R语言爬取动态网页之环境准备
在R实现pm2.5地图数据展示文章中,使用rvest包实现了静态页面的数据抓取,然而rvest只能抓取静态网页,而诸如ajax异步加载的动态网页结构无能为力。在R语言中,爬取这类网页可以使用RSelenium包和Rwebdriver包。
RSelenium包和Rwebdriver包都是通过调用Selenium Server来模拟浏览器环境。其中,Selenium是一个用于网页测试的Java开源软件,它可以模拟浏览器的点击、滚动、滑动以及文字输入等操作。因为Selenium是Java程序,因此在使用RSelenium包和Rwebdriver包之前必须为计算机设置Java环境。以下是使用RSelenium包和Rwebdriver包的前期准备步骤:
一、RSelenium包和Rwebdriver包的下载安装
RSelenium包从CRAN直接下载安装,Rwebdriver包则需要从github上下载,下载过程参考install_github无法安装 Rwebdriver包的解决方法
二、Java环境的设置
理论上讲,调用Java程序安装JRE(Java Runtime Environment)即可,但本文推荐安装JDK(Java Development Kit),JDK中包含JRE模块,且网上找到的Java环境变量设置教程多针对JDK。
1、 JDK的下载
本文档中下载最新版的jdk-11.0.1_windows-x64_bin.zip
2、 JDK的安装
由于下载的是无需安装的版本,直接将文件解压出来,放到D:\Program Files\java目录下即可
3、环境变量的设置(可参考Java环境变量设置)
需设置JAVA_HOME,CLASS_PATH,PATH三个环境变量
JAVA_HOME
D:\Program Files\java\jdk-11.0.1
