矩池云 | 新冠肺炎防控:肺炎CT检测
连日来,新型冠状病毒感染的肺炎疫情,牵动的不仅仅是全武汉、全湖北,更是全国人民的心,大家纷纷以自己独特的方式为武汉加油!我们相信坚持下去,终会春暖花开。
今天让我们以简单实用的神经网络模型,来检测肺炎的CT影像。
第一步:导入我们需要的库
from keras.preprocessing.image import ImageDataGenerator, load_img
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, ZeroPadding2D, Conv2D, MaxPooling2D, Activation
from keras.optimizers import Adam, SGD, RMSprop
from keras.callbacks import EarlyStopping
from keras import backend as K
import tensorflow as tf
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.9
K.tensorflow_backend.set_session(tf.Session(config=config))
import os
import numpy as np
import pandas as np
import cv2
from glob import glob
import matplotlib.pyplot as plt
%matplotlib inline
第二步:数据查看
2.1 先确认下我们数据的目录结构:
在chest_xray文件夹中,我们将数据分成了训练病例数据(train), 测试病例数据(test), 验证病例数据(val);
每个训练数据,测试数据,验证数据的文件夹中我们又分成了正常的病例数据(normal), 肺炎病例数据(pneumonia)。
print("训练病例数据")
print(os.listdir("chest_xray"))
print(os.listdir("chest_xray/train"))
print(os.listdir("chest_xray/train/"))
训练病例数据
['test', 'train', 'val', '.DS_Store']
['NORMAL', '.DS_Store', 'PNEUMONIA']
['NORMAL', '.DS_Store', 'PNEUMONIA']
print("测试病例数据")
print(os.listdir("chest_xray"))
print(os.listdir("chest_xray/test"))
print(os.listdir("chest_xray/test/"))
测试病例数据
['test', 'train', 'val', '.DS_Store']
['NORMAL', '.DS_Store', 'PNEUMONIA']
['NORMAL', '.DS_Store', 'PNEUMONIA']
print("验证病例数据")
print(os.listdir("chest_xray"))
print(os.listdir("chest_xray/val"))
print(os.listdir("chest_xray/val/"))
验证病例数据
['test', 'train', 'val', '.DS_Store']
['NORMAL', '.DS_Store', 'PNEUMONIA']
['NORMAL', '.DS_Store', 'PNEUMONIA']
2.2 用matpolt 来可视化我们的病例数据:
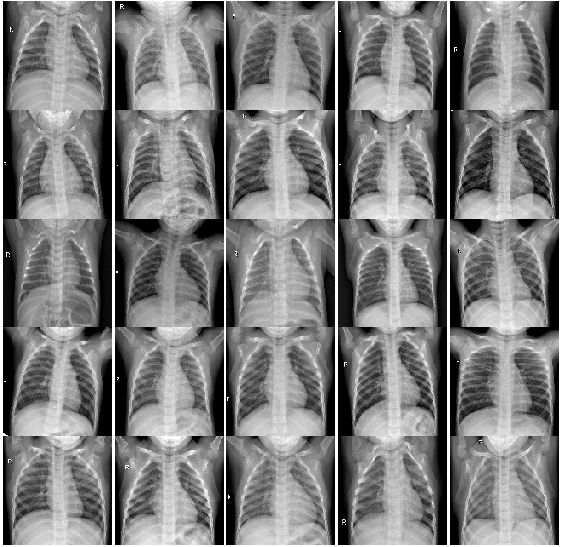
2.2.1 没有肺炎的20个病例的CT图片:
multipleImages = glob('chest_xray/train/NORMAL/**')
i_ = 0
plt.rcParams['figure.figsize'] = (10.0, 10.0)
plt.subplots_adjust(wspace=0, hspace=0)
for l in multipleImages[:25]:
im = cv2.imread(l)
im = cv2.resize(im, (128, 128))
plt.subplot(5, 5, i_+1) #.set_title(l)
