Python在VSCode环境抓取TuShare数据存入MongoDB环境搭建
本文出自:https://www.cnblogs.com/2186009311CFF/p/11573094.html
总览
此文分为5个部分
第一:Anaconda(下载和安装)
第二:VSCode(下载和安装)
第三:mongoDB(下载和安装)
第四:install 必要的python包
第五:联合运行
1.Anaconda
1.1引入目的
自由切换python版本
1.2下载文件地址
清华大学镜像网:https://mirror.tuna.tsinghua.edu.cn/help/anaconda/
(下载最新版即可)
1.3安装注意点
为了方便,安装时勾选加入环境变量,不然后面还要手动添加环境变量

1.4检测是否安装成功
Conda env list
Conda activate 安装目录
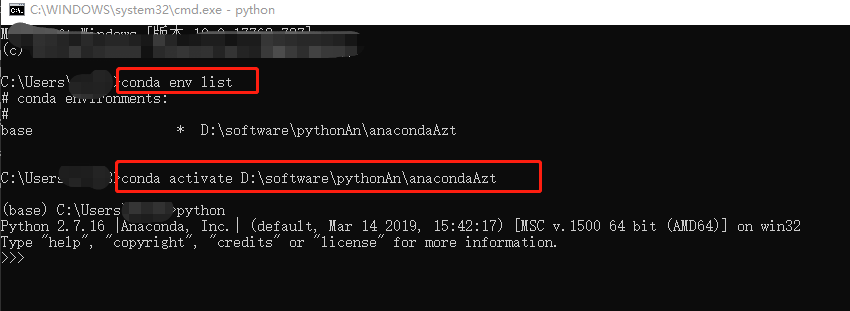
1.5自由切换python版本
(该切换版本步骤,刚安装时,可省略)
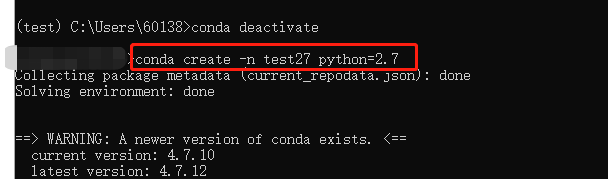
1.5.1 创建版本目录:Conda create -n 文件夹名称 python版本
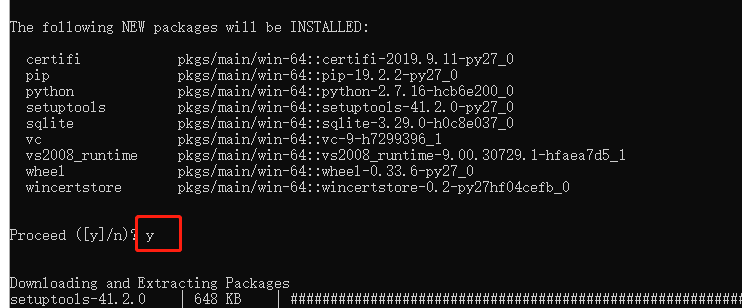
1.5.2 选择Y
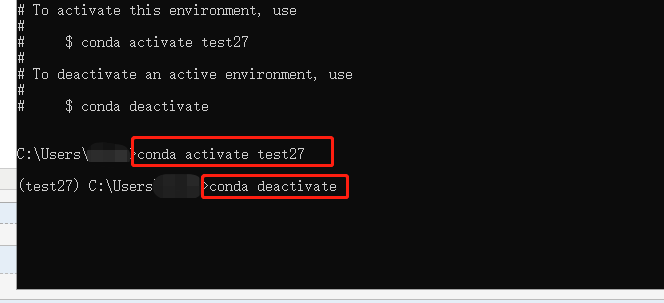
1.5.3 激活版本或关闭该版本
2.VSCode
2.1引入目的
可扩展性强,且免费(主要是PyCharm不免费)
2.2下载文件地址
