HDFS基础入门
HDFS简介
HDFS(全称:Hadoop Distribute File System)分布式文件系统,是Hadoop核心组成。
HDFS中的重要概念
分块存储
HDFS中的文件在物理上是分块存储的,块的大小可以通过配置参数来规定;Hadoop2.x版本默认的block大小是128M
命名空间
HDFS支持传统的层次性文件组织结构。用户或者应用程序可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名这些文件。
NameNode负责维护文件系统的名字空间,任何对文件系统名字空间或属性的修改都被NameNode记录下来。
NameNode元数据
我们把目录结构及文件分块位置信息叫做元数据。NameNode的元数据记录每一个文件对应的block信息。
DataNode数据存储
文件的各个block的具体存储管理由DataNode负责。一个block会有多个DataNode来存储,DataNode会定时向NameNode来汇报自己持有的block信息。
副本机制
为了容错,文件的所有block都会有副本。每隔文件的block大小和副本数都是可配置的。副本数默认是3个。
一次写入,多次读出
HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的随机修改。正因为如此,HDFS适合用来做大数据分析的底层存储服务,而不适合做网盘等应用。(修改不方便,延迟大)
HDFS架构
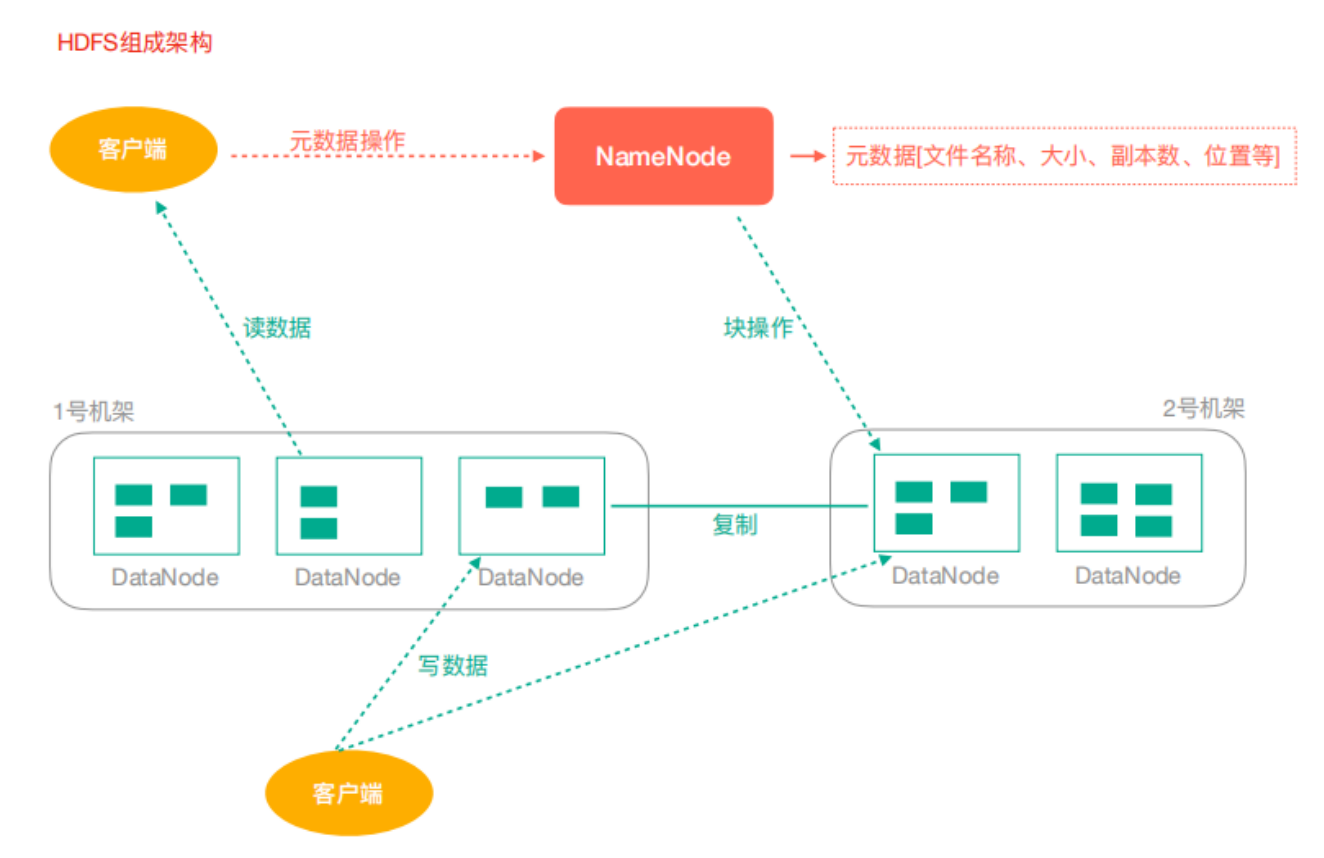
NameNode:Hdfs集群的管理者
- 维护管理Hdfs的名称空间
- 维护副本策略
- 记录文件块的映射关系
- 负责处理客户端读写请求
DataNode:NameNode下达命令,DataNode执行实际操作
- 保存实际的数据块
- 负责数据块的读写
Client:客户端
- 上传文件到HDFS的时候,Client负责将文件切分成Block,然后进行上传
