Python爬虫之Scrapy框架爬虫实战
Python爬虫中Scrapy框架应用非常广泛,经常被人用于属于挖掘、检测以及自动化测试类项目,为啥说Scrapy框架作为半成品我们又该如何利用好呢 ?下面的实战案例值得大家看看。
目录:
1、Scrapy框架之命令行
2、项目实现
Scrapy框架之命令行
Scrapy是为持续运行设计的专业爬虫框架,提供操作的Scrapy命令行。
Scrapy爬虫的常用命令:
scrapy<command>[option][args]#command为Scrapy命令
常用命令:(图1)
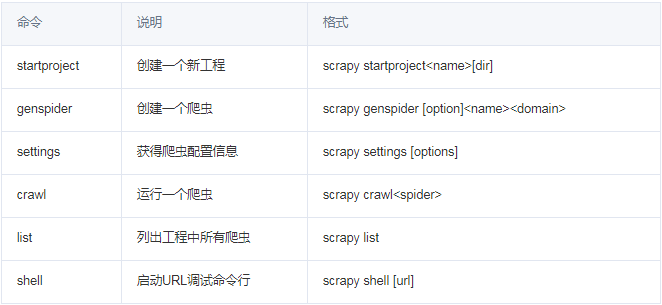
至于为什么要用命令行,主要是我们用命令行更方便操作,也适合自动化和脚本控制。至于用Scrapy框架,一般也是较大型的项目,程序员对于命令行也更容易上手。
首先介绍一下相关文件的作用,方便我们到时候修改相关代码。
scrapy.cfg:部署Scrapy爬虫的配置文件
demo:Scrapy框架的用户自定义Python代码
其中,在项目文件根目录里面的demo文件中,有如下文件以及相关的作用:
__init__.py:初始化脚本
items.py:Items代码模板(继承类)
middlewares.py:Middlewares代码模板(继承类)
Pipelines.py:Pipelines代码模块(继承类)
settings.py:Scrapy爬虫的配置文件(优化需要改动)
spiders:代码模板目录(继承类)
在Spider文件目录下包含如下文件:
__init__.py:初始文件。无需修改
__pycache_:缓存目录,无需修改
项目实现
接下来我们开始第一次的实操,大致步骤如下:
1、建立一个Scrapy爬虫工程
2、在工程中产生一个Scrapy爬虫
3、配置产生的spider爬虫
4、运行爬虫,获取网页
1、新建项目
首先,我们得先新建一个项目文件。
这里需要我们打开Git,至于Git的安装以及简单使用我们之前在折腾博客时有了解过:用Hexo+Github Pages搭建私人博客(第二站)
首先打开Git定位到你要爬虫项目的地址:
比如小编我是要定位到E盘,则输入cd E:(图2)

定位到目标地址后,我们便可以开始新建项目啦~
To:dir命令为显示目录和子目录的列表。
