CMU Database Systems - Two-phase Locking
首先锁是用来做互斥的,解决并发执行时的数据不一致问题
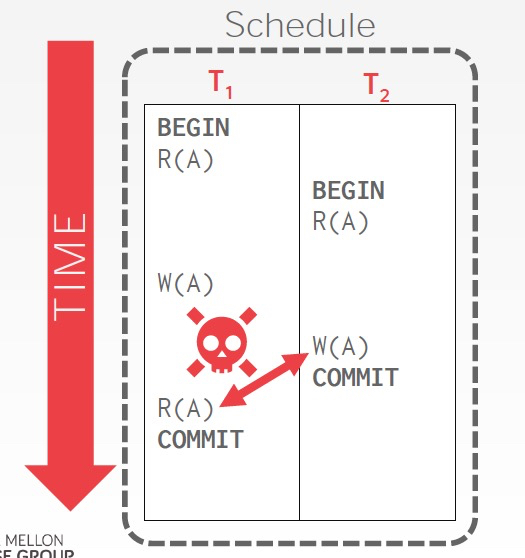
如图会导致,不可重复读
如果这里用lock就可以解决,数据库里面有个LockManager来作为master,负责锁的记录和授权

数据库里面的基本的锁类型,
其实就是读锁,写锁

但是如果光是有读写锁,只能解决当个操作互斥和正确,无法解决transaction的正确
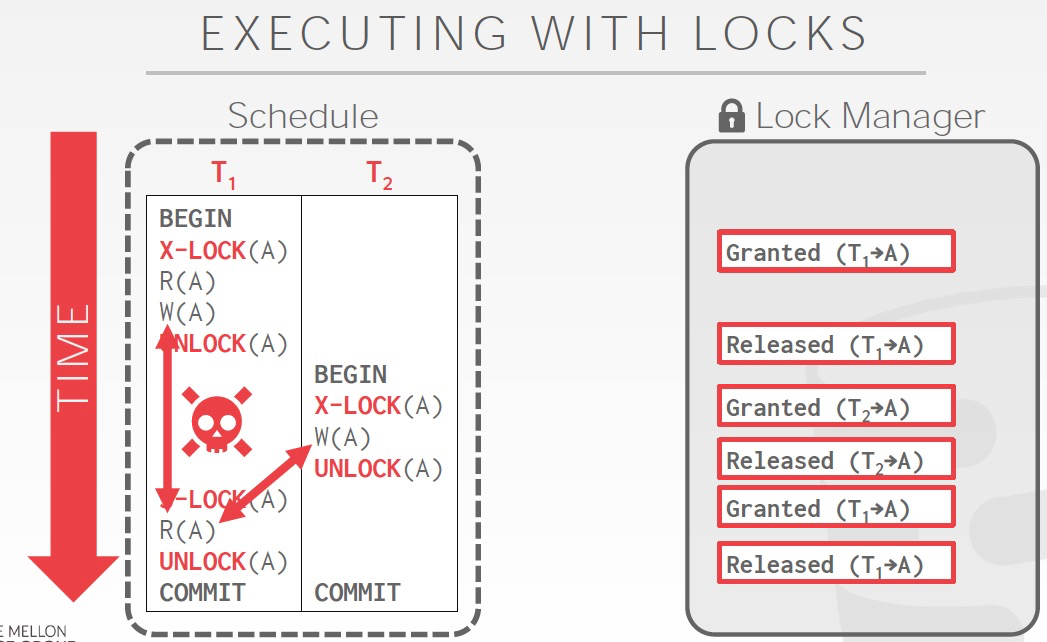