plt.imshow(cv2.cvtColor(im, cv2.COLOR_BGR2RGB)); plt.axis('off')
i_ += 1
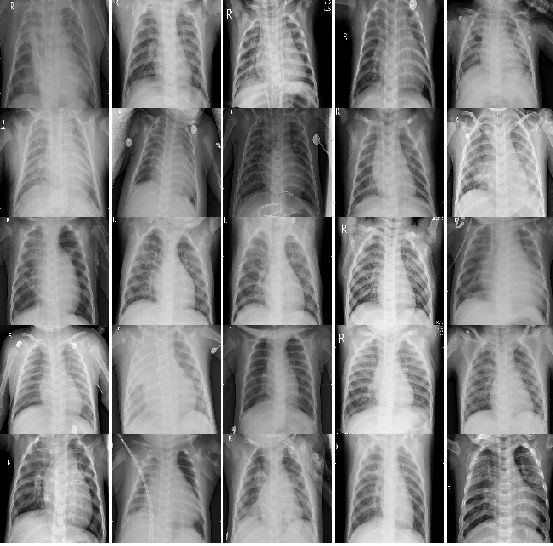
2.2.2 有肺炎的20个病例的CT图片:
multipleImages = glob('chest_xray/train/PNEUMONIA/**')
i_ = 0
plt.rcParams['figure.figsize'] = (10.0, 10.0)
plt.subplots_adjust(wspace=0, hspace=0)
for l in multipleImages[:25]:
im = cv2.imread(l)
im = cv2.resize(im, (128, 128))
plt.subplot(5, 5, i_+1) #.set_title(l)
plt.imshow(cv2.cvtColor(im, cv2.COLOR_BGR2RGB)); plt.axis('off')
i_ += 1
第三步:数据预处理
3.1 首先先定义一些我们需要使用到的变量
# 图片尺寸
image_width = 226
image_height = 226
3.2 处理下图片的通道数在输入数据中的格式问题
if K.image_data_format() == 'channels_first':
input_shape = (3, image_width, image_height)
else:
input_shape = (image_width, image_height, 3)
3.3 数据加载和增强
这个案例,我们使用Keras的
ImageDataGenerator来加载我们的数据,并且做数据增强跟处理。
ImageDataGenerator
是keras.preprocessing.image模块中的图片生成器,同时也可以在batch中对数据进行增强,扩充数据集大小,增强模型的泛化能力。比如进行旋转,变形,归一化等。
3.3.1 定义训练数据的ImageDataGenerator
- 训练数据的ImageDataGenerator我们做了如下几个处理:
- 将像素值归一化 (rescale)
- 剪切强度(逆时针方向的剪切变换角度),强度为0.2
- 随机缩放的幅度, 当前为0.2
- 水平翻转
train_data_gen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
3.3.2 定义测试数据的ImageDataGenerator
测试数据我们只做了归一化处理
test_data_gen = ImageDataGenerator(rescale=1. / 255)
3.4 使用我们定义好的ImageDataGenerator从文件夹中读取数据, 其中target_size参数会把我们读入的原始数据缩放到我们想要的尺寸
3.4.1 训练数据读取
train_generator = train_data_gen.flow_from_directory(
'chest_xray/train',
target_size=(image_width, image_height),
batch_size=16,
class_mode='categorical')
Found 5216 images belonging to 2 classes.
3.4.2 验证数据读取
validation_generator = test_data_gen.flow_from_directory(
'chest_xray/val',
target_size=(image_width, image_height),
batch_size=16,
class_mode='categorical')
Found 16 images belonging to 2 classes.
3.4.3 测试数据读取
test_generator = test_data_gen.flow_from_directory(
'chest_xray/test',
target_size=(image_width, image_height),
batch_size=16,
class_mode='categorical')
Found 624 images belonging to 2 classes.
