Python爬虫之Scrapy框架爬虫实战
Python爬虫中Scrapy框架应用非常广泛,经常被人用于属于挖掘、检测以及自动化测试类项目,为啥说Scrapy框架作为半成品我们又该如何利用好呢 ?下面的实战案例值得大家看看。
目录:
1、Scrapy框架之命令行
2、项目实现
Scrapy框架之命令行
Scrapy是为持续运行设计的专业爬虫框架,提供操作的Scrapy命令行。
Scrapy爬虫的常用命令:
scrapy<command>[option][args]#command为Scrapy命令
常用命令:(图1)
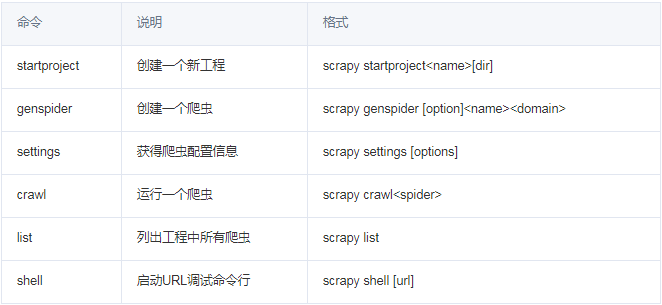
至于为什么要用命令行,主要是我们用命令行更方便操作,也适合自动化和脚本控制。至于用Scrapy框架,一般也是较大型的项目,程序员对于命令行也更容易上手。
首先介绍一下相关文件的作用,方便我们到时候修改相关代码。
scrapy.cfg:部署Scrapy爬虫的配置文件
demo:Scrapy框架的用户自定义Python代码
其中,在项目文件根目录里面的demo文件中,有如下文件以及相关的作用:
__init__.py:初始化脚本
items.py:Items代码模板(继承类)
middlewares.py:Middlewares代码模板(继承类)
Pipelines.py:Pipelines代码模块(继承类)
settings.py:Scrapy爬虫的配置文件(优化需要改动)
spiders:代码模板目录(继承类)
在Spider文件目录下包含如下文件:
__init__.py:初始文件。无需修改
__pycache_:缓存目录,无需修改
项目实现
接下来我们开始第一次的实操,大致步骤如下:
1、建立一个Scrapy爬虫工程
2、在工程中产生一个Scrapy爬虫
3、配置产生的spider爬虫
4、运行爬虫,获取网页
1、新建项目
首先,我们得先新建一个项目文件。
这里需要我们打开Git,至于Git的安装以及简单使用我们之前在折腾博客时有了解过:用Hexo+Github Pages搭建私人博客(第二站)
首先打开Git定位到你要爬虫项目的地址:
比如小编我是要定位到E盘,则输入cd E:(图2)

定位到目标地址后,我们便可以开始新建项目啦~
To:dir命令为显示目录和子目录的列表。