CLASSPATH
%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
PATH
%JAVA_HOME%\bin
三个环境变量设置好以后,打开cmd,输入javac,不报错即表示安装成功。
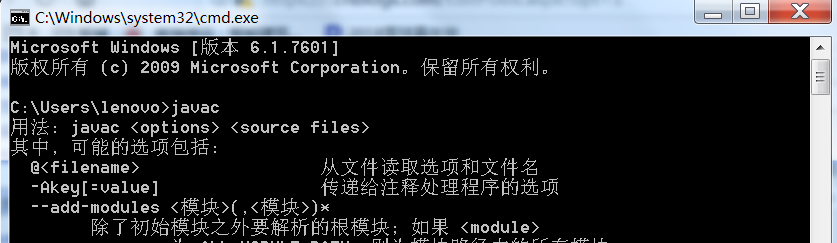
三、selenium以及浏览器驱动的下载和运行
1、下载selenium,网址为https://www.seleniumhq.org/download/
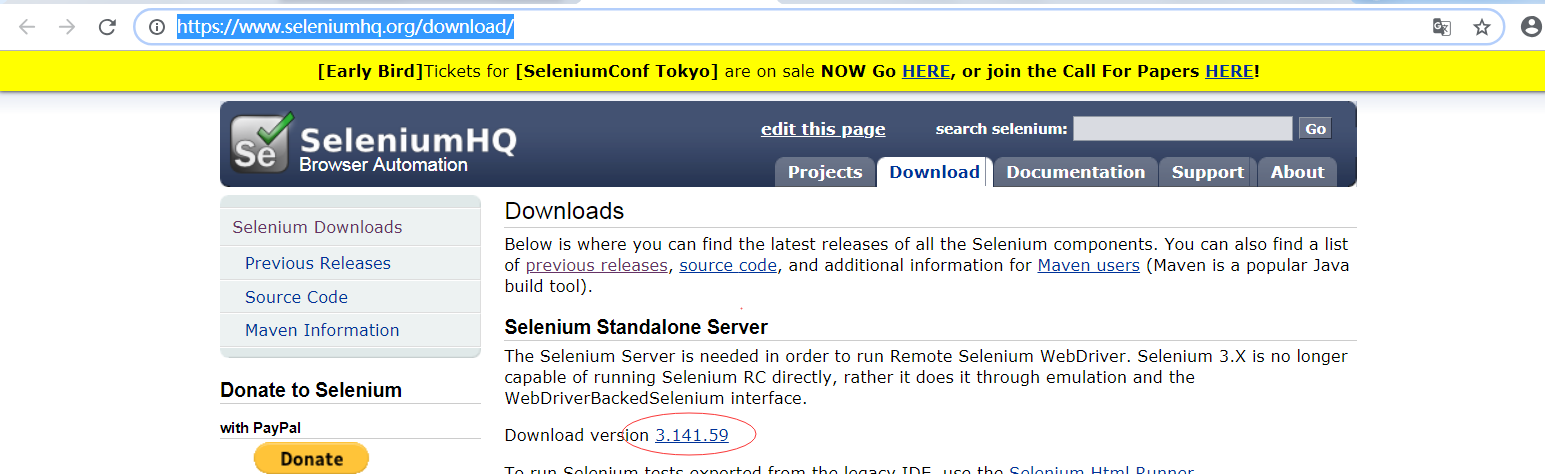
下载最新版本,也可以到http://selenium-release.storage.googleapis.com/index.html下载之前的版本。
2、下载浏览器驱动
Chrome驱动:http://npm.taobao.org/mirrors/chromedriver
Firefox驱动:http://github.com/mozilla/geckodriver/releases
下载时要注意自己浏览器的版本,如果使用Chrome浏览器可参考selenium之chromedriver与chrome版本映射表(更新至v2.34)。
在本环境中下载的是最新时间的v2.44版本
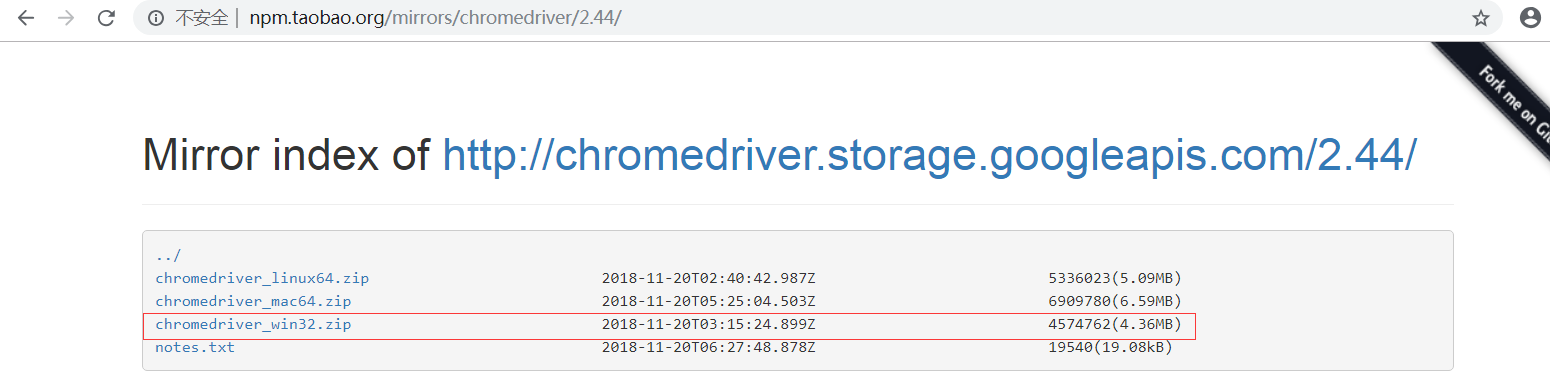
3、打开cmd运行selenium和浏览器驱动,比如我使用的是Chrome浏览器,因此在cmd中输入java -Dwebdriver.chrome.driver="E:\Selenium\chromedriver.exe" -jar E:\Selenium\selenium-server-standalone-3.141.59.jar