所以我们需要一个事务级别的锁,就是2PL,两阶段提交
最核心的想法,在growing阶段需要拿到所有需要的锁,否则就会block;shrinking阶段,不能去增加锁,只能释放锁


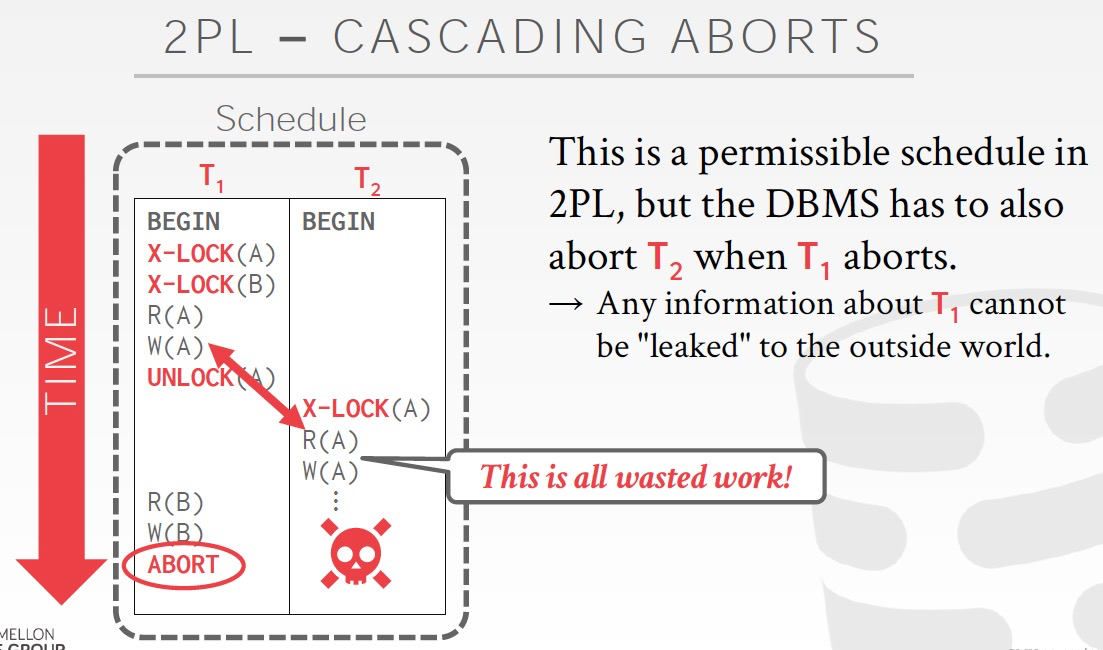
2PL在shrinking阶段是可以逐个去释放锁的,这样会有cascding aborts问题
因为你释放部分锁的时候,其他的事务就会看到你的改动,但最终你abort,那么所有相关的事务由于脏读也必须要abort
2PL有如下的问题,
首先,2PL是充分不必要条件,不满足2PL并不一定会导致调度问题,所以2PL限制了并发