2、新建Scrapy
接下来我们输入如下命令新建一个名为newdemo的爬虫项目:
scrapy startproject newdemo
项目生成后我们可以看见在根目录生成了一个项目文件,也是叫做newdemo,那么接下来我们需要对其中的文件进行编辑。(图3)
3、配置Spider爬虫
接下来我们需要输入如下命令:
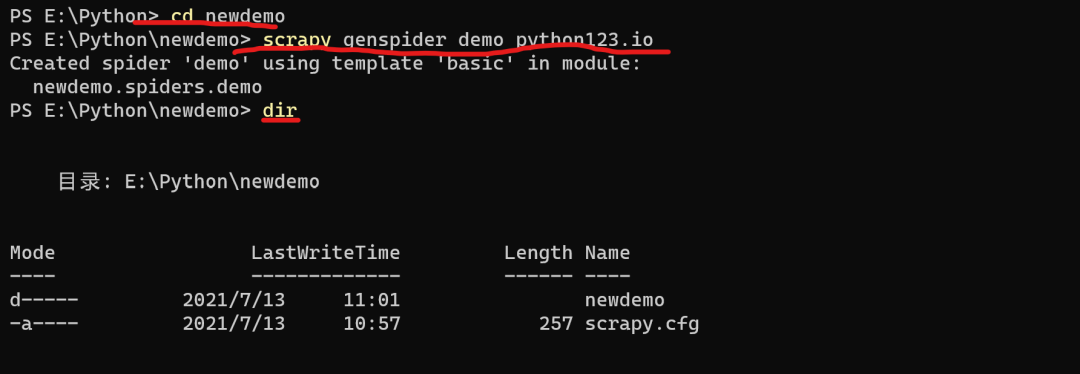
scrapy genspider demo python123.io
相关运行结果如下:(图4)
然后会在newdemo\spiders目录下生成一个demo.py文件 其中,parse(用于处理响应,解析内容形成字典,发现新的URL爬取请求)(图5)
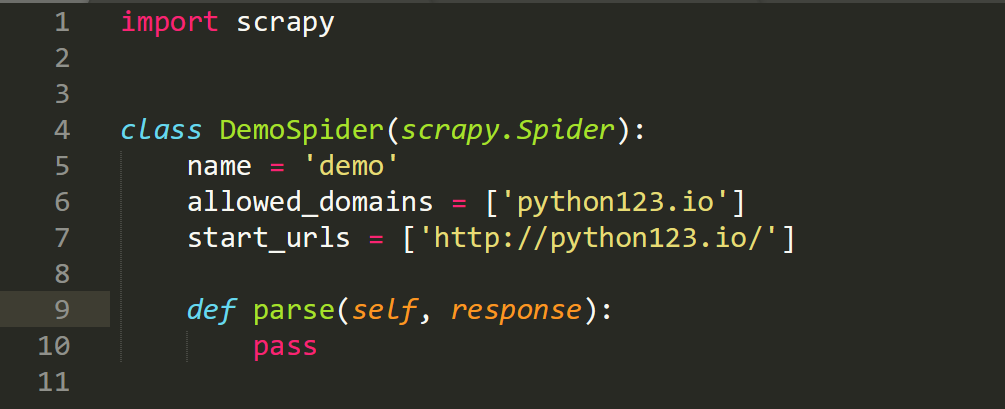
修改demo文件里面的代码,修改后如下:
import scrapy
#继承Scrapy.Spider类的子类
class DemoSpider(scrapy.Spider):
name = 'demo'#当前爬虫命名为demo
#allowed_domains = ['python123.io'] #用户在命令行提交给爬虫的域名
start_urls = ['http://python123.io/ws/demo.html']#爬取内容的初始页面#parse()用于处理响应,解析内容形成字典,发现新的URL爬取请求
def parse(self, response):
fname=response.url.split('/')[-1]
with open (fname,'wb') as f:
f.write(response.body)
self.log('save file %s' % name)
4、运行项目
最后一步便是运行该爬虫项目,命令为:
scrapy crawl demo
相关运行结果如下:(图6)
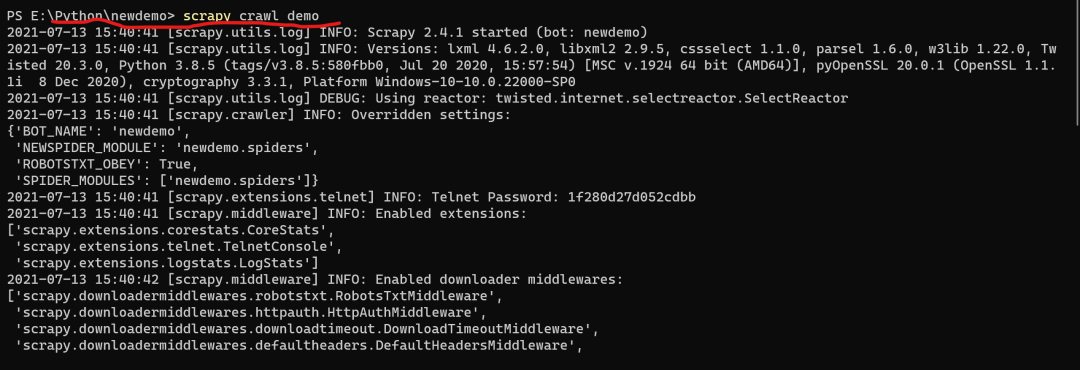
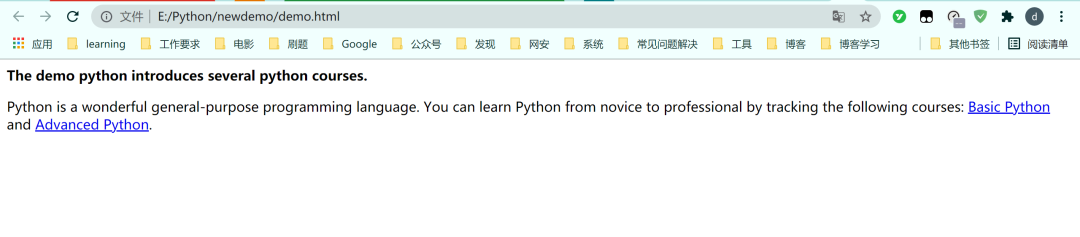
直到最后在newdemo文件目录下出现demo.html文件,说明此项目运行成功。
打开demo.html文件显示如下:(图7)
Python爬虫系列,持续更新...