VSCode官网: https://code.visualstudio.com/Download
2.3设置
文件-首选项-设置
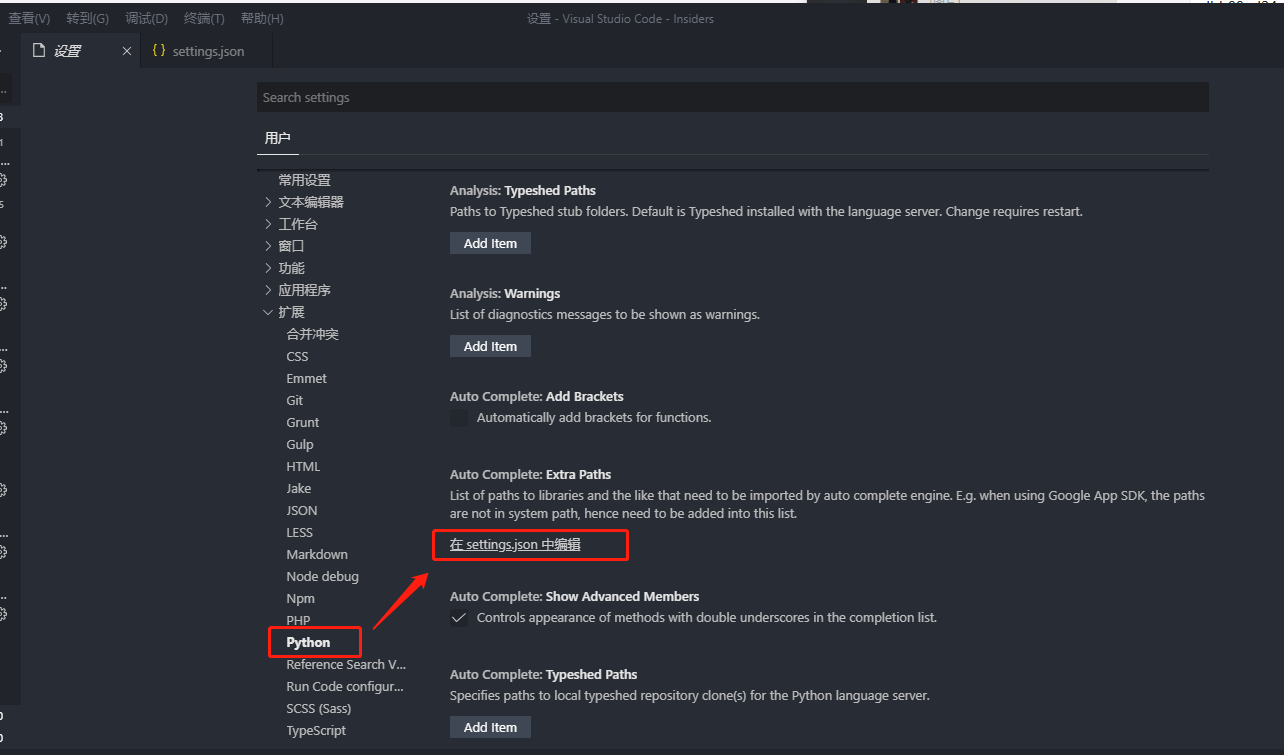
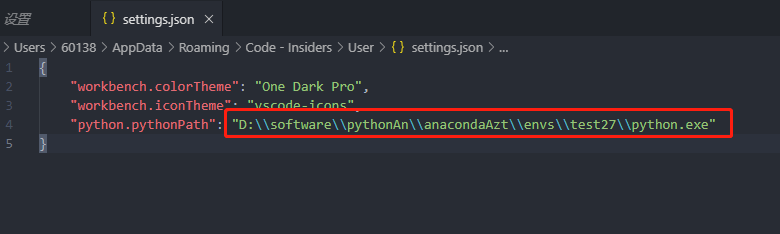
2.4检测是否安装成功
注意: 若vscode一直打开,请重启一下vscode,再运行以下测试程序
选择“文件夹”,打开含有测试*.py文件的文件夹,右键,run code (下方打印出了代码的文字,则安装成功)
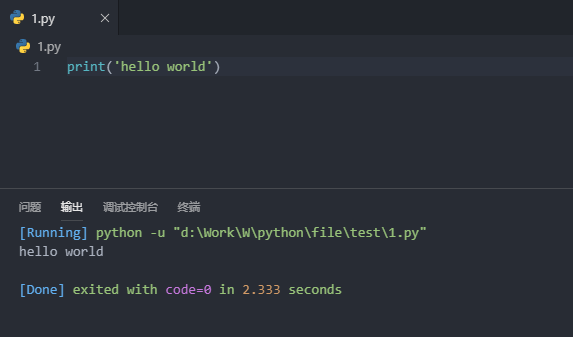
3.Mongodb
3.1引入目的
财务字段多且不固定,这个可延展性好
3.2下载文件地址
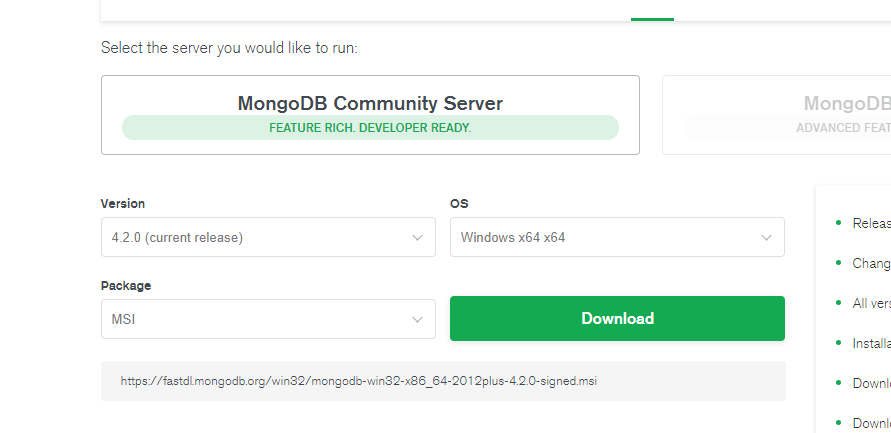
Mongodb官网: https://www.mongodb.com/download-center/community?jmp=docs
选择服务端下载,界面如下图:
创建管理员用户: db.createUser({user: "test1", pwd: "test1", roles: [{role: "root", db: "admin"}]})
mongo 数据库名 -u 用户名-p 密码
3.3检测是否安装成功
打开cmd命令行输入如下相应命令,有相应的图片类似结果,则成功
mongo show dbs use 数据库名 插入测试数据 查询测试数据
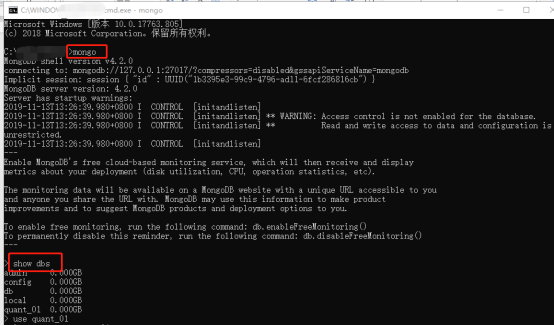
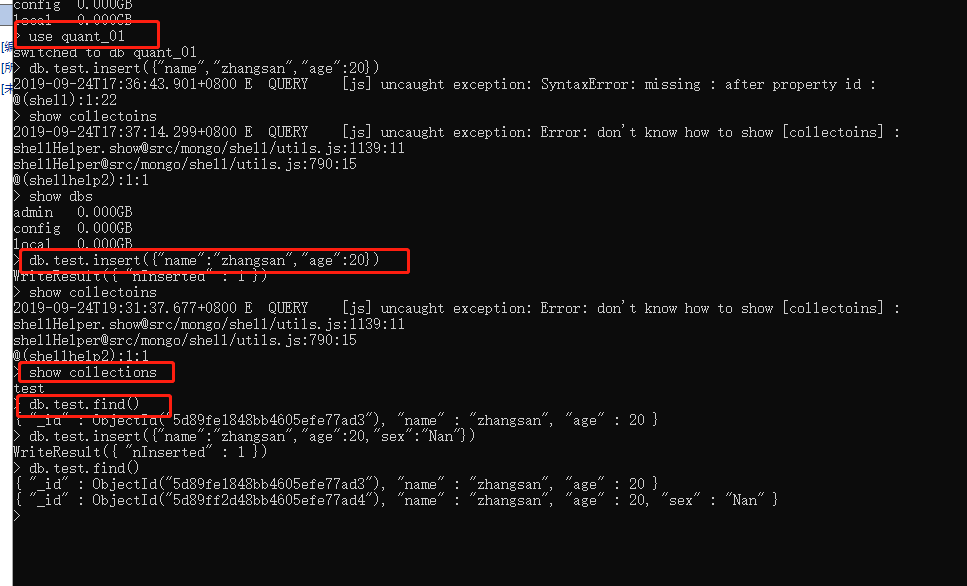