如出现下图所示界面,则启动成功(在R语言调用RSelenium包和Rwebdriver包时,cmd不要关闭)。

四、至此所有前期准备就都已完成,可以使用RSelenium包和Rwebdriver包了。
以RSelenium包为例
library(RSelenium) remDr <- remoteDriver(
browserName = "chrome",
remoteServerAddr = "localhost",
port = 4444
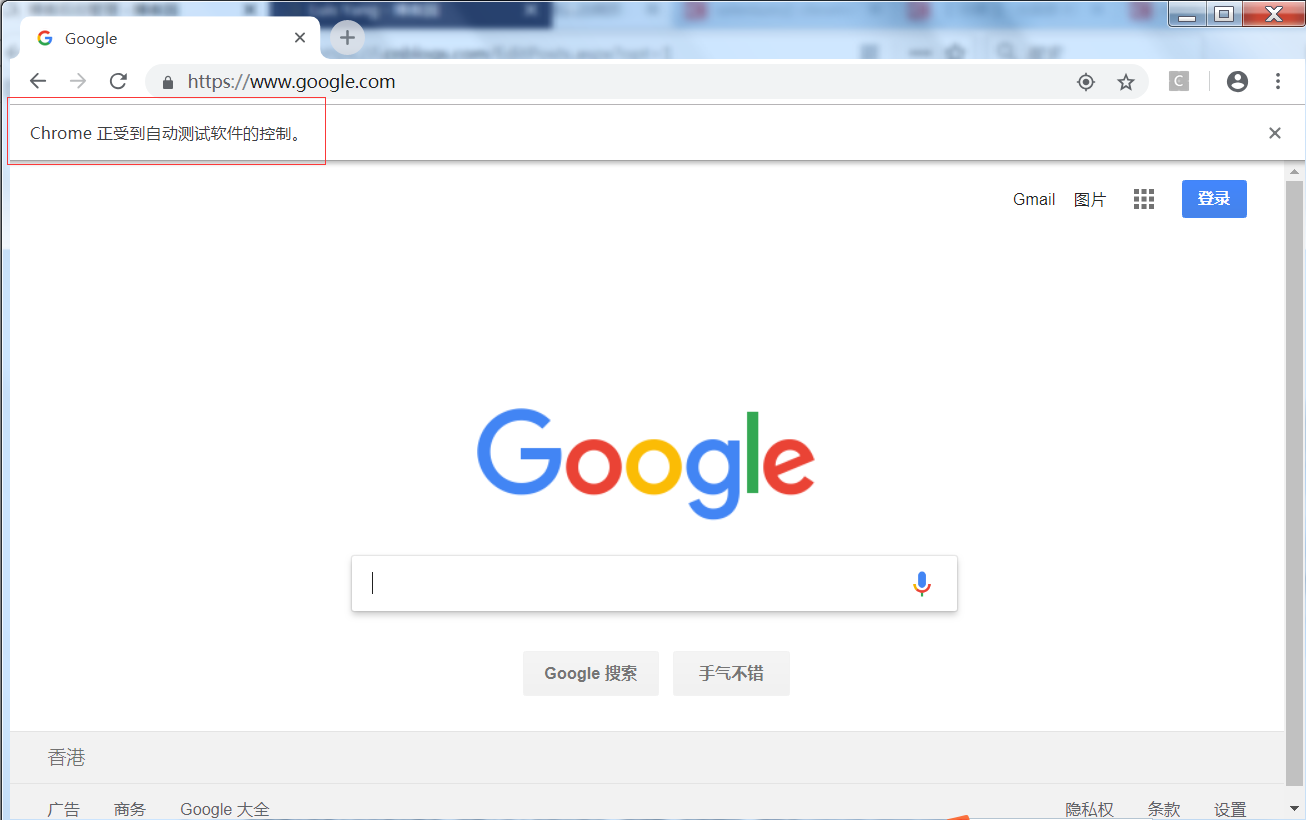
) remDr$open() url <- 'https://www.google.com/' remDr$navigate(url)
可以看到“Chrome正受到自动测试软件的控制”字样。
此时再使用rvest包对网页进行抓取,抓到的就是经过浏览器渲染后的页面:
library(rvest)
webpage <- read_html(remDr$getPageSource()[[1]][1])
参考链接:R语言爬取动态网页:使用RSelenium包和Rwebdriver包的前期准备
R语言爬取动态网页之环境准备的更多相关文章
- 爬虫(三)通过Selenium + Headless Chrome爬取动态网页
一.Selenium Selenium是一个用于Web应用程序测试的工具,它可以在各种浏览器中运行,包括Chrome,Safari,Firefox 等主流界面式浏览器. 我们可以直接用pip inst ...
- 记录几个爬取动态网页时的问题(下拉框,旧的元素无法获取,获取的源代码和f12看到的不一致,爬取延迟)
更新.....这个动态网页其实直接抓取ajax请求就可以了,很简单,我之前想复杂了,虽然也实现了,但是效率极低,不过没关系,就当作是对Selenium的一次学习吧 1.最近在爬取一个动态网页,其中为了 ...