- 请求NameNode交互,获取文件的位置信息
- 读取或写入文件,与DataNode交互
- Client可以使用一些命令来管理HDFS或者访问HDFS
写数据流程:
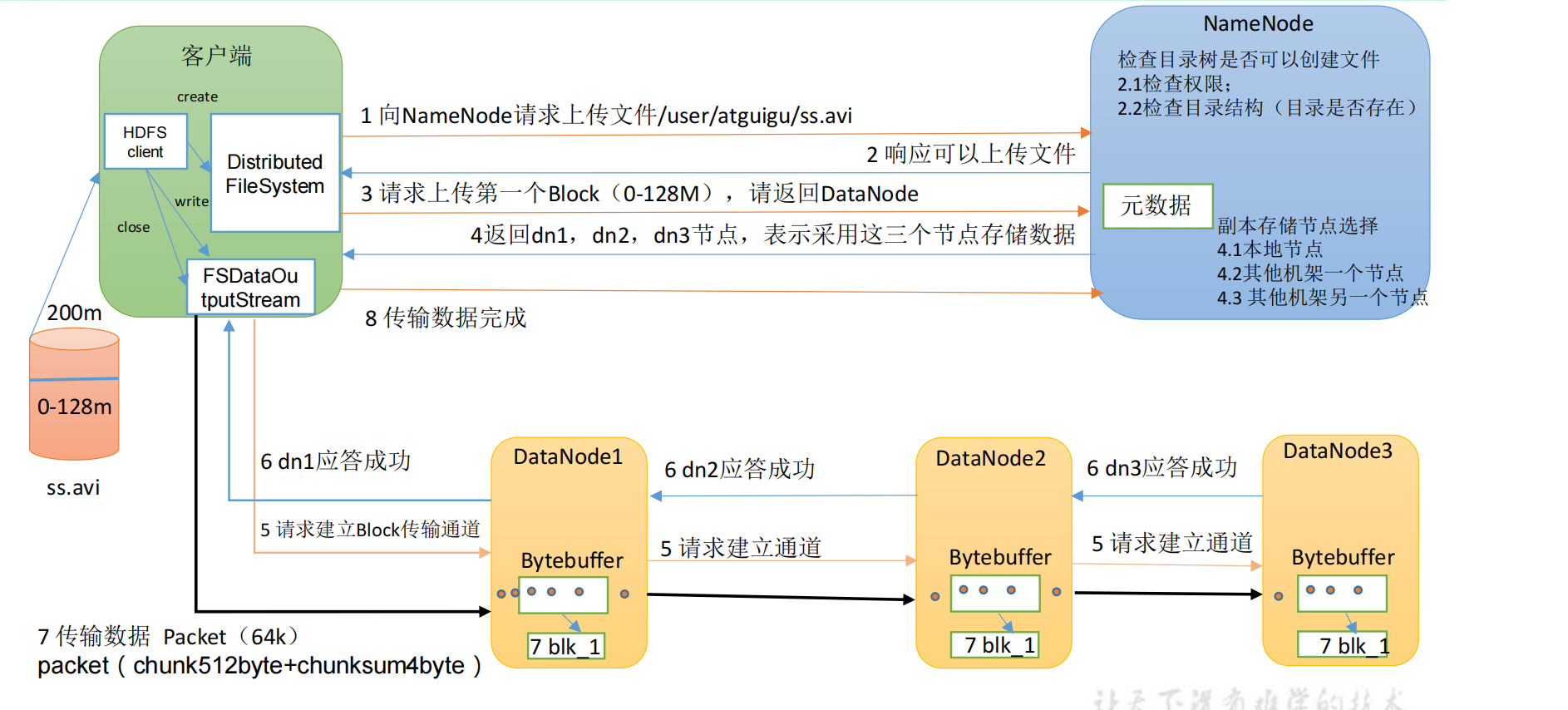
HDFS客户端操作
Shell客户端
- 查看所有命令
hadoop fs
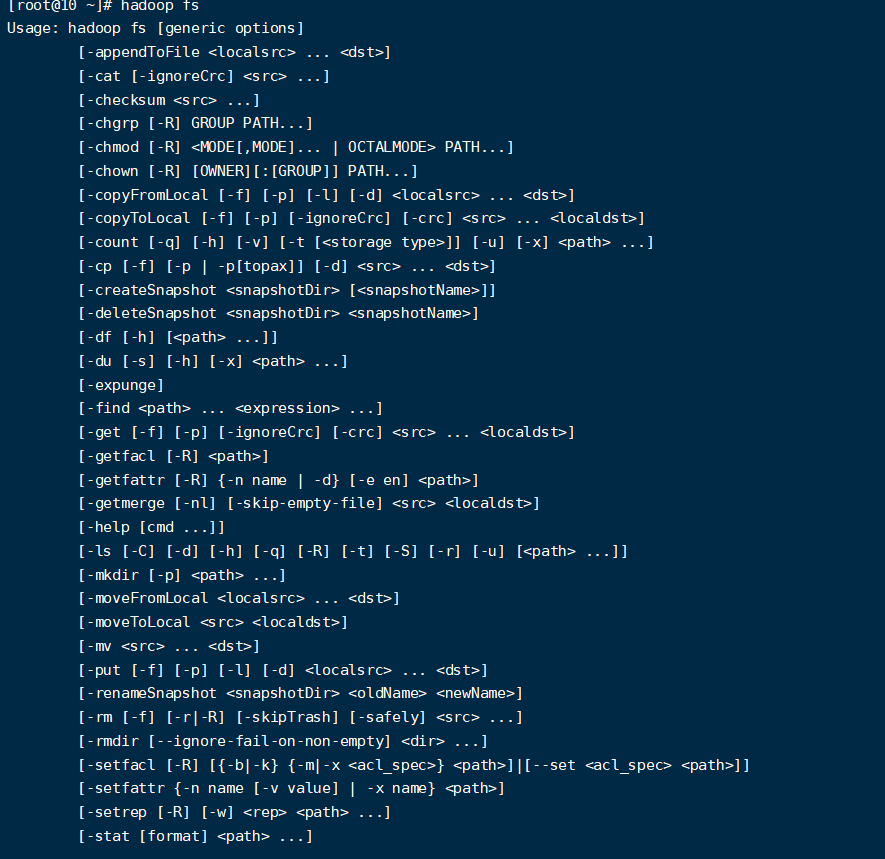
- 查看命令帮助
#查看rm的帮助信息
hadoop fs -help rm
- 显示目录信息
hadoop fs -ls /
- 创建目录
hadoop fs -mkdir -p /test/data
- 从本地剪切到HDFS
hadoop fs -moveFromLocal ./word.txt /test/data
- 追加文件内容到指定文件
hadoop fs -appendToFile test.txt /test/data/word.txt
- 显示文件内容
hadoop fs -cat /test/data/word.txt
- 修改文件所属权限
hadoop fs -chmod 666 /test/data/word.txt
hadoop fs -chown root:root /test/data/word.txt
- 从本地文件系统拷贝文件到HDFS路径去
hadoop fs -copyFromLocal test.txt /test
- 从HDFS拷贝到本地
hadoop fs -copyToLocal /test/data/word.txt /opt
- 从HDFS的一个路径拷贝到HDFS的另一个路径
hadoop fs -cp /test/data/word.txt /test/input/t.txt
- 在HDFS目录中移动文件
hadoop fs -mv /test/input/t.txt /
- 从HDFS中下载文件,等同于copyToLocal
hadoop fs -get /t.txt ./