4.install 必要的python包
4.1 方法一:在vscode的终端模块输入相应的命令
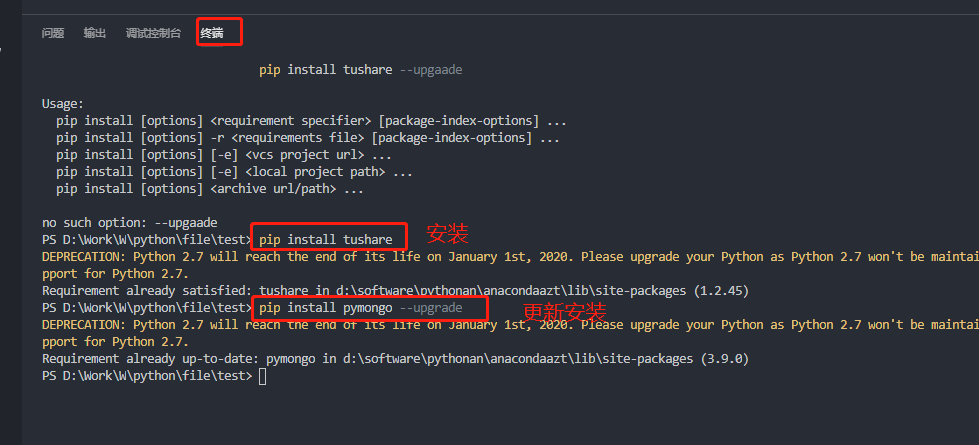
4.2 方法二:Cmd 里的命名行
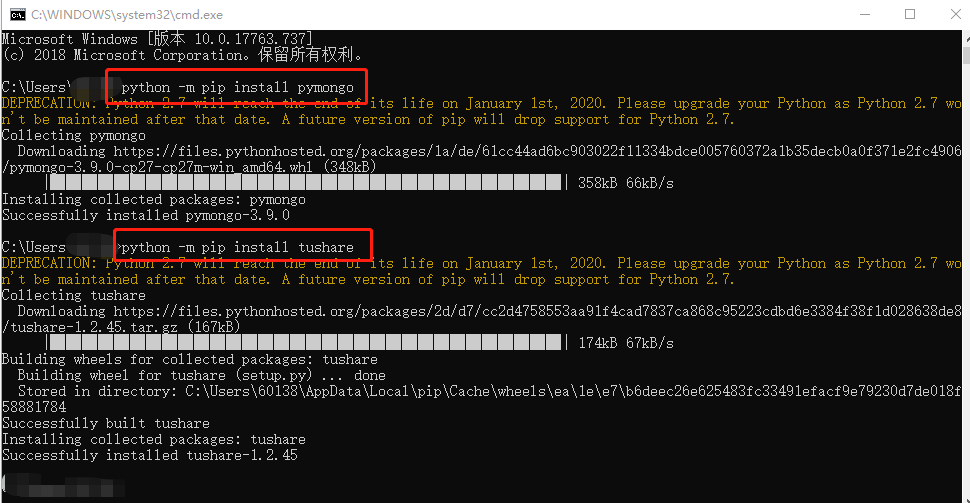
5. 联合运行
5.1 编辑代码,运行
注意:我这边是python3的代码,之前百度连接mongoDB很多是pymongo.Connection,其实要pymongo.MongoClient,这里提醒一下。
import pymongo
import json
import tushare as ts
#import logging
#mport os #logging.basicConfig(filename=os.path.join(os.getcwd(),'log.txt'),level=logging.DEBUG) client = pymongo.MongoClient('127.0.0.1', port=27017)
db=client.pytestdb
collection=db.test_col def basic_usa():
data= ts.get_hist_data('600038',start='2018-01-05',end='2018-01-09')
print(data)
#logging.debug(json.loads(data.to_json(orient='records')))
collection.insert(json.loads(data.to_json(orient='records'))) basic_usa()