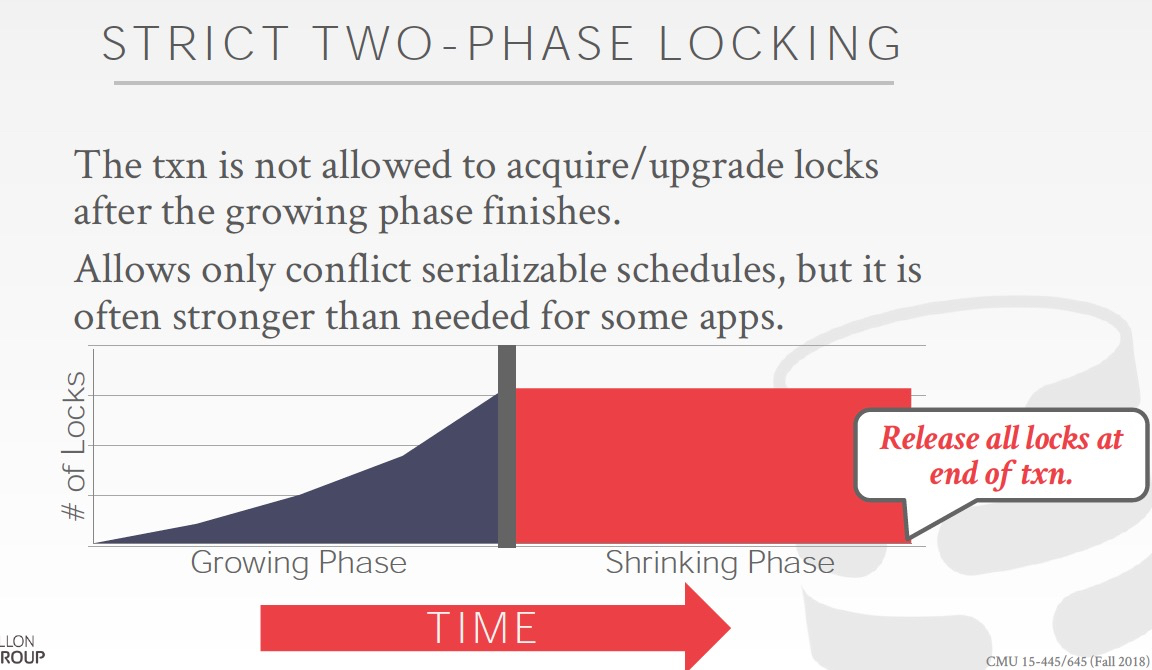
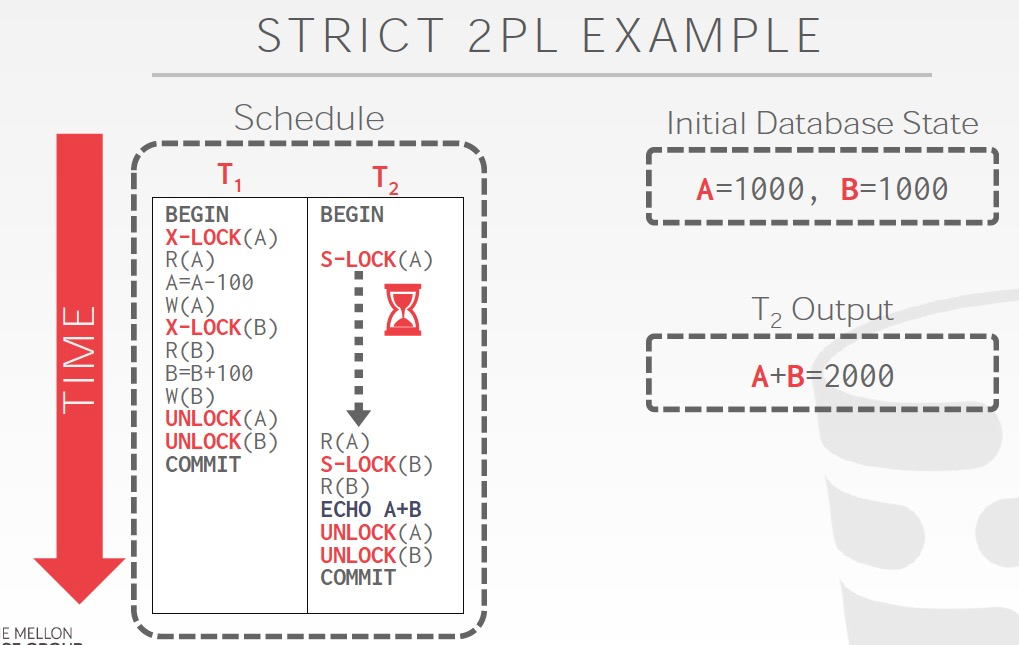
第二,由于脏读导致的Cascding abort,这个的解决很直接,Strict 2PL,Shrinking阶段不会逐步释放锁,最后一起释放,这样就不会脏读了,这个方法会进一步限制并发,谈不上优雅

下面看一组例子,
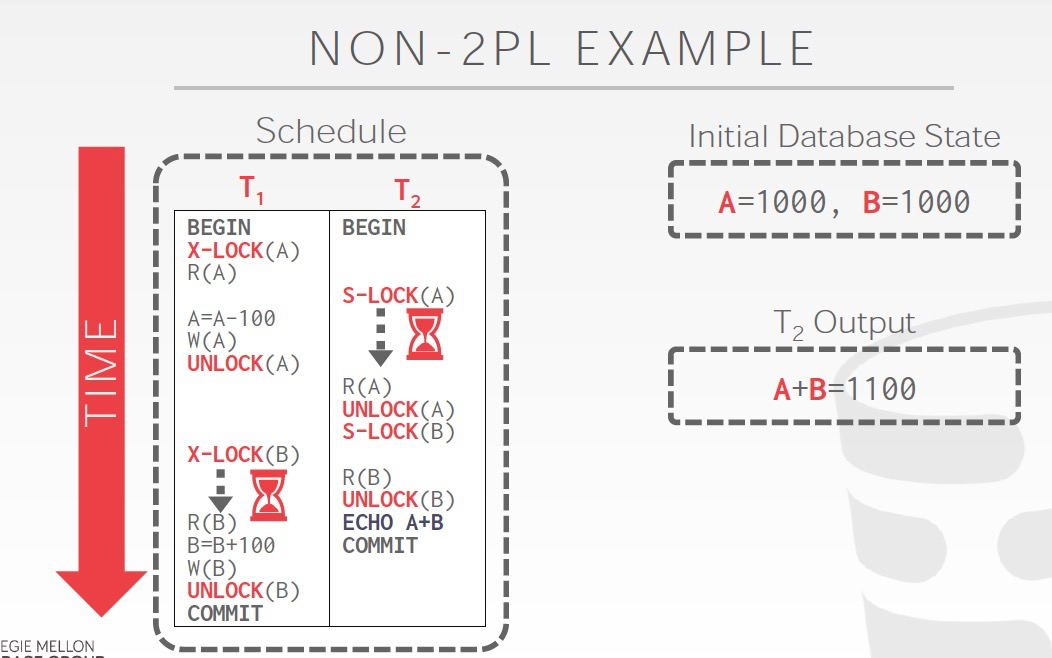
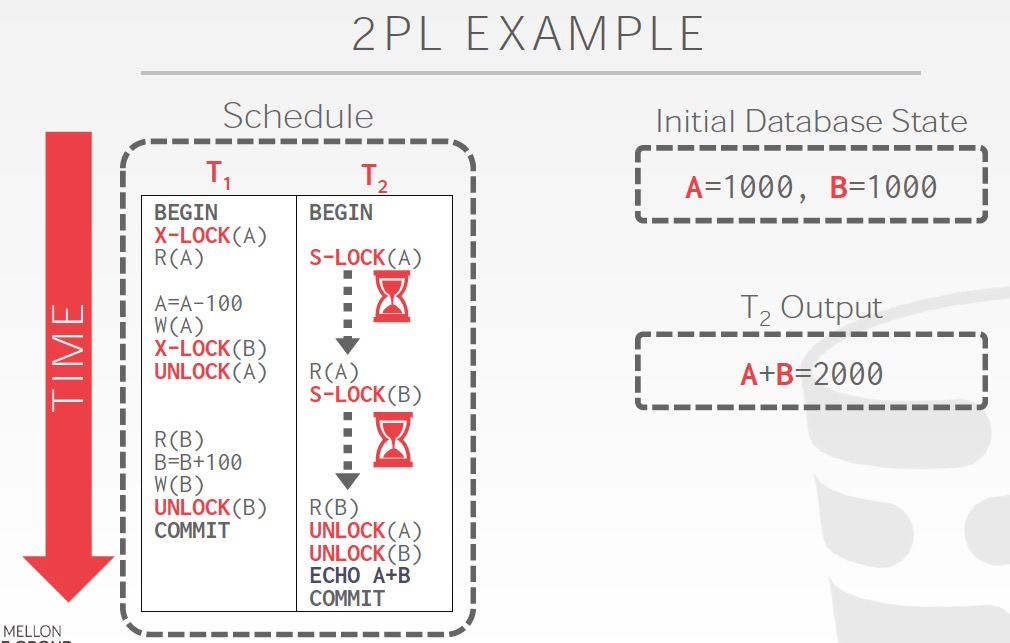
