SpringBoot进阶教程(七十四)整合ELK
在上一篇文章《SpringBoot进阶教程(七十三)整合elasticsearch 》,已经详细介绍了关于elasticsearch的安装与使用,现在主要来看看关于ELK的定义、安装及使用。
v简介
1.什么是ELK?
ELK 是elastic公司提供的一套完整的日志收集以及展示的解决方案,是三个产品的首字母缩写,分别是ElasticSearch、Logstash 和 Kibana。
ElasticSearch:ElasticSearch简称ES,它是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。它是一个建立在全文搜索引擎Apache Lucene基础上的搜索引擎,使用Java语言编写。关于ES的更多介绍,可以看看《SpringBoot进阶教程(七十三)整合elasticsearch 》
Logstash:Logstash是一个具有实时传输能力的数据收集引擎,用来进行数据收集(如:读取文本文件)、解析,并将数据发送给ES。
Kibana:Kibana为Elasticsearch提供了分析和可视化的Web平台。它可以在Elasticsearch的索引中查找,交互数据,并生成各种维度表格、图形。
2.ELK的用途
2.1问题排查:我们常说,运维和开发这一辈子无非就是和问题在战斗,所以这个说起来很朴实的四个字,其实是沉甸甸的。很多公司其实不缺钱,就要稳定,而要稳定,就要运维和开发能够快速的定位问题,甚至防微杜渐,把问题杀死在摇篮里。日志分析技术显然问题排查的基石。基于日志做问题排查,还有一个很帅的技术,叫全链路追踪,比如阿里的eagleeye 或者Google的dapper,也算是日志分析技术里的一种。
2.2监控和预警:日志,监控,预警是相辅相成的。基于日志的监控,预警使得运维有自己的机械战队,大大节省人力以及延长运维的寿命。
2.3关联事件:多个数据源产生的日志进行联动分析,通过某种分析算法,就能够解决生活中各个问题。比如金融里的风险欺诈等。这个可以可以应用到无数领域了,取决于你的想象力。
2.4数据分析:这个对于数据分析师,还有算法工程师都是有所裨益的。
vdocker安装elk
1. 拉取镜像
docker pull elasticsearch:7.5.1
docker pull logstash:7.5.1
docker pull kibana:7.5.1
注意各个版本尽量保持一致,否则可能会报错。
2. 创建docker-compose.yml
因为elk涉及到多个镜像,所以使用docker-compose的方式,会比较方便。如果还没有安装docker-compose的,可以看看这篇文章。
创建目录: mkdir /usr/local/docker/elk
创建docker-compose.yml文件 vi docker-compose.yml
version: '3'
services:
elasticsearch:
image: elasticsearch:7.5.1
container_name: elasticsearch
environment:
- "cluster.name=elasticsearch" #设置集群名称为elasticsearch
- "discovery.type=single-node" #以单一节点模式启动
- "ES_JAVA_OPTS=-Xms512m -Xmx512m" #设置使用jvm内存大小
volumes:
- /usr/local/docker/elk/elasticsearch/plugins:/usr/share/elasticsearch/plugins #插件文件挂载
- /usr/local/docker/elk/elasticsearch/data:/usr/share/elasticsearch/data #数据文件挂载
ports:
- 9200:9200
kibana:
image: kibana:7.5.1
container_name: kibana
depends_on:
- elasticsearch #kibana在elasticsearch启动之后再启动
environment:
- ELASTICSEARCH_URL=http://elasticsearch:9200 #设置访问elasticsearch的地址
ports:
- 5601:5601
logstash:
image: logstash:7.5.1
container_name: logstash
volumes:
- /usr/local/docker/elk/logstash/logstash-springboot.conf:/usr/share/logstash/pipeline/logstash.conf #挂载logstash的配置文件