#
#print(df)
#client.db.test.insert(json.loads(df.to_json(orient='records')))
5.2 vscode 有如下输出结果:
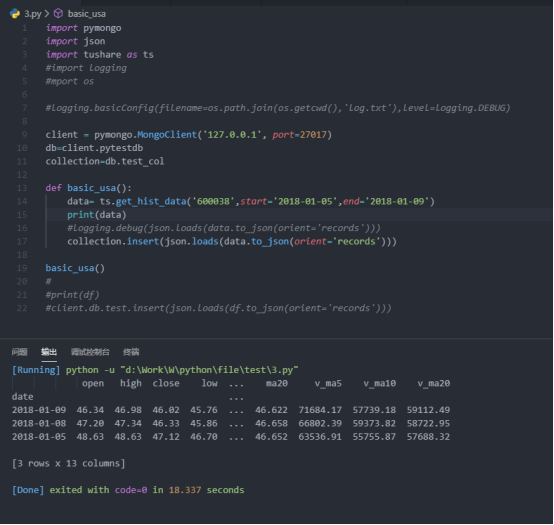
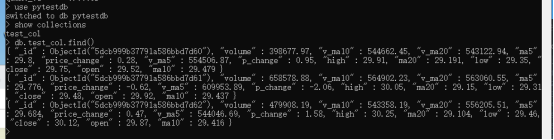
5.3检测是否插入数据库成功
查询相应数据库和表,有如下图结果,则表明联合运行成功。
参考链接
Anaconda安装:
https://blog.csdn.net/yctjin/article/details/80184988
https://blog.csdn.net/vinkim/article/details/81546333
https://blog.csdn.net/weixin_42014622/article/details/94870354
https://www.jianshu.com/p/f10fb1a4cc87 (切换版本)
https://blog.csdn.net/ITLearnHall/article/details/81708148
Mongodb安装:
https://blog.csdn.net/qq_37546891/article/details/83892428
Tushare使用:
https://blog.csdn.net/new_stranger/article/details/83346258
https://blog.csdn.net/yagamil/article/details/77603600