非2PL,读到的是A,B的中间结果,所以会发生不一致;2PL,解决了不一致问题;Strict 2PL,明显进一步限制了并发,几乎就是顺序执行
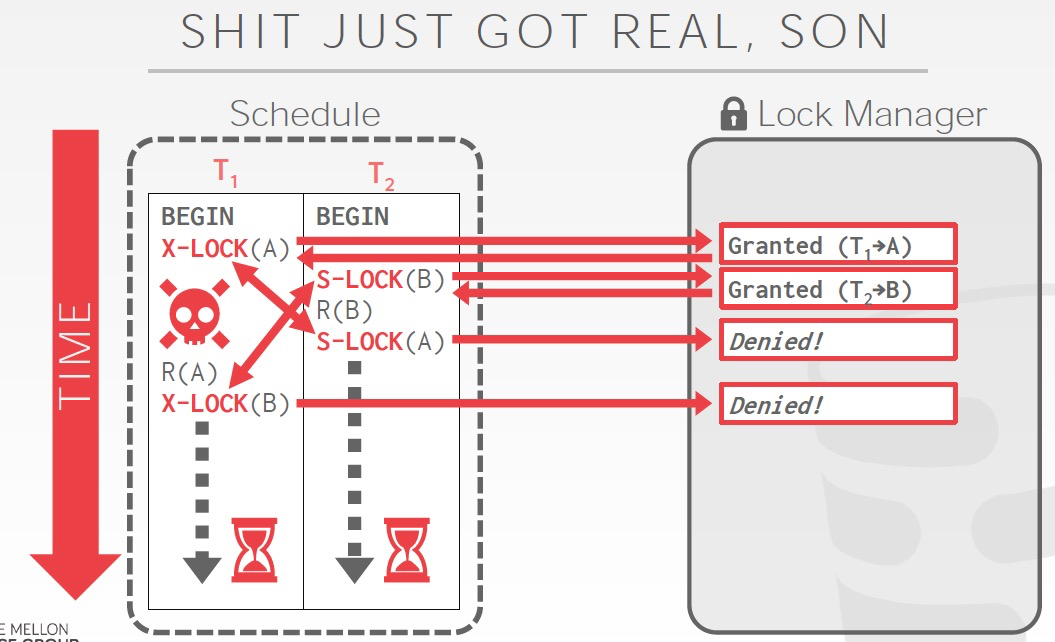
事务还有一个问题,死锁
死锁就是发生锁环了,两种解决方法,
Detection和Prevention,detection就是检测有没有环,如果有环就处理;Prevention就是预先判断是不是会形成环,如果会就拒绝请求
死锁Detection,生成waits-for图,如果有环,就说明有死锁

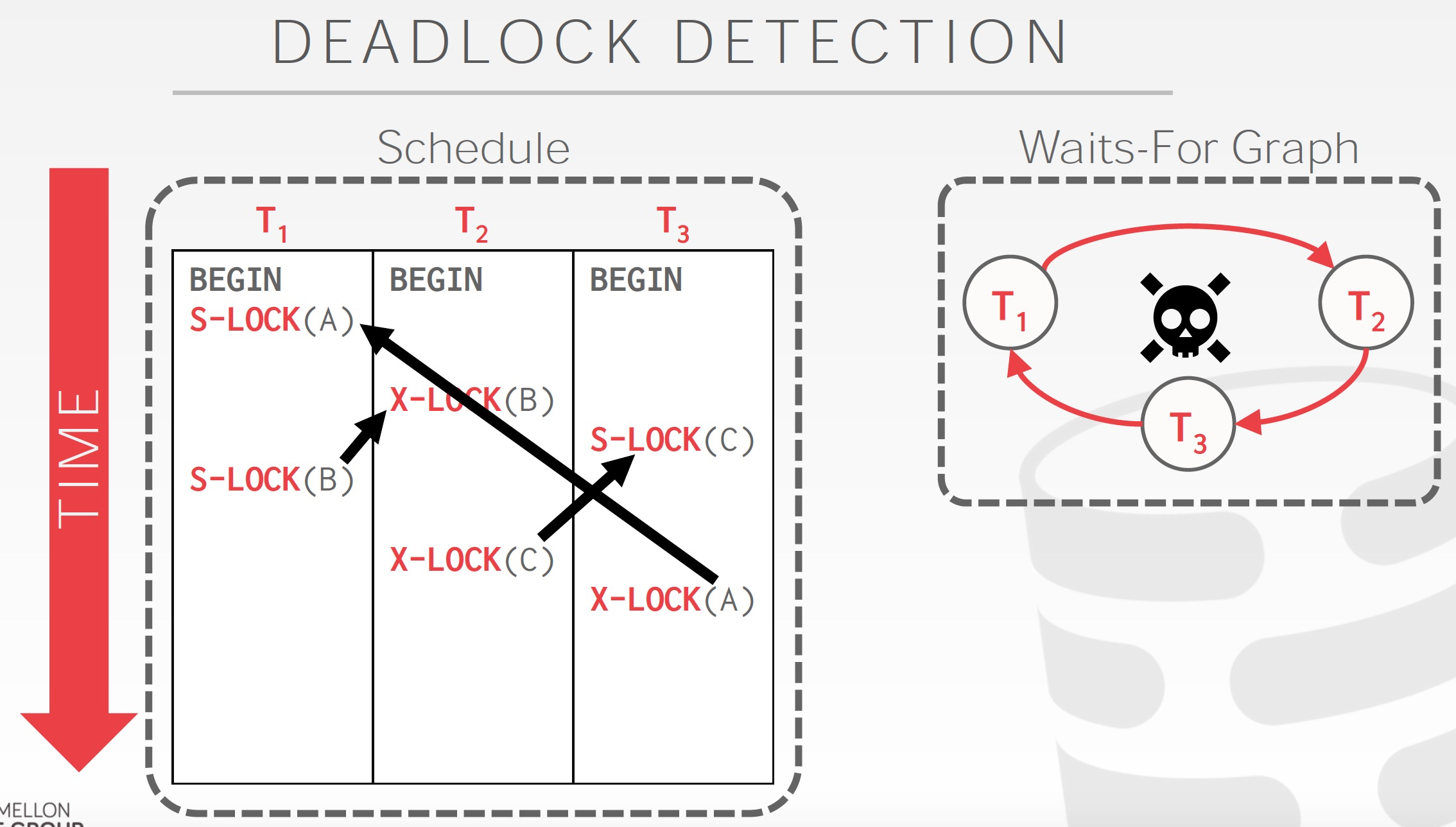
出现死锁,解决从策略就是挑一个进行重启或abort