depends_on:
- elasticsearch #kibana在elasticsearch启动之后再启动
links:
- elasticsearch:es #可以用es这个域名访问elasticsearch服务
ports:
- 4560:4560
!wd保存。
3. 创建logstash-springboot.conf
创建 logstash目录 mkdir /usr/local/docker/elk/logstash
cd logstash 进入logstash 目录
创建logstash-springboot.conf配置文件 vi logstash-springboot.conf
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 4560
codec => json_lines
}
}
output {
elasticsearch {
hosts => "es:9200"
index => "springboot-logstash-%{+YYYY.MM.dd}"
}
}
cd .. 返回上一级目录,即回到docker-compose所在的目录( /usr/local/docker/elk )。
4. 启动ELK
docker-compose up -d
访问Kibana(访问地址:http://ip:5601),会看到异常信息 Cannot connect to the Elasticsearch cluster currently configured for Kibana. 再通过 docker ps -a 发现elasticsearch实例挂了。
通过 docker logs -f elasticsearch 可以看到,es容器里的/usr/share/elasticsearch/data/nodes文件夹目录没有读写权限,实际上是没有宿主机/usr/local/es/data的读写权限。
chmod 777 /usr/local/docker/elk/elasticsearch/data
然后重启一下 docker-compose restart
请求url http://toutou.com:5601 ,搞定。
注意:如果启动ELK之后马上请求url,会提示 Kibana server is not ready yet ,等一会就好了。因为ELK三个应用之间创建连接也需要一点时间。
vspringboot整合elk
1. 添加引用
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>5.2</version>
</dependency>
2. 添加logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<include resource="org/springframework/boot/logging/logback/console-appender.xml"/>
<!--应用名称-->
<property name="APP_NAME" value="myshop-demo-elk"/>
<!--日志文件保存路径-->
<property name="LOG_FILE_PATH" value="${LOG_FILE:-${LOG_PATH:-${LOG_TEMP:-${java.io.tmpdir:-/tmp}}}/logs}"/>
<contextName>${APP_NAME}</contextName>
<!--每天记录日志到文件appender-->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE_PATH}/${APP_NAME}-%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
<encoder>
<pattern>${FILE_LOG_PATTERN}</pattern>
</encoder>
</appender>
<!--输出到logstash的appender-->
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<!--可以访问的logstash日志收集端口-->
<destination>toutou.com:4560</destination>
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="FILE"/>
<appender-ref ref="LOGSTASH"/>
</root>
</configuration>
注意:appender节点下的destination需要改成自己的logstash服务地址,比如我的是:toutou.com:4560