https://blog.csdn.net/m0_37863551/article/details/82914729
VSCode 调试:https://blog.csdn.net/Marvellor/article/details/80877201
Pycharm使用:
https://www.cnblogs.com/honkly/p/8536669.html
微信免密支付:https://pay.weixin.qq.com/wiki/doc/api/pap_sl_jt_v2.php?chapter=20_100&index=12
Python在VSCode环境抓取TuShare数据存入MongoDB环境搭建的更多相关文章
- Python 逆向抓取 APP 数据
今天继续给大伙分享一下 Python 爬虫的教程,这次主要涉及到的是关于某 APP 的逆向分析并抓取数据,关于 APP 的反爬会麻烦一些,比如 Android 端的代码写完一般会进行打包并混淆加密加固 ...
- 手把手教你用python打造网易公开课视频下载软件3-对抓取的数据进行处理
上篇讲到抓取的数据保存到rawhtml变量中,然后通过编码最终保存到html变量当中,那么html变量还会有什么问题吗?当然会有了,例如可能html变量中的保存的抓取的页面源代码可能有些标签没有关闭标 ...
- [Python爬虫] 之八:Selenium +phantomjs抓取微博数据
基本思路:在登录状态下,打开首页,利用高级搜索框输入需要查询的条件,点击搜索链接进行搜索.如果数据有多页,每页数据是20条件,读取页数 然后循环页数,对每页数据进行抓取数据. 在实践过程中发现一个问题 ...