第四步:模型构建
4.1 定义我们的模型
我们的模型层次采用VGG16 网络模型,
原模型链接:
https://gist.github.com/baraldilorenzo/07d7802847aaad0a35d3
4.1.1 VGG
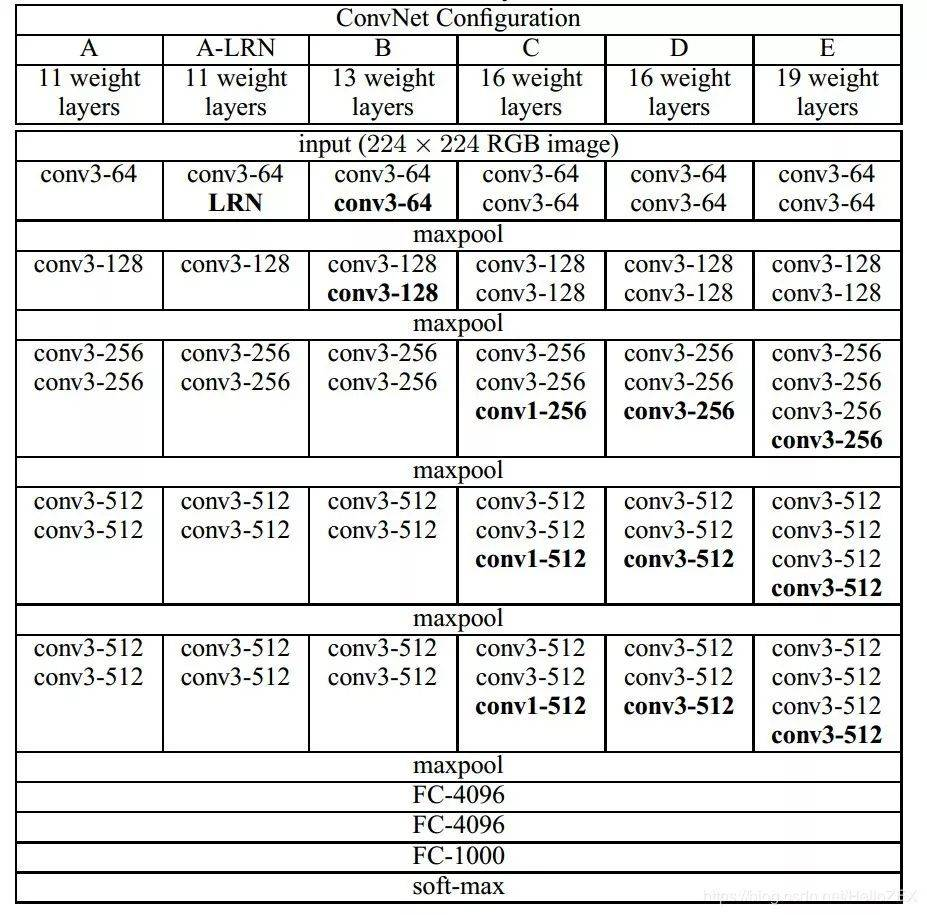
VGG是由Simonyan 和Zisserman在文献《Very Deep Convolutional Networks for Large Scale Image Recognition》中提出卷积神经网络模型,其名称来源于作者所在的牛津大学视觉几何组(Visual Geometry Group)的缩写。
该模型参加2014年的 ImageNet图像分类与定位挑战赛,取得了优异成绩:在分类任务上排名第二,在定位任务上排名第一。
VGG结构图:
4.1.2 VGG16
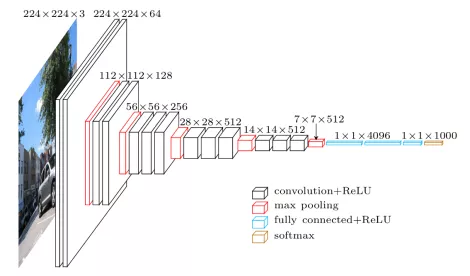
VGG模型有一些变种,其中最受欢迎的当然是 VGG-16,这是一个拥有16层的模型。你可以看到它需要维度是 224x224x3 的输入数据。
VGG16输入224x224x3的图片,经过的卷积核大小为3x3x3,stride=1,padding=1,pooling为采用2x2的Max Pooling方式:
- 输入224x224x3的图片,经过64个卷积核的两次卷积后,采用一次Max Pooling
- 再经过两次128的卷积核卷积之后,采用一次Max Pooling
- 再经过三次256的卷积核的卷积之后,采用Max Pooling
- 重复两次三个512的卷积核卷积之后再Max Pooling
- 三次FC
VGG 16结构图
下面我们使用Keras 建立VGG 16 模型
model = Sequential()
model.add(ZeroPadding2D((1,1),input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(256, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(256, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(256, (3, 3), activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(512, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(512, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(512, (3, 3), activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(512, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(512, (3, 3), activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(512, (3, 3), activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(2, activation='softmax'))
4.2 查看下模型概况
model.summary()
4.3 编译模型
我们使用Adam优化器,并且设置learning rate为0.0001,对验证集的精确度添加early stopping monitor,并且patinece设置成3,这个参数的意思,当我们有3个连续的epochs没有提升精度,我们就停止训练,防止过拟合。
optimizer = Adam(lr = 0.0001)