如果logback.xml不知道怎么配的话,可以看看这篇文章:SpringBoot入门教程(八)配置logback日志
3. 添加测试Controller
/**
* @author toutou
* @date by 2021/2
* @des https://www.cnblogs.com/toutou
*/
@Slf4j
@RestController
public class IndexController {
@GetMapping("/elk")
public Result index() {
String message = "logback ELK成功接入了,时间:" + new Date();
log.info(message);
return Result.setSuccessResult(message);
}
}
关于springboot的整合就可以了,然后启动SpringBoot应用就行。
v配置kibana
请求url http://toutou.com:5601 ,点击Explore on my own。
1. 创建索引
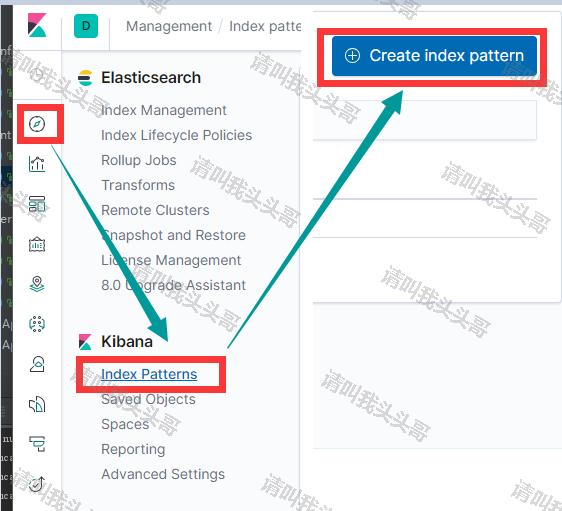

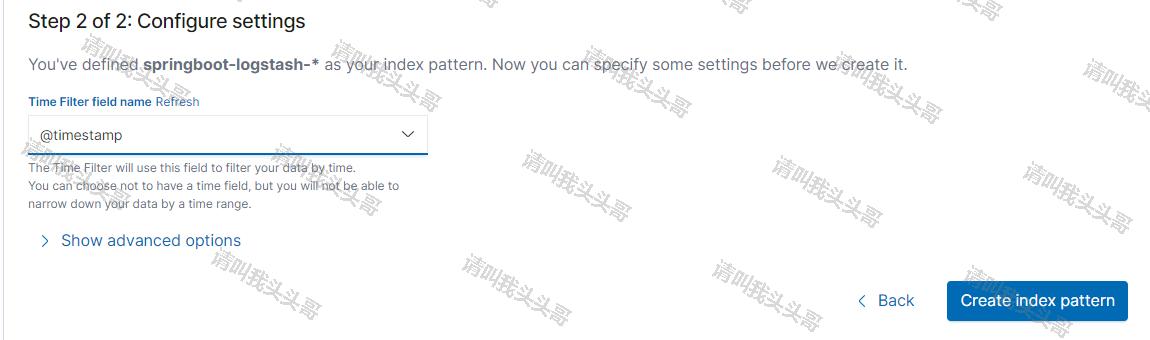
依次按上图中的步骤创建索引。
2. 查看收集日志


3. 添加过滤条件,查找符合条件的日志
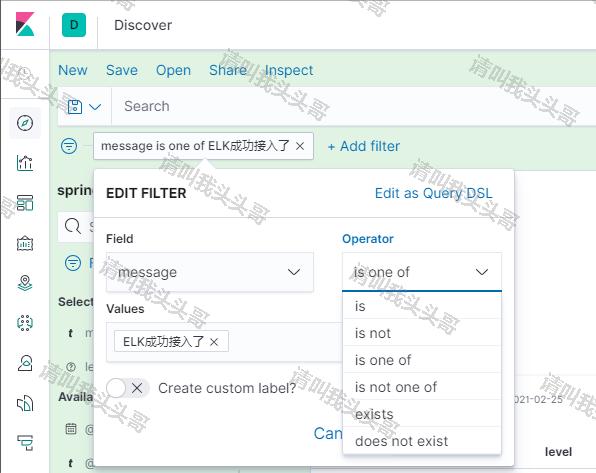
4. 添加过滤条件
通过日志查询,我们会发现有很多debug的无效日志,这种日志可能不是太需要,而且会影响我们查询真正有用的日志。这样我们就可以在收集日志的时候,修改logstash-springboot.conf配置,通过logstash-springboot.conf来移除debug级别的日志。更新后的配置如下:
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 4560
codec => json_lines
}
}
output {
if [level] != "ERROR" {
elasticsearch {
hosts => "es:9200"
index => "springboot-logstash-%{+YYYY.MM.dd}"
}
}
}
vkibana汉化
1. 进入kibana容器
docker exec -it kibana /bin/bash
2. 编辑文件
vi /opt/kibana/config/kibana.yml
修改该文件 在文件最后加上一行配置
i18n.locale: zh-CN
注意:zhe-CN和:号之间必须有个空格,否则kibana无法启动
重启,即可看到访问的 kibana已汉化。

v源码地址
https://github.com/toutouge/javademosecond/tree/master/hellolearn
作 者:请叫我头头哥
出 处:http://www.cnblogs.com/toutou/
关于作者:专注于基础平台的项目开发。如有问题或建议,请多多赐教!
版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。
特此声明:所有评论和私信都会在第一时间回复。也欢迎园子的大大们指正错误,共同进步。或者直接私信我
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是作者坚持原创和持续写作的最大动力!
<script type="text/javascript">// </script>
#comment_body_3242240 { display: none }
SpringBoot进阶教程(七十四)整合ELK的更多相关文章
- SpringBoot进阶教程(二十四)整合Redis
缓存现在几乎是所有中大型网站都在用的必杀技,合理的利用缓存不仅能够提升网站访问速度,还能大大降低数据库的压力.Redis提供了键过期功能,也提供了灵活的键淘汰策略,所以,现在Redis用在缓存的场合非 ...
- SpringBoot进阶教程(五十九)整合Codis
上一篇博文<详解Codis安装与部署>中,详细介绍了codis的安装与部署,这篇文章主要介绍介绍springboot整合codis.如果之前看过<SpringBoot进阶教程(五十二 ...
- SpringBoot进阶教程(六十四)注解大全
在Spring1.x时代,还没出现注解,需要大量xml配置文件并在内部编写大量bean标签.Java5推出新特性annotation,为spring的更新奠定了基础.从Spring 2.X开始spri ...