- 从本地上传文件到HDFS,等同于copyFromLocal
hadoop fs -put ./yarn.txt /user/root/test/
- 显示一个文件的末尾
hadoop fs -tail /t.txt
- 删除文件或文件夹
hadoop fs -rm /t.txt
- 删除空目录
hadoop fs -rmdir /test
- 统计文件夹的大小信息
hadoop fs -du -s -h /test
hadoop fs -du -h /test

- 设置HDFS的副本数量
hadoop fs -setrep 10 /lagou/bigdata/hadoop.txt
注意:这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10.
Java客户端
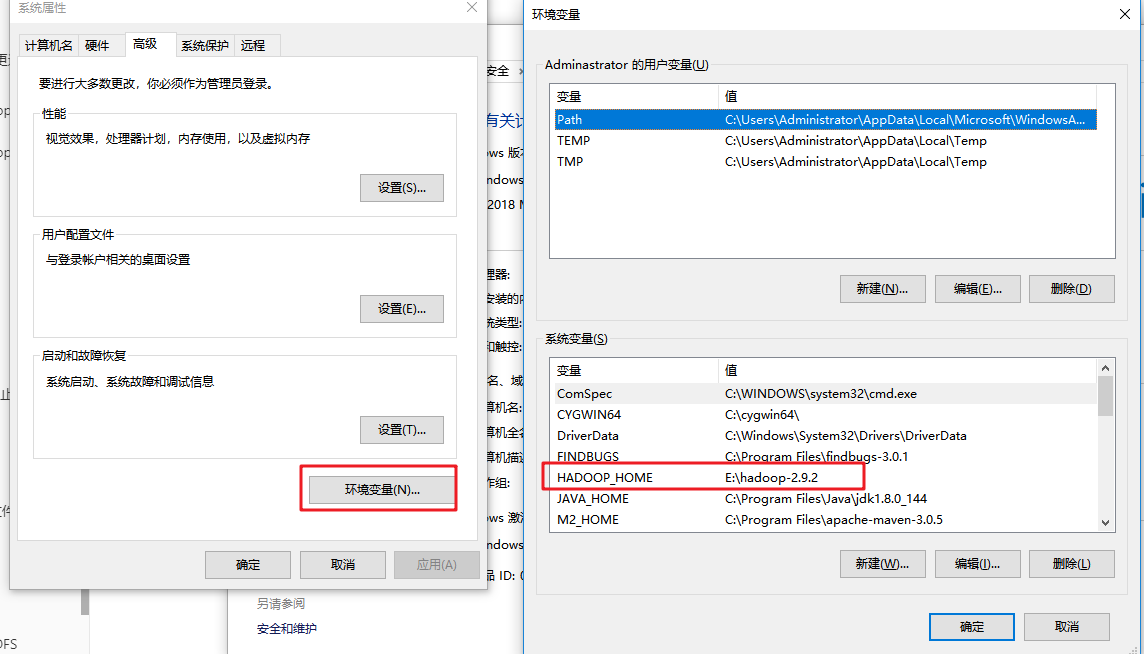
环境准备
- 将Hadoop安装包解压到非中文路径
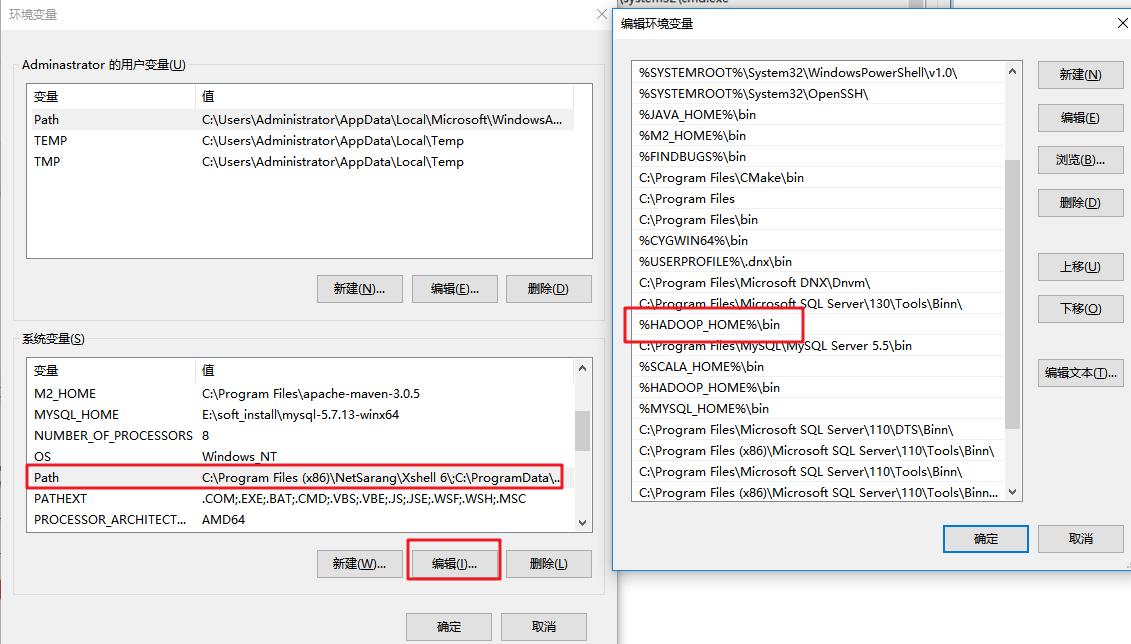
- 配置环境变量
- 依赖导入
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop-version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop-version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop-version}</version>
</dependency>
- 配置文件(可选步骤)
将hdfs-site.xml(内容如下)拷贝到项目的resources下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
参数优先级排序:(1)代码中设置的值 >(2)用户自定义配置文件 >(3)服务器的默认配置
HDFS Java API