early_stopping_monitor = EarlyStopping(patience = 3, monitor = "val_accuracy", mode="max", verbose = 2)
model.compile(loss="categorical_crossentropy", metrics=["accuracy"], optimizer=optimizer)
第五步:肺炎CT模型训练
5.1 训练模型
history = model.fit_generator(epochs=5, callbacks=[early_stopping_monitor], shuffle=True,
validation_data=validation_generator, generator=train_generator,
steps_per_epoch=500, validation_steps=10,verbose=2)
5.2 模型在训练过程中,训练数据集的精度和损失值会发生变化。
有次可见,我们的模型在训练的时候,精度不断提高,因此看到我们的模型在逐渐收敛到最佳的状态。
plt.plot(history.history['accuracy'])
plt.title('Model Accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['train'], loc='upper left')
plt.show()
plt.plot(history.history['loss'])
plt.title('Model Loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['train'], loc='best')
plt.show()
第六步: 模型在测试集数据上的使用
scores = model.evaluate_generator(test_generator)
print("\n%s: %.2f%%" % (model.metrics_names[1], scores[1]*100))
具体的数据结果,欢迎各自进行尝试实验
当前 “新冠肺炎防控-肺炎CT检测” 案例镜像已经在矩池云GPU云共享平台正式上线。
感兴趣的小伙伴可以通过官网“机器租赁” — “我要租赁” — “选择镜像” — “Jupyter 教程 Demo”中尝试使用。
矩池云 | 新冠肺炎防控:肺炎CT检测的更多相关文章
- 矩池云助力科研算力免费上"云",让 AI 教学简单起来
矩池云是一个专业的国内深度学习云平台,拥有着良好的深度学习云端训练体验,和高性价比的GPU集群资源.而且对同学们比较友好,会经常做一些大折扣的活动,最近双十一,全场所有的RTX 2070.Platin ...
- 矩池云上使用nvidia-smi命令教程
简介 nvidia-smi全称是NVIDIA System Management Interface ,它是一个基于NVIDIA Management Library(NVML)构建的命令行实用工具, ...
- 如何使用 VS Code 远程连接矩池云主机
Visual Studio Code(以下简称 VS Code)是一个由微软开发的代码编辑器.VS Code 支持代码补全.代码片段.代码重构.Git 版本控制等功能. VS Code 现已支持连接远 ...
- 矩池云 | 利用LSTM框架实时预测比特币价格
温馨提示:本案例只作为学习研究用途,不构成投资建议. 比特币的价格数据是基于时间序列的,因此比特币的价格预测大多采用LSTM模型来实现. 长期短期记忆(LSTM)是一种特别适用于时间序列数据(或具有时 ...
- 矩池云 | Tony老师解读Kaggle Twitter情感分析案例
今天Tony老师给大家带来的案例是Kaggle上的Twitter的情感分析竞赛.在这个案例中,将使用预训练的模型BERT来完成对整个竞赛的数据分析. 导入需要的库 import numpy as np ...