挑选的策略就是代价更低,然后挑出合适的victim后,就是要进行处理
处理的时候,可以分为完全Rollback和部分Rollback,因为有时候Rollback到不持有这锁就可以解决死锁的问题,不用完全的rollback


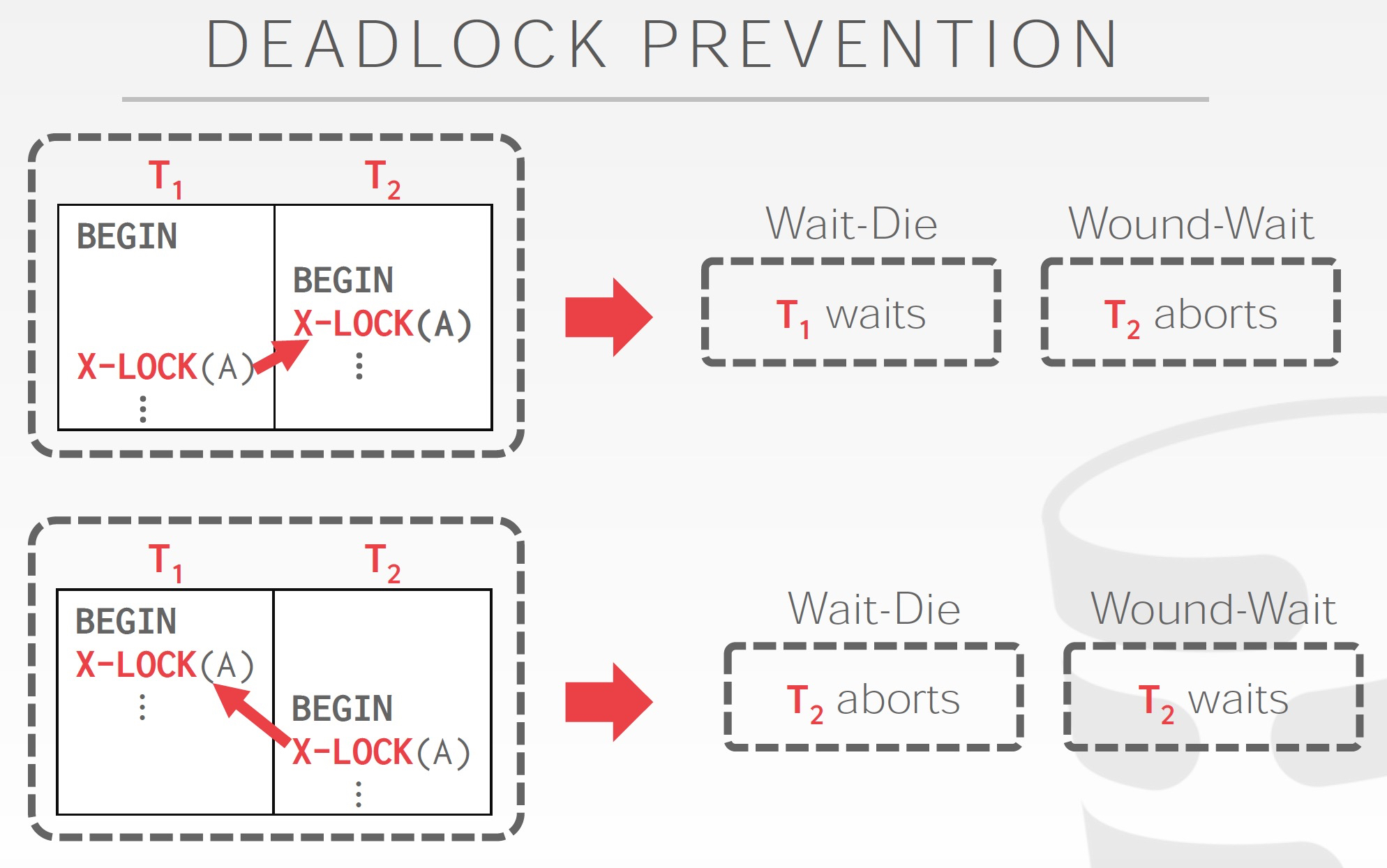
prevention的策略如下,prevention的依据就是时间,要不新的等,要不老的等

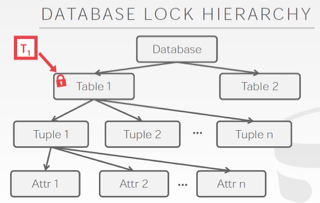
锁粒度
对数据库加锁可以在各个粒度上,
在树上任一节点加锁,意味着对所有子节点也持有锁