- 上传文件
@Test
public void testCopyFromLocalFile() throws Exception{
Configuration conf = new Configuration();
FileSystem fs=FileSystem.get(new URI("hdfs://192.168.56.103:9000"),conf,"root");
fs.copyFromLocalFile(new Path("e://aa.txt"),new Path("/cc.txt"));
fs.close();
}
为了方便,下面的示例就隐藏构建FileSystem的过程
- 下载文件
@Test
public void testCopyToLocalFile() throws Exception{
fs.copyToLocalFile(false,new Path("/aa.txt"),new Path("e://cd.txt"),true);
}
- 删除文件
@Test
public void testDelete() throws Exception{
fs.delete(new Path("/aa.txt"),true);
}
- 查看文件名称、权限、长度、块信息等
public void testList() throws IOException {
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while (listFiles.hasNext()){
LocatedFileStatus status = listFiles.next();
//文件名称
System.out.println(status.getPath().getName());
System.out.println(status.getLen());
System.out.println(status.getPermission());
System.out.println(status.getGroup());
BlockLocation[] blockLocations = status.getBlockLocations();
Stream.of(blockLocations).forEach(
block->{
String[] hosts = new String[0];
try {
hosts = block.getHosts();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println(Arrays.asList(hosts));
}
);
System.out.println("-----------华丽的分割线----------");
}
}
- 文件夹判断
@Test
public void testListStatus() throws IOException {
FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
Stream.of(fileStatuses).forEach(fileStatus -> {
String name = fileStatus.isFile() ? "文件:" + fileStatus.getPath().getName() : "文件夹:"+fileStatus.getPath().getName();
System.out.println(name);
});
}
- 通过I/O流操作HDFS
- IO流上传文件
@Test
public void testIOUpload() throws IOException {
FileInputStream fis = new FileInputStream(new File("e://11.txt"));
FSDataOutputStream fos = fs.create(new Path("/io_upload.txt"));