- 矩池云 | 使用LightGBM来预测分子属性
今天给大家介绍提升方法(Boosting), 提升算法是一种可以用来减小监督式学习中偏差的机器学习算法. 面对的问题是迈可·肯斯(Michael Kearns)提出的:一组"弱学习者&quo ...
- 矩池云 | 神经网络图像分割:气胸X光片识别案例
在上一次肺炎X光片的预测中,我们通过神经网络来识别患者胸部的X光片,用于检测患者是否患有肺炎.这是一个典型的神经网络图像分类在医学领域中的运用. 另外,神经网络的图像分割在医学领域中也有着很重要的用作 ...
- 矩池云里查看cuda版本
可以用下面的命令查看 cat /usr/local/cuda/version.txt 如果想用nvcc来查看可以用下面的命令 nvcc -V 如果环境内没有nvcc可以安装一下,教程是矩池云上如何安装 ...
- 在矩池云上复现 CVPR 2018 LearningToCompare_FSL 环境
这是 CVPR 2018 的一篇少样本学习论文:Learning to Compare: Relation Network for Few-Shot Learning 源码地址:https://git ...
随机推荐
- C++ 类对象内存模型分析
编译环境:Windows10 + VS2015 1.空类占用的内存空间 类占内存空间是只类实例化后占用内存空间的大小,类本身是不会占内存空间的.用sizeof计算类的大小时,实际上是计算该类实例化后对 ...
- AtCoder Beginner Contest 146_E - Rem of Sum is Num
预处理即可 我们要找的是 (f[i] - f[j]) % k == i - j 移项可得 f[i] - i = f[j] - j 在 i - j <= k 的条件下 因此题目变成了,对于每个右端 ...
- ApacheCN Java 译文集 20210921 更新
新增了五个教程: Java 设计模式最佳实践 零.前言 一.从面向对象到函数式编程 二.创建型模式 三.行为模式 四.结构模式 五.函数式模式 六.让我们开始反应式吧 七.反应式设计模式 八.应用架构 ...
- Mysql自序整理集
1.事务 mysql事务是用于处理操作量大.复杂性高的数据 1. 事务特性 原子性:保证每个事务所有操作要么全部完成或全部不完成,不可能停滞在中间环节:如事务在执行过程中出现错误,则会回滚到事务开始之 ...
- Java中的输入流与输出流
一.流的概念 在Java中,流是从源到目的地的字节的有序序列.Java中有两种基本的流--输入流(InputStream)和输出流(OutputStream). 根据流相对于程序的另一个端点的不同,分 ...
- HMS Core 能力速配,唱响恋爱进行曲
情人节,HMS Core 最具CP感的能力搭档来袭,浓浓爱意,表白各行业,你准备好了吗? 1.ML Kit +Signpal Kit 科技相助,恋爱提速.展现爱意的方式有千百种,你可以用文本翻译学习数 ...
- Java中的多线程你只要看这一篇就够了(引用)
引 如果对什么是线程.什么是进程仍存有疑惑,请先Google之,因为这两个概念不在本文的范围之内. 用多线程只有一个目的,那就是更好的利用cpu的资源,因为所有的多线程代码都可以用单线程来实现.说这个 ...
- Solution Set -「LOCAL」冲刺省选 Round XXIV
\(\mathscr{Summary}\) 名副其实的 trash round,希望以后没有了. A 题算好,确实一个比较关键的简化状态的点没想到,所以只拿了暴力(不考虑 \(\mathcal ...
- SQLMAP配置洋葱路由
[笔者目前使用的系统是kali渗透系统] =================================================================== 首先下载tor apt ...
- RFC2889——拥塞控制测试
一.简介 RFC 2889为LAN交换设备的基准测试提供了方法学,它将RFC 2544中为网络互联设备基准测试所定义的方法学扩展到了交换设备,提供了交换机转发性能(Forwarding Perform ...