up sticks(基本题,判断两线段相交)
Pick-up sticks Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)To ...