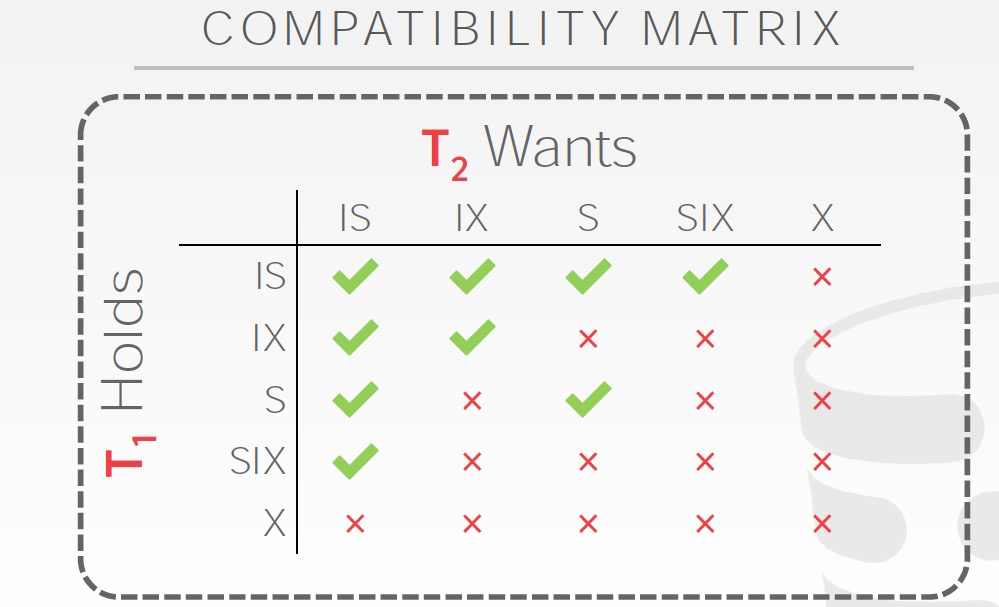
意向锁,intention lock
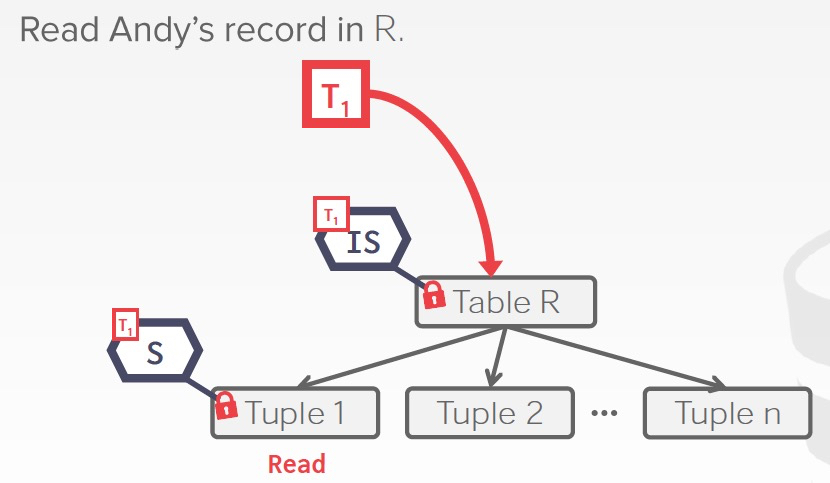
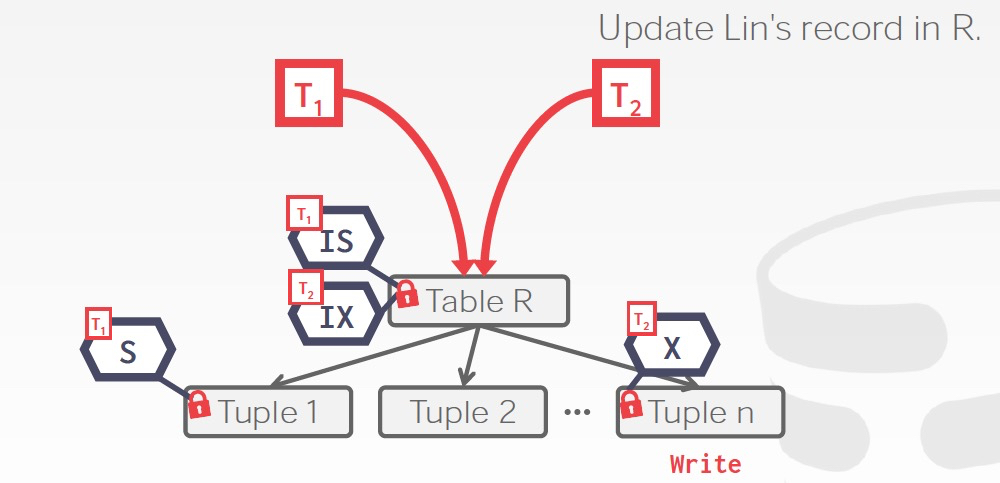
比如你在要给table加锁的时候,你先要确认table底下的所有tuple,attr是否有锁,这样很低效
所以意向锁就是一个flag,标识子节点上是否有锁
意向锁分为几类,
读写意向锁,很好理解,就是表示子节点是否有读写锁
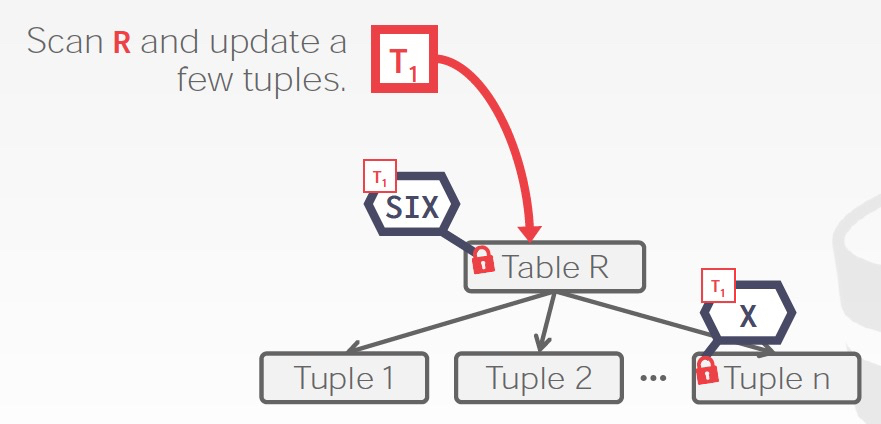
SIX,Shared Intention Exclusive,首先加Shared锁,这样可以扫描全表,然后加IX锁,需要更改其中某些tuple


例子,
CMU Database Systems - Two-phase Locking的更多相关文章
- CMU Database Systems - Timestamp Ordering Concurrency Control
2PL是悲观锁,Pessimistic,这章讲乐观锁,Optimistic,单机的,非分布式的 Timestamp Ordering,以时间为序,这个是非常自然的想法,按每个transaction的时 ...