- [Python爬虫] 之四:Selenium 抓取微博数据
抓取代码: # coding=utf-8import osimport refrom selenium import webdriverimport selenium.webdriver.suppor ...
- iOS开发——网络实用技术OC篇&网络爬虫-使用青花瓷抓取网络数据
网络爬虫-使用青花瓷抓取网络数据 由于最近在研究网络爬虫相关技术,刚好看到一篇的的搬了过来! 望谅解..... 写本文的契机主要是前段时间有次用青花瓷抓包有一步忘了,在网上查了半天也没找到写的完整的教 ...
- iOS开发——网络使用技术OC篇&网络爬虫-使用正则表达式抓取网络数据
网络爬虫-使用正则表达式抓取网络数据 关于网络数据抓取不仅仅在iOS开发中有,其他开发中也有,也叫网络爬虫,大致分为两种方式实现 1:正则表达 2:利用其他语言的工具包:java/Python 先来看 ...
- iOS—网络实用技术OC篇&网络爬虫-使用java语言抓取网络数据
网络爬虫-使用java语言抓取网络数据 前提:熟悉java语法(能看懂就行) 准备阶段:从网页中获取html代码 实战阶段:将对应的html代码使用java语言解析出来,最后保存到plist文件 上一 ...
- 用C++实现网络编程---抓取网络数据包的实现方法
一般都熟悉sniffer这个工具,它可以捕捉流经本地网卡的所有数据包.抓取网络数据包进行分析有很多用处,如分析网络是否有网络病毒等异常数据,通信协议的分析(数据链路层协议.IP.UDP.TCP.甚至各 ...
- iOS开发——网络实用技术OC篇&网络爬虫-使用java语言抓取网络数据
网络爬虫-使用java语言抓取网络数据 前提:熟悉java语法(能看懂就行) 准备阶段:从网页中获取html代码 实战阶段:将对应的html代码使用java语言解析出来,最后保存到plist文件 上一 ...
随机推荐
- div随着屏幕滚动而滚动
<script type="text/javascript"> $(document).ready(function () { var menuYloc = $(&qu ...
- Python操作 RabbitMQ、Redis、Memcache
Python操作 RabbitMQ.Redis.Memcache Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数 ...
- Oracle数据块
最小单位的输入\输出 数据块由操作系统中的一个或多个块组成 数据库是表空间的基本单位 DB_BLOCK_SIZE 查看 Oracle 块的大小语句: SQL> show parameter db ...
- 啃掉Hadoop系列笔记(01)-Hadoop框架的大数据生态
一.Hadoop是什么 1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构 2)主要解决,海量数据的存储和海量数据的分析计算问题. 3)广义上来说,HADOOP通常是指一个更广泛的概 ...
- c++ split(getline实现)
众所周知 c++中string没有自带的split函数(亏你还是老大哥) 网上关于split函数的优秀写法很多 本人不再赘述 今几日翻C++API时发现了getline一个有趣的方法 istream& ...
- 大数据学习(1)-shell脚本注意事项
1.变量=值 (例如STR=abc) 不用加引号,但此时空格不再是空格字符,特殊字符可用于转义 2.等号两侧不能有空格 3.变量名称一般习惯为大写 4.双引号和单引号有区别,双引号仅将空格脱意,单引 ...
- ASP.NET Core[源码分析篇] - Authentication认证
原文:ASP.NET Core[源码分析篇] - Authentication认证 追本溯源,从使用开始 首先看一下我们通常是如何使用微软自带的认证,一般在Startup里面配置我们所需的依赖认证服务 ...
- JS基础_JS的HelloWorld
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- ubuntu 安装vim报错
问题:ubuntu18.04默认没有安装vim,使用 sudo apt install 提示 错误信息: 下列信息可能会对解决问题有所帮助: 下列软件包有未满足的依赖关系: vim : 依赖: vim ...
- java实现spark常用算子之mapPartitions
import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.a ...