IOUtils.copyBytes(fis,fos,new Configuration());
IOUtils.closeStream(fis);
IOUtils.closeStream(fos);
}
- IO流下载文件
@Test
public void testDownload() throws IOException{
FSDataInputStream fis = fs.open(new Path("/io_upload.txt"));
FileOutputStream fos = new FileOutputStream(new File("e://11_copy.txt"));
IOUtils.copyBytes(fis,fos,new Configuration());
IOUtils.closeStream(fis);
IOUtils.closeStream(fos);
}
- seek定位读取
@Test
public void readFileSeek() throws IOException{
FSDataInputStream fis = fs.open(new Path("/io_upload.txt"));
IOUtils.copyBytes(fis,System.out,1024,false);
//从头再次读取
fis.seek(0);
IOUtils.copyBytes(fis,System.out,1024,false);
IOUtils.closeStream(fis);
}
HDFS文件权限问题
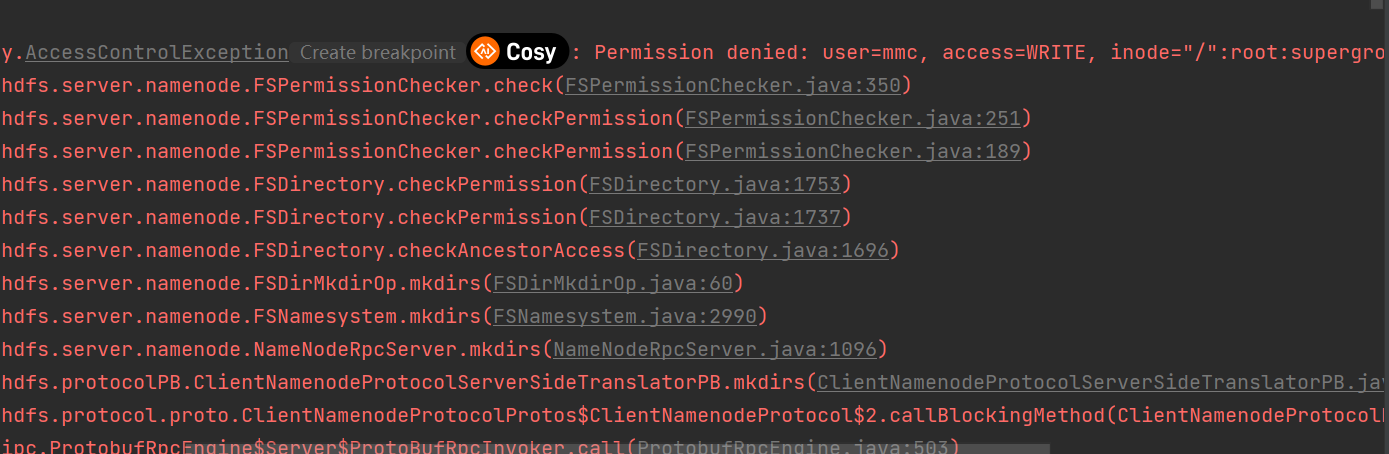
HDFS的文件权限和linux系统的文件权限机制类似。如果在linux系统中root用户使用hadoop命令创建了一个文件,那么该文件的owner就是root。
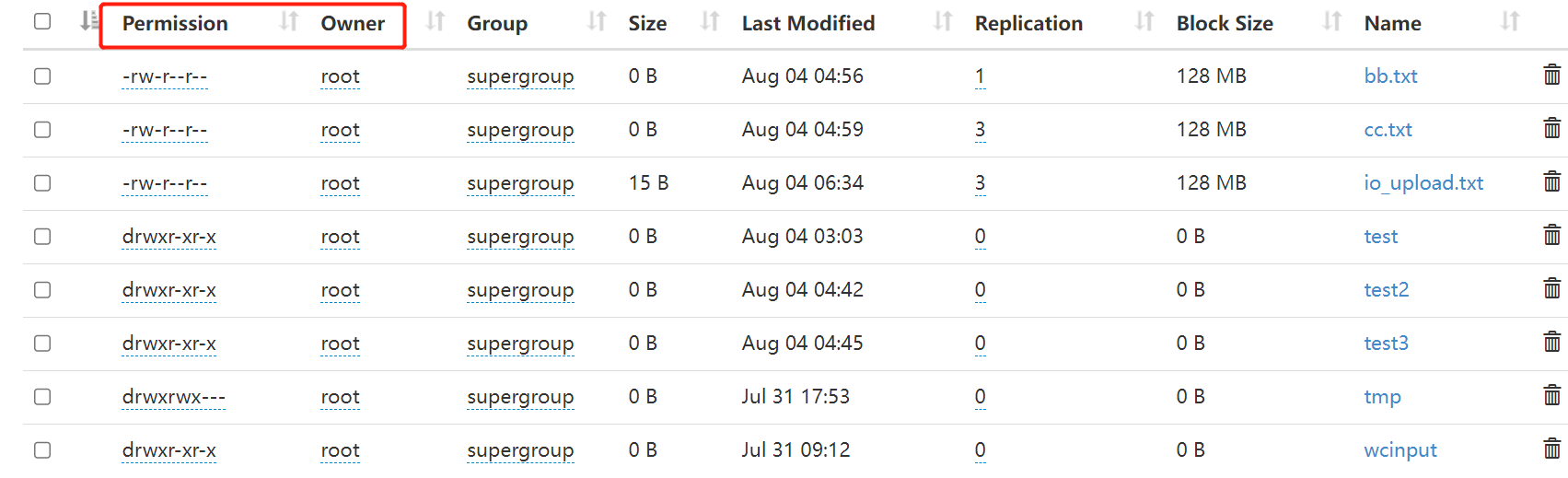
当出现权限问题时,解决方法有如下几种:
- 获取FileSystem对象时指定有权限的用户