Python爬虫之Scrapy框架爬虫实战的更多相关文章
- Python爬虫进阶(Scrapy框架爬虫)
准备工作: 配置环境问题什么的我昨天已经写了,那么今天直接安装三个库 首先第一步: ...
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
- Python逆向爬虫之scrapy框架,非常详细
爬虫系列目录 目录 Python逆向爬虫之scrapy框架,非常详细 一.爬虫入门 1.1 定义需求 1.2 需求分析 1.2.1 下载某个页面上所有的图片 1.2.2 分页 1.2.3 进行下载图片 ...
- Scrapy框架-----爬虫
说明:文章是本人读了崔庆才的Python3---网络爬虫开发实战,做的简单整理,希望能帮助正在学习的小伙伴~~ 1. 准备工作: 安装Scrapy框架.MongoDB和PyMongo库,如果没有安装, ...
- 第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用
第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用 xpath表达式 //x 表示向下查找n层指定标签,如://div 表示查找所有div标签 /x 表示向下查找一层指定的标签 ...
- 第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令 Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --u ...
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录 模拟浏览器登录 start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于star ...
- 爬虫06 /scrapy框架
爬虫06 /scrapy框架 目录 爬虫06 /scrapy框架 1. scrapy概述/安装 2. 基本使用 1. 创建工程 2. 数据分析 3. 持久化存储 3. 全栈数据的爬取 4. 五大核心组 ...
随机推荐
- ESP32-IDF 在vscode环境搭建
前言 由于许多的未知原因,我尝试过许多网上教程,在vscode上搭建ESP-IDF环境,但结果是耗费了大把时间,结果还非常不理想. 在参考了(一)esp32开发环境搭建(VSCode+IDF实现单步调 ...
- 监听 view 初始化时
new ViewTreeObserverRegister().observe(getContentView(), new ViewTreeObserver.OnGlobalLayoutListener ...
- Ubuntu 18.04 安装基本应用
Ubuntu 谷歌浏览器下载:第一步打开终端,在终端输入下载命令wget https://dl.google.com/linux/direct/google-chrome-stable_current ...
- python虚拟环境和包管理
新建一个虚拟环境: python3 -m venv env1 # 新建一个名称为env1的虚拟环境 激活环境: source env1/bin/activate 退出虚拟环境: deactivate ...
- elasticSearch(六)--全文搜索
数据案例 1.匹配查询 a.单词查询 执行match步骤: ·检查field类型:title字段为(analyzed)字符串,所以搜索时,title需要被分析. ·分析查询字符串:QUICK! 经过标 ...
- Github搜索优质项目方法
[转载]:https://www.zhihu.com/question/20084458 搜索结果会显示非常多的开源项目,简直让你应接不暇,无从下手,很多小伙伴搜到这一步就放弃了,因为项目太多了,根本 ...
- maven重点分析
目录 什么是maven pom.xml 约定大于配置 根元素和必要配置 父项目和parent元素 项目构建需要的信息 路径管理 资源管理 详细使用 filtering的使用 怎么理解pom中多个res ...
- python max()用法
起因是看到一道面试题 "统计字符串中出现次数最多的字符,并返回出现次数" 问题很简单,刚开始没思路,只想到了循环统计,但是觉得太蠢了,直到我发现了max()的key用法,果然还是我 ...
- linux离线安装gcc 和g++
1.先到有网的机器上下载依赖包 sudo yum install --downloadonly --downloaddir=/home/mjb/soft/gcc gcc sudo yum instal ...
- docker搭建phpswoole实现http服务
一.创建Dockerfile FROM phpswoole/swoole # COPY ./www/ /var/www/ 二.同级目录下创建docker-compose.yml services: p ...