机器学习 —— 概率图模型(学习:CRF与MRF)
在概率图模型中,有一类很重要的模型称为条件随机场。这种模型广泛的应用于标签—样本(特征)对应问题。与MRF不同,CRF计算的是“条件概率”。故其表达式与MRF在分母上是不一样的。

如图所示,CRF只对 label 进行求和,而不对dataset求和。
1、CRF的likelyhood function
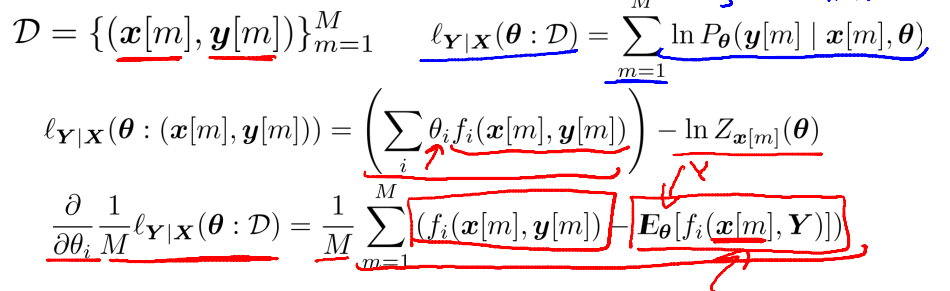
对于给定的数据集以及其对应标记,CRF的 E based on theta 是与 数据集 x[m]有关的,因为x[m]并没有完全被边际掉。也就是说,对数据集中的每个数据x[m],E based on theta 都是不一样的。这是CRF与MRF最大的不同。MRF完全边际掉了x,所以对任意数据集,E_theta 都相同。以图像分割中经典的双牛图为例:

1、图像是聚类后的图像,已经进行了超分割
2、X代表超像素,Y代表标签
3、Gs代表平均绿强度
4、采用loglinear模型:theta*fi
对于第一个参数,其仅和特征函数1(f1)有关,求导后发现,第一项是数据集特征统计(数据集特征函数期望);第二项是在该theta下,数据集对应label = green的概率乘以绿强度。很好理解1函数的模型期望就是概率。
2、CRF与MRF对比
1、CRF在训练时,针对每组数据都需要计算E based on model,MRF的E based on model 和单个数据集无关
2、CRF在使用时,针对给定x仅需要计算P(Y|x);MRF计算P(YX),在计算时需要对XY都进行边缘化。
3、MRF与CRF的先验
先验指的是对其参数分布的估计。在贝耶斯多项分布估计中,如果对参数先作出狄利克雷假设,则后续的后验分布也是狄利克雷的。把这个思想移植到MRF与CRF可以对其学习过程的性质进行改善。
关于参数的先验有两种,分别是拉普拉斯先验和高斯先验。
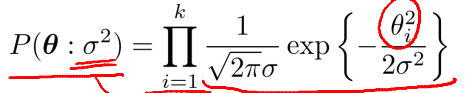
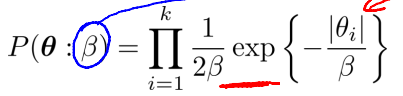
其中,delta和beta的作用类似,是分布中的方差。其决定了theta距离0的位置。也就是说该权重的重要程度。而加上先验分布可以带来更好的收敛性。
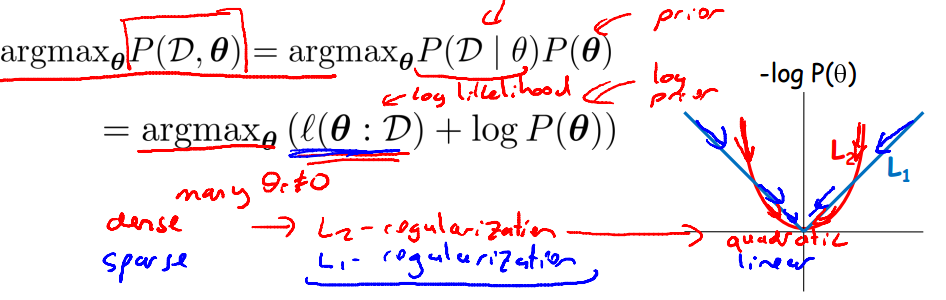
如图所示,log函数相当于是一个regularity.在theta被训练集改变的时候,给其一个趋于0的趋势。
1、拉普拉斯先验是L1 - regularization, 其有更强的趋势将数据拉向0, 所以利用拉普拉斯先验得到参数会更加稀疏,参数的稀疏性代表fi函数没什么用。换言之,图中连接label和x的边无关紧要,可以去除。
2、高斯先验相当于L2 - regularization. 也可以用于对抗过拟合。
机器学习 —— 概率图模型(学习:CRF与MRF)的更多相关文章
- 概率图模型学习笔记:HMM、MEMM、CRF
作者:Scofield链接:https://www.zhihu.com/question/35866596/answer/236886066来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商 ...