- python爬取动态网页数据,详解
原理:动态网页,即用js代码实现动态加载数据,就是可以根据用户的行为,自动访问服务器请求数据,重点就是:请求数据,那么怎么用python获取这个数据了? 浏览器请求数据方式:浏览器向服务器的api(例 ...
- 利用selenium并使用gevent爬取动态网页数据
首先要下载相应的库 gevent协程库:pip install gevent selenium模拟浏览器访问库:pip install selenium selenium库相应驱动配置 https: ...
- R语言爬虫:使用R语言爬取豆瓣电影数据
豆瓣排名前25电影及评价爬取 url <-'http://movie.douban.com/top250?format=text' # 获取网页原代码,以行的形式存放在web 变量中 web & ...
- 爬取动态网页:Selenium
参考:http://blog.csdn.net/wgyscsf/article/details/53454910 概述 在爬虫过程中,一般情况下都是直接解析html源码进行分析解析即可.但是,有一种情 ...
- python爬取动态网页2,从JavaScript文件读取内容
import requests import json head = {"user-agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) ...
- 写论文,没数据?R语言抓取网页大数据
写论文,没数据?R语言抓取网页大数据 纵观国内外,大数据的市场发展迅猛,政府的扶持也达到了空前的力度,甚至将大数据纳入发展战略.如此形势为社会各界提供了很多机遇和挑战,而我们作为卫生(医学)统计领域的 ...
- Python+Selenium爬取动态加载页面(2)
注: 上一篇<Python+Selenium爬取动态加载页面(1)>讲了基本地如何获取动态页面的数据,这里再讲一个稍微复杂一点的数据获取全国水雨情网.数据的获取过程跟人手动获取过程类似,所 ...
随机推荐
- MySQL 的索引是什么?怎么优化?
索引类似大学图书馆建书目索引,可以提高数据检索的效率,降低数据库的IO成本.MySQL在300万条记录左右性能开始逐渐下降,虽然官方文档说500~800w记录,所以大数据量建立索引是非常有必要的.My ...
- Docker简易使用手册
1. Docker介绍 Docker中文社区文档 Docker 是一个开源的软件部署解决方案. Docker 包括三个基本概念: 镜像(Image) Docker的镜像概念类似于虚拟机里的镜像,是一个 ...
- CSS media queries 媒体查询
最近在做一些页面打印时的特殊处理接触到了media queries,想系统学习一下,在MOZILLA DEVELOPER NETWORK看到一篇文章讲的很不错,结合自己的使用总结一下. CSS2/me ...
- exits 和no exits
exists : 强调的是是否返回结果集,不要求知道返回什么, 比如: select name from student where sex = 'm' and mark exists(select ...
- Js 将图片的绝对路径转换为base64编码
转.... 我们可以使用canvas.toDataURL的方法将图片的绝对路径转换为base64编码:在这我们引用的是淘宝首页一张图片如下: var img = "https://img. ...
- 安装MySQL数据库并开启远程访问
一.安装MySQL数据库 MySQL安装在系统盘下(C:\Program Files),方便系统备份. 1.双击安装程序,勾选“I accept the license terms”,点击“Next” ...
- Java入门指南-01 基本概要说明
一.Java语言概述 Java是一门面向对象编程语言.编程,即编写程序.程序对于我们来说,应该是有所了解的.只是有可能你们不知道而已.比如,我们电脑上的 QQ.谷歌浏览器等,都叫做应用程序. 二.本系 ...
- Vivado添加sublime text编辑器
我们当用vivado会发现文本编辑器有点鸡肋,没有自动的缩进的功能,所以我想用sublime来进行文本的编辑,下面就是绑定的一些方法(但是呢其实吧,虽然可以绑定却不能实时的报错,,,我感觉我还是老老实 ...
- Vue自行封装常用组件-文本提示
使用方法:1.在父组件中引入"toast.vue" //import toast from "./toast"; 2.在父组件中注册 toast //compo ...
- 牛客小白月赛12 J 月月查华华的手机 (序列自动机模板题)
链接:https://ac.nowcoder.com/acm/contest/392/J 来源:牛客网 题目描述 月月和华华一起去吃饭了.期间华华有事出去了一会儿,没有带手机.月月出于人类最单纯的好奇 ...