2、新建Scrapy
接下来我们输入如下命令新建一个名为newdemo的爬虫项目:
scrapy startproject newdemo
项目生成后我们可以看见在根目录生成了一个项目文件,也是叫做newdemo,那么接下来我们需要对其中的文件进行编辑。(图3)
3、配置Spider爬虫
接下来我们需要输入如下命令:
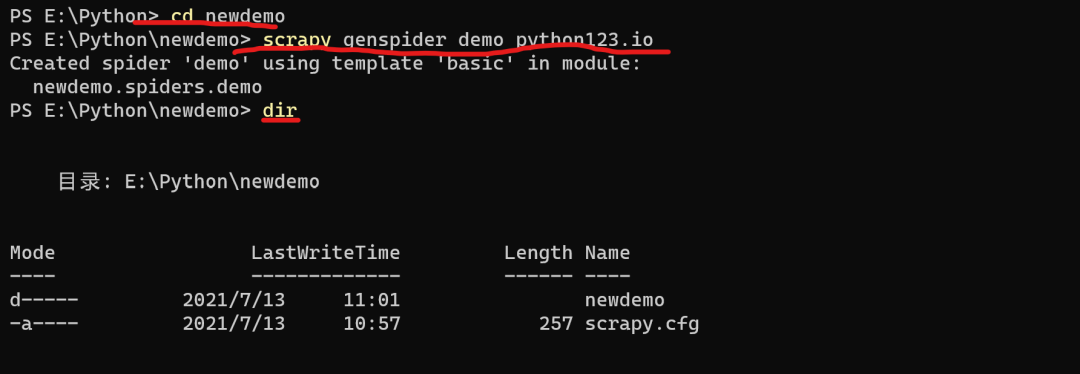
scrapy genspider demo python123.io
相关运行结果如下:(图4)
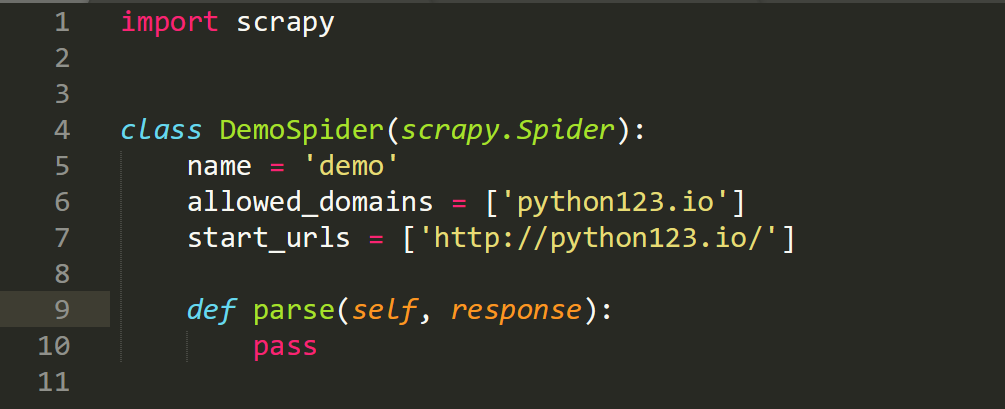
然后会在newdemo\spiders目录下生成一个demo.py文件 其中,parse(用于处理响应,解析内容形成字典,发现新的URL爬取请求)(图5)
修改demo文件里面的代码,修改后如下:
import scrapy
#继承Scrapy.Spider类的子类
class DemoSpider(scrapy.Spider):
name = 'demo'#当前爬虫命名为demo
#allowed_domains = ['python123.io'] #用户在命令行提交给爬虫的域名
start_urls = ['http://python123.io/ws/demo.html']#爬取内容的初始页面#parse()用于处理响应,解析内容形成字典,发现新的URL爬取请求
def parse(self, response):
fname=response.url.split('/')[-1]
with open (fname,'wb') as f:
f.write(response.body)
self.log('save file %s' % name)
4、运行项目
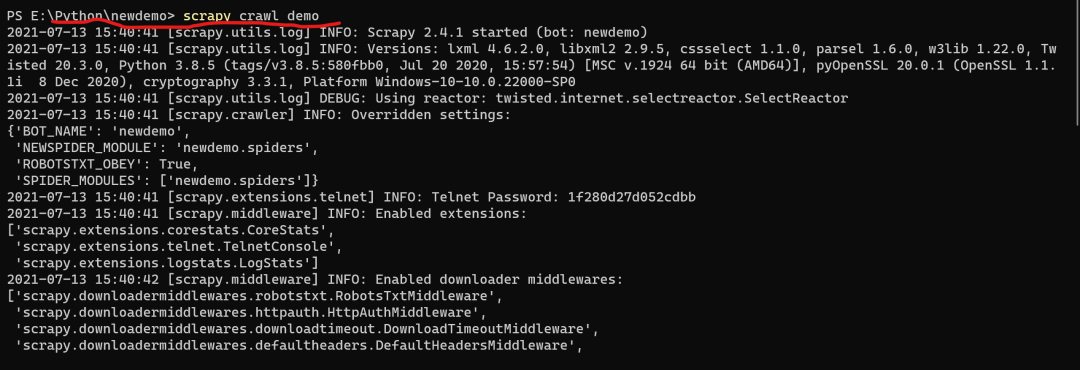
最后一步便是运行该爬虫项目,命令为:
scrapy crawl demo
相关运行结果如下:(图6)
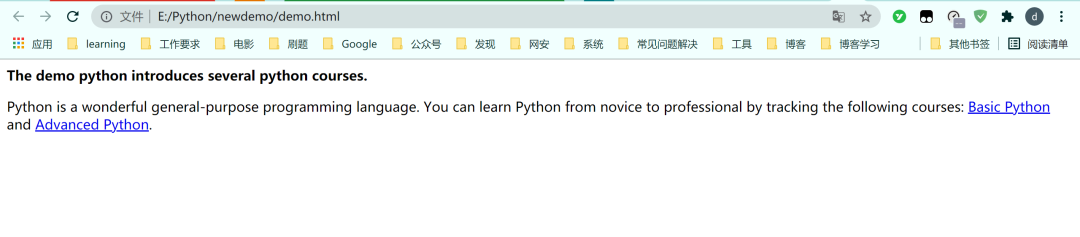
直到最后在newdemo文件目录下出现demo.html文件,说明此项目运行成功。
打开demo.html文件显示如下:(图7)
Python爬虫系列,持续更新...
