pandas常用操作详解——数据运算(一)
表与表之间的数据运算
#构建数据集
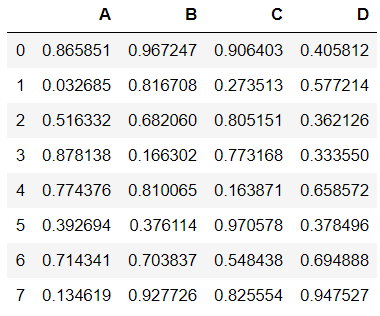
df1=pd.DataFrame(np.random.random(32).reshape(8,4),columns=list('ABCD'))
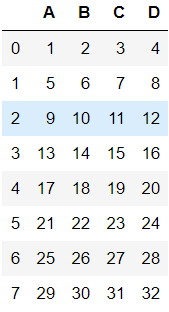
df2=pd.DataFrame(np.arange(1,33).reshape(8,4),columns=list('ABCD'))
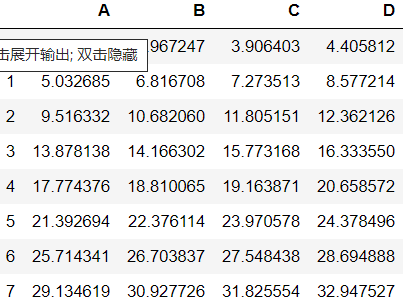
#进行加法运算
#注:加减乘除同理
data1=df1+df2
表与列之间的计算
这里不知道有没有别的函数可以调用,或者更简单的计算方式,等我发现了再更新。
#构造一个Series
df3=pd.Series(np.arange(8))

#用一个循环语句实现dataframe中的每一列与Series的计算
#加减乘除同理
for i in list('ABCD'):
df1.loc[:,i]=df1.loc[:,i]*df3
df1

#同乘一个数
data3=df1*30
data3

pandas常用操作详解——数据运算(一)的更多相关文章
- pandas常用操作详解——pandas的去重操作df.duplicated()与df.drop_duplicates()
df.duplicated() 参数详解: subset:检测重复的数据范围.默认为数据集的所有列,可指定特定数据列: keep: 标记哪个重复数据,默认为'first'.1.'first':标记重复 ...
- pandas常用操作详解——pd.concat()
concat函数基本介绍: 功能:基于同一轴将多个数据集合并 pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=Fa ...
- pandas常用操作详解——info()与descirbe()
概述 df.info():主要介绍数据集各列的数据类型,是否为空值,内存占用情况: df.describe(): 主要介绍数据集各列的数据统计情况(最大值.最小值.标准偏差.分位数等等). df.in ...
- pandas常用操作详解(复制别人的)——数据透视表操作:pivot_table()
原文链接:https://www.cnblogs.com/Yanjy-OnlyOne/p/11195621.html 一文看懂pandas的透视表pivot_table 一.概述 1.1 什么是透视表 ...
- pandas常用操作详解——.loc与.iloc函数的使用及区别
loc与iloc功能介绍:数据切片.通过索引来提取数据集中相应的行数据or列数据(可以是多行or多列) 总结: 不同:1. loc函数通过调用index名称的具体值来取数据2. iloc函数通过行序号 ...
- Pandas 常见操作详解
Pandas 常见操作详解 很多人有误解,总以为Pandas跟熊猫有点关系,跟gui叔创建Python一样觉得Pandas是某某奇葩程序员喜欢熊猫就以此命名,简单介绍一下,Pandas的命名来自于面板 ...
- Linux Shell数组常用操作详解
Linux Shell数组常用操作详解 1数组定义: declare -a 数组名 数组名=(元素1 元素2 元素3 ) declare -a array array=( ) 数组用小括号括起,数组元 ...
- 【Git使用详解】Egit的常用操作详解
常用操作 操作 说明 Fetch 从远程获取最新版本到本地,不会自动merge Merge 可以把一个分支标签或某个commit的修改合并现在的分支上 Pull 从远程获取最新版本并merge到本地相 ...
- 【python+selenium的web自动化】- 元素的常用操作详解(一)
如果想从头学起selenium,可以去看看这个系列的文章哦! https://www.cnblogs.com/miki-peng/category/1942527.html 本篇主要内容:1.元素 ...
随机推荐
- _call妙用
class Magic { function __call($name,$arguments) { if($name=='foo') { if(is_int($arguments[0])) $this ...
- 把 Navigation Bar 下面那条线删掉的最简单的办法! — By: 昉
系统默认的 Navigation Bar 下面一直有条线,翻尽了文档却没找到能把它弄走的相关接口,处女座的简直木法忍啊有木有!!!! 研究了一下navigationBar下的子视图,原来只需要几行代码 ...
- Docker部署lnmp 实战 (多注意配置文件,不管访问试试换个浏览器)
Docker部署LNMP环境 关闭防火墙,设置自定义网络 systemctl stop firewalld systemctl disable firewalld setenforce 0 docke ...
- JSP页面 CTRL+F 功能实现
.res { color: rgba(255, 0, 0, 1) } .result { background: rgba(255, 255, 0, 1) } --- js 部分 var oldKey ...
- 从MVC到DDD的架构演进
DDD这几年越来越火,资料也很多,大部分的资料都偏向于理论介绍,有给出的代码与传统MVC的三层架构差异较大,再加上大量的新概念很容易让初学者望而却步.本文从MVC架构角度来讲解如何演进到DDD架构. ...
- 静态分离 & rewrit 重写 & HTTPS
内容概要 资源分离 Nginx 的 Rewrite重写 HTTPS 内容详细 一.动静分离 1.在 nfs 中创建 NFS 挂载点 [root@nfs static]# mkdir /static [ ...
- 海盗湾The Pirate Bay:每一名技术人员都应该思考的问题
海盗湾The Pirate Bay:一场互联网技术下没有硝烟的战争 写在前面: 开学啦,返校啦!祝大家新的一年,工作顺顺利利,家庭幸福美满! 正文: 假期的时候,闲来无事,看了几部纪录片,其中< ...
- Mybatis第三方PageHelper分页插件原理
欢迎关注公号:BiggerBoy,看更多文章 原文链接:https://mp.weixin.qq.com/s?__biz=MzUxNTQyOTIxNA==&mid=2247485158&a ...
- MySQL 利用frm文件和ibd文件恢复表结构和表数据
文章目录 frm文件和ibd文件简介 frm文件恢复表结构 ibd文件恢复表数据 通过脚本利用ibd文件恢复数据 通过shell脚本导出mysql所有库的所有表的表结构 frm文件和ibd文件简介 在 ...
- c++ 字符串替换程序 p324
字符串替换程序 C++ Primer 324页 // replace:从str字符串中查找oldVal字符串,如果找到就替换成newVal字符串. void replace(string &s ...