- CMU Database Systems - Database Recovery
数据库数据丢失的典型场景如下, 数据commit后,还没有来得及flush到disk,这时候crash就会丢失数据 当然这只是fail的一种情况,DataBase Recovery要讨论的是,在各种f ...
- CMU Database Systems - Concurrency Control Theory
并发控制是数据库理论里面最难的课题之一 并发控制首先了解一下事务,transaction 定义如下, 其实transaction关键是,要满足ACID属性, 左边的正式的定义,由于的intuitive ...
- CMU Database Systems - Storage and BufferPool
Database Storage 存储分为volatile和non-volatile,越快的越贵越小 那么所以要解决的第一个问题就是,如果尽量在有限的成本下,让读写更快些 意思就是,尽量读写volat ...
- CMU Database Systems - Distributed OLTP & OLAP
OLTP scale-up和scale-out scale-up会有上限,无法不断up,而且相对而言,up升级会比较麻烦,所以大数据,云计算需要scale-out scale-out,就是分布式数据库 ...
- CMU Database Systems - MVCC
MVCC是一种用空间来换取更高的并发度的技术 对同一个对象不去update,而且记录下每一次的不同版本的值 存在不会消失,新值并不能抹杀原先的存在 所以update操作并不是对世界的真实反映,这是一种 ...
- CMU Database Systems - Embedded Database Logic
正常应用和数据库交互的过程是这样的, 其实我们也可以把部分应用逻辑放到DB端去执行,来提升效率 User-defined Function Stored Procedures Triggers Cha ...
- CMU Database Systems - Parallel Execution
并发执行,主要为了增大吞吐,降低延迟,提高数据库的可用性 先区分一组概念,parallel和distributed的区别 总的来说,parallel是指在物理上很近的节点,比如本机的多个线程或进程,不 ...
- CMU Database Systems - Query Optimization
查询优化应该是数据库领域最难的topic 当前查询优化,主要有两种思路, Rules-based,基于先验知识,用if-else把优化逻辑写死 Cost-based,试图去评估各个查询计划的cost, ...
随机推荐
- Linux进程间通信 共享内存+信号量+简单样例
每个进程都有着自己独立的地址空间,比方程序之前申请了一块内存.当调用fork函数之后.父进程和子进程所使用的是不同的内存. 因此进程间的通信,不像线程间通信那么简单.可是共享内存编程接口能够让一个进程 ...
- swift 笔记 (二十一) —— 高级运算符
高级运算符 位运算符 按位取反: ~ 按位与运算: & 按位或运算: | 按位异或运算: ^ 按位左移运算: << 按位右移动算: >> 溢出运算符 自从swif ...
- 内容原发网站seo不重视2个标签,导致seo效果不如转发网站
采集数据,挖掘观点,小心求证,得出结论 时间经过 今日凌晨,爬虫热点采集,其中第一财经是目标站之一,采集到了 http://www.yicai.com/news/5391233.html 谷歌去年悄然 ...
- 【BZOJ 5165】 树上倍增
[题目链接] 点击打开链接 [算法] 树上倍增,时间复杂度 : O(qklog(n)) [代码] #include<bits/stdc++.h> using namespace std; ...
- python-----删除空文件夹
问题描述: 有时,我们的文件夹太多了,但有的文件夹还是空的文件夹,自己去删需要好久,于是想着写个脚本自动删除.代码如下: #!/usr/bin/env python # -*- coding: utf ...
- 杂项-DB:Druid
ylbtech-杂项-DB:Druid Apache Druid (incubating) is a high performance analytics data store for event-d ...
- P4196 [CQOI2006]凸多边形
传送门 半平面交的讲解 然而这个代码真的是非常的迷--并不怎么看得懂-- //minamoto #include<bits/stdc++.h> #define fp(i,a,b) for( ...
- redis在linux的安装和开机启动(二)
编译 安装 makefile已经存在 执行make 即可 make之后, 自动创建可运行的脚本文件, 不需要再执行 install了. 将脚本文件, 拷贝到指定位置, 就可以了. 手动创建目录, 需要 ...
- 【NOI2012】魔幻棋盘
Description 将要读二年级的小 Q 买了一款新型益智玩具——魔幻棋盘,它是一个N行M列的网格棋盘,每个格子中均有一个正整数.棋盘守护者在棋盘的第X行Y列(行与列均从1开始编号) 并且始终不会 ...
- 多维DP UVA 11552 Fewest Flop
题目传送门 /* 题意:将子符串分成k组,每组的字符顺序任意,问改变后的字符串最少有多少块 三维DP:可以知道,每一组的最少块是确定的,问题就在于组与组之间可能会合并块,总块数会-1. dp[i][j ...