- 关闭HDFS权限校验,修改hdfs-site.xml
#添加如下属性
<property>
<name>dfs.permissions</name>
<value>true</value>
</property>
- 直接修改HDFS的文件或目录权限为777,允许所有用户操作
hadoop fs -chmod -R 777 /
HDFS基础入门的更多相关文章
- Hadoop学习笔记—2.不怕故障的海量存储:HDFS基础入门
一.HDFS出现的背景 随着社会的进步,需要处理数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是却不方便管理和维护—>因此,迫切需要一种系统来管理多 ...
- 每天收获一点点------Hadoop之HDFS基础入门
一.HDFS出现的背景 随着社会的进步,需要处理数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是却不方便管理和维护—>因此,迫切需要一种系统来管理多 ...
- 【原创 Hadoop&Spark 动手实践 5】Spark 基础入门,集群搭建以及Spark Shell
Spark 基础入门,集群搭建以及Spark Shell 主要借助Spark基础的PPT,再加上实际的动手操作来加强概念的理解和实践. Spark 安装部署 理论已经了解的差不多了,接下来是实际动手实 ...
- js学习笔记:webpack基础入门(一)
之前听说过webpack,今天想正式的接触一下,先跟着webpack的官方用户指南走: 在这里有: 如何安装webpack 如何使用webpack 如何使用loader 如何使用webpack的开发者 ...
- 「译」JUnit 5 系列:基础入门
原文地址:http://blog.codefx.org/libraries/junit-5-basics/ 原文日期:25, Feb, 2016 译文首发:Linesh 的博客:JUnit 5 系列: ...