- 机器学习 —— 概率图模型(Homework: CRF Learning)
概率图模型的作业越往后变得越来越有趣了.当然,难度也是指数级别的上涨啊,以至于我用了两个周末才完成秋名山神秘车牌的寻找,啊不,CRF模型的训练. 条件随机场是一种强大的PGM,其可以对各种特征进行建模 ...
- 机器学习 —— 概率图模型(Homework: MCMC)
除了精确推理之外,我们还有非精确推理的手段来对概率图单个变量的分布进行求解.在很多情况下,概率图无法简化成团树,或者简化成团树后单个团中随机变量数目较多,会导致团树标定的效率低下.以图像分割为例,如果 ...
- 机器学习 —— 概率图模型(Homework: Structure Learning)
概率图的学习真的要接近尾声了啊,了解的越多越发感受到它的强大.这周的作业本质上是data mining.从数据中学习PGM的结构和参数,完全使用数据驱动 —— No structure, No par ...
- 机器学习 —— 概率图模型(Homework: Exact Inference)
在前三周的作业中,我构造了概率图模型并调用第三方的求解器对器进行了求解,最终获得了每个随机变量的分布(有向图),最大后验分布(双向图).本周作业的主要内容就是自行编写概率图模型的求解器.实际上,从根本 ...
- 机器学习 —— 概率图模型(Homework: Representation)
前两周的作业主要是关于Factor以及有向图的构造,但是概率图模型中还有一种更强大的武器——双向图(无向图.Markov Network).与有向图不同,双向图可以描述两个var之间相互作用以及联系. ...
- 机器学习 —— 概率图模型(Homework: StructuredCPD)
Week2的作业主要是关于概率图模型的构造,主要任务可以分为两个部分:1.构造CPD;2.构造Graph.对于有向图而言,在获得单个节点的CPD之后就可依据图对Combine CPD进行构造.在获得C ...
- 机器学习 —— 概率图模型(Homework: Factors)
Talk is cheap, I show you the code 第一章的作业主要是关于PGM的因子操作.实际上,因子是整个概率图的核心.对于有向图而言,因子对应的是CPD(条件分布):对无向图而 ...
- 机器学习 —— 概率图模型(CPD)
CPD是conditional probability distribution的缩写,翻译成中文叫做 条件概率分布.在概率图中,条件概率分布是一个非常重要的概念.因为概率图研究的是随机变量之间的练习 ...
随机推荐
- Python开发【第一篇】Python基础之装饰器
写代码要遵循开发封闭原则,虽然在这个原则是用的面向对象开发,但是也适用于函数式编程,简单来说,它规定已经实现的功能代码不允许被修改,但可以被扩展,即: 封闭:已实现的功能代码块开放:对扩展开发 #s2 ...
- 《.NET简单企业应用》项目开发环境
项目开始,开发团队需要构建一套开发环境,主要包含:开发工具.代码管理/版本控制系统.任务和Bug管理系统和持续集成(CI)系统.本文主要列举项目开发中经常使用的开发工具和第三方库. 本文所列工具根据前 ...
- Redis 四:存储类型之无序集合
.sadd num a b c 向num集合中添加abc三个元素 .srem num b 从num集合中删除b元素 .smembers num 获取num集合中所有的元素 .sismember num ...
- 在IOS中使用json
1.从https://github.com/stig/json-framework/中下载json框架:json-framework 2.解压下载的包,将class文件夹下的所有文件导入到当前工程下. ...
- iPhone 6 & iPhone 6 Plus适配
转载请注明出处: http://www.cnblogs.com/dokaygang128/p/4049461.html Apple 今年发布了两款新的iPhone机器,iPhone 6 和iPhone ...
- CSS:在input、pre中左边加上一个图标(一行和多行)
前言 接触过EasyUI的朋友都知道其警告框就是左边有个三角警告图标,此文所做的效果正是这样.此外,还将示例多行的做法. 一.在input左边加上一个图标(一行) 注:left center定义了图标 ...
- 使用highcharts 绘制Web图表
问题描述: 使用highcharts 绘制Web图表 Highcharts说明: 问题解决: (1)安装Highcharts 在这些图表中,数据源是一个典型的JavaScrip ...
- 怎么让CentOS集群自动同步时间
怎么让CentOS集群自动同步时间?首先机器要连外网,这样才能从互联网上同步时间,这是首先要了解的.好了,主要的方法如下: 在除了运行ntpd之外的机器上,执行: [html] # chkconfig ...
- Kafka的消息格式
Commit Log Kafka储存消息的文件被它叫做log,按照Kafka文档的说法是: Each partition is an ordered, immutable sequence of me ...
- Ignore files which are already versioned
If you accidentally added some files which should have been ignored, how do you get them out of vers ...