- SpringBoot进阶教程(二十九)整合Redis 发布订阅
SUBSCRIBE, UNSUBSCRIBE 和 PUBLISH 实现了 发布/订阅消息范例,发送者 (publishers) 不用编程就可以向特定的接受者发送消息 (subscribers). Ra ...
- SpringBoot进阶教程(二十八)整合Redis事物
Redis默认情况下,事务支持被禁用,必须通过设置setEnableTransactionSupport(true)为使用中的每个redistplate显式启用.这样做会强制将当前重新连接绑定到触发m ...
- SpringBoot进阶教程(二十六)整合Redis之共享Session
集群现在越来越常见,当我们项目搭建了集群,就会产生session共享问题.因为session是保存在服务器上面的.那么解决这一问题,大致有三个方案,1.通过nginx的负载均衡其中一种ip绑定来实现( ...
- SpringBoot进阶教程(二十五)整合Redis之@Cacheable、@CachePut、@CacheEvict的应用
在上一篇文章(<SpringBoot(二十四)整合Redis>)中,已经实现了Spring Boot对Redis的整合,既然已经讲到Cache了,今天就介绍介绍缓存注解.各家互联网产品现在 ...
- SpringBoot进阶教程(七十)SkyWalking
流行的APM(Application Performance Management工具有很多,比如Cat.Zipkin.Pinpoint.SkyWalking.优秀的监控工具还有很多,其它比如还有za ...
- SpringBoot进阶教程(六十二)整合Kafka
在上一篇文章<Linux安装Kafka>中,已经介绍了如何在Linux安装Kafka,以及Kafka的启动/关闭和创建发话题并产生消息和消费消息.这篇文章就介绍介绍SpringBoot整合 ...
随机推荐
- Nuxt.js的踩坑指南(常见问题汇总)
本文会不定期更新在nuxt.js中遇到的问题进行汇总.转发请注明出处,尊重作者,谢谢! 强烈推荐作者文档版踩坑指南,点击跳转踩坑指南 在Nuxt的官方文档中,中文文档和英文文档都存在着不小的差异. 1 ...
- 什么是CSS Modules ?我们为什么需要他们
原文地址:https://css-tricks.com/css-mo...最近我对CSS Modules比较好奇.如果你曾经听说过他们,那么这篇博客正适合你.我们将去探索它的目的和主旨.如果你同样很好 ...
- Ueditor上传本地音频MP3
遇到一个项目,客户要求能在编辑框中上传录音文件.用的是Ueditor编辑器,但是却不支持本地MP3上传并使用audio标签播放,只能搜索在线MP3,实在有点不方便.这里说一下怎么修改,主要还是利用原来 ...
- 深入解析丨母婴App如何迅速收割2W新用户?
在讲案例前,我们需要先说一下精细化分析. 我们常说的精细化分析,就是一个持续"解构"的过程,通过像漏斗.留存.细分等高级分析功能,将"整体"按照事件属性解构成& ...
- XUtils 开发框架
xUtils简介 xUtils 包含了很多实用的android工具. xUtils 最初源于Afinal框架,进行了大量重构,使得xUtils支持大文件上传,更全面的http请求协议支持(10种谓词) ...
- 大数据学习之路之ambari的安装
之前按照正常方式安装的hbase不能插入数据 所以今天来尝试下ambari能不能行 已经打了快照 如果不能还能恢复之前的样子
- java中输出一个字符串里面的空格,字母还有数字的数目举例说明
9.6 About string,"I am a teacher",这个字符串中有多少个字,且分别把每个字打印出来. /*本题的思路就是,当我有一个字符串,我需要一个一个字符的处理 ...
- Redis分布式实现原理
一.使用 1.pom.xml导入依赖 <dependency> <groupId>org.springframework.boot</groupId> <ar ...
- 使用pyttsx3实现简单tts服务
操作系统:Windows 10_x64 python版本:Python 3.9.2_x64 pyttsx3版本: 2.90 pyttsx3是一个tts引擎包装器,可对接SAPI5.NSSS(NSS ...
- Python入门-正则表达式
正则匹配函数 # 需要先导入re模块 import re #字符串,匹配查找 info = "www baidu com" print("=======字符串自带find ...