- .NET正则表达式基础入门
这是我第一次写的博客,个人觉得十分不容易.以前看别人写的博客文字十分流畅,到自己来写却发现十分困难,还是感谢那些为技术而奉献自己力量的人吧. 本教程编写之前,博主阅读了<正则指引>这本入门 ...
- 从零3D基础入门XNA 4.0(2)——模型和BasicEffect
[题外话] 上一篇文章介绍了3D开发基础与XNA开发程序的整体结构,以及使用Model类的Draw方法将模型绘制到屏幕上.本文接着上一篇文章继续,介绍XNA中模型的结构.BasicEffect的使用以 ...
- 从零3D基础入门XNA 4.0(1)——3D开发基础
[题外话] 最近要做一个3D动画演示的程序,由于比较熟悉C#语言,再加上XNA对模型的支持比较好,故选择了XNA平台.不过从网上找到很多XNA的入门文章,发现大都需要一些3D基础,而我之前并没有接触过 ...
- Shell编程菜鸟基础入门笔记
Shell编程基础入门 1.shell格式:例 shell脚本开发习惯 1.指定解释器 #!/bin/bash 2.脚本开头加版权等信息如:#DATE:时间,#author(作者)#mail: ...
随机推荐
- 好客租房16-jsx中的列表渲染
如果要渲染一组数组 应该使用数组的map方法 注意:渲染列表时候添加key属性 key属性的值要保持唯一 原则:map()遍历谁 就给谁添加key属性 尽量避免索引号作为key //导入react i ...
- 好客租房11-为什么脚手架使用jsx语法
为什么脚手架中可以使用jsx语法 1jsx不是标准的ECMAScript ,他是ECMAScript的语法扩展 2需要使用babel编译处理后 才能在浏览器环境中使用 3create-react-ap ...
- 用 notion 管理信用卡与花呗
用 notion 管理信用卡与花呗 Notion原文,排版更佳 概述 不需要提醒功能和安卓用户可以忽略Scriptable和快捷指令 app的设置 Notion 建立信用卡表格,录入信用卡基本信息,自 ...
- 开源LIMS系统miso LIMS(适用于NGS基因测序)
开源地址 https://github.com/miso-lims/miso-lims github加速可使用:https://kfqbvpat.fast-github.tk/-----https:/ ...
- 给IDEA道个歉,这不是它的BUG,而是反编译插件的BUG。
你好呀,我是歪歪. 上周我不是发了<我怀疑这是IDEA的BUG,但是我翻遍全网没找到证据!>这篇文章吗. 主要描述了在 IDEA 里面反编译后的 class 文件中有这样的代码片段: 很明 ...
- 关于『进击的Markdown』:第二弹
关于『进击的Markdown』:第二弹 建议缩放90%食用 众里寻他千百度,蓦然回首,Markdown却在灯火灿烂处 MarkdownYYDS! 各位早上好! 我果然鸽稿了 Markdown 语法 ...
- 名校AI课推荐 | UC Berkeley《人工智能导论》
深度学习具备强感知能力但缺乏一定的决策能力,强化学习具备决策能力但对感知问题束手无策,因此将两者结合起来可以达到优势互补的效果,为复杂系统的感知决策问题提供了解决思路. 今天我们推荐这样一门课程--U ...
- 记一次grpc server内存/吞吐量优化
背景 最近,上线的采集器忽然时有OOM.采集器本质上是一个grpc服务,网络设备通过grpc协议将数据上报后,采集器进行格式等整理后,发往下一个系统(比如分析,存储). 打开运行环境,发现特性如下: ...
- Stream常用操作以及原理探索
Stream常用操作以及原理 Stream是什么? Stream是一个高级迭代器,它不是数据结构,不能存储数据.它可以用来实现内部迭代,内部迭代相比平常的外部迭代,它可以实现并行求值(高效,外部迭代要 ...
- Linux基础命令、引号和括号的作用
查看硬件信息 查看 cpu lscpu命令可以查看cpu信息 cat /proc/cpuinfo也可看查看到 查看内存大小 free命令 cat /proc/meminfo 查看硬盘和分区 lsblk ...