Python爬虫之Scrapy框架爬虫实战的更多相关文章
- Python爬虫进阶(Scrapy框架爬虫)
准备工作: 配置环境问题什么的我昨天已经写了,那么今天直接安装三个库 首先第一步: ...
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
- Python逆向爬虫之scrapy框架,非常详细
爬虫系列目录 目录 Python逆向爬虫之scrapy框架,非常详细 一.爬虫入门 1.1 定义需求 1.2 需求分析 1.2.1 下载某个页面上所有的图片 1.2.2 分页 1.2.3 进行下载图片 ...
- Scrapy框架-----爬虫
说明:文章是本人读了崔庆才的Python3---网络爬虫开发实战,做的简单整理,希望能帮助正在学习的小伙伴~~ 1. 准备工作: 安装Scrapy框架.MongoDB和PyMongo库,如果没有安装, ...
- 第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用
第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用 xpath表达式 //x 表示向下查找n层指定标签,如://div 表示查找所有div标签 /x 表示向下查找一层指定的标签 ...
- 第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令 Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --u ...
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录 模拟浏览器登录 start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于star ...
- 爬虫06 /scrapy框架
爬虫06 /scrapy框架 目录 爬虫06 /scrapy框架 1. scrapy概述/安装 2. 基本使用 1. 创建工程 2. 数据分析 3. 持久化存储 3. 全栈数据的爬取 4. 五大核心组 ...
随机推荐
- MAC 不带XIB新建ViewController
- (void)loadView{ NSView *view = [[NSView alloc]init]; self.view = view; } MAC 开发的小伙伴
- DOS下的一些命令
DOS一些命令 1.查看无线密码 netsh wlan show profiles #显示所有本地电脑加入过的wlan netsh wlan show profiles name=&q ...
- WRF rsl.out文件研究
本文翻译自https://www2.mmm.ucar.edu/wrf/users/FAQ_files/FAQ_wrf_runtime.html Q1 我应该使用几个处理器来运行wrf.exe? A1 ...
- HttpClient常用的一些常识
HttpClient是目前我们通讯组件中最常见的一个Api了吧.至少从我目前接触到与外部系统通讯的话是这样的.下面我将我自己常用的一些知识总结一下. 因为本猿也是边写边总结,有啥不对的还望多多指出. ...
- mysql 取出分组后价格最高的数据
如何用mysql 取出分组后价格最高的数据 ? 看到这个问题,就想到了用 max 函数和 group by 函数,先 group by 然后取得 max, 但是这样真的可以吗? 不可以 ! 为什么? ...
- GitBook的使用备忘
GitBook环境搭建 npm install -g gitbook-cli # 新建目录,如helloworld cd helloworld # 执行此语句,需等待一段时间 gitbook init ...
- 使用emplace_back的new initializer expression list treated as compound expression提示看聚合初始化和parameter pack
测试代码 使用emplace_back可以避免不必要的构造和拷贝,而是直接在向量的内存位置执行construct进行构造,代码看起来也更加简洁. 但是在使用的时候,会发现有一些和直观不太对应的情况.例 ...
- C++ 11 std::mem_fn
mem_fn 想到member function 成员函数 这还真就是用来调用成员函数的 普通的函数我们通过函数指针可以调用,但对于成员函数的调用稍微复杂一点,需要对象,也即this指针 因为成员函数 ...
- Django和DRF的区别
Django和DRF的区别 一.Django REST Framwork 和 Django 1.两者的概念: Django REST Framwork: 将数据库的东西通过ORM的映射取出来,通过vi ...
- c++循环输入数字std::cin如何结束
代码: #include <iostream> int main(int argc, const char * argv[]) { int sum = 0,value=0; while ...