IMDB电影排行爬取分析
一.打开IMDB电影T250排行可以看见250条电影数据,电影名,评分等数据都可以看见
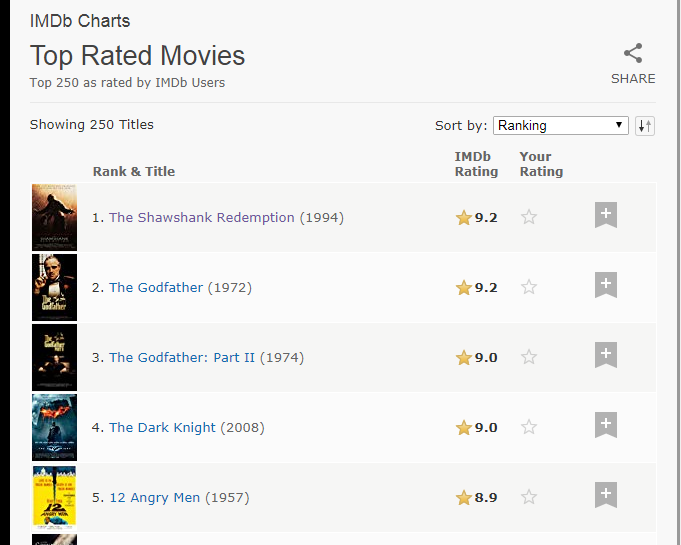
按F12进入开发者模式,找到这些数据对应的HTML网页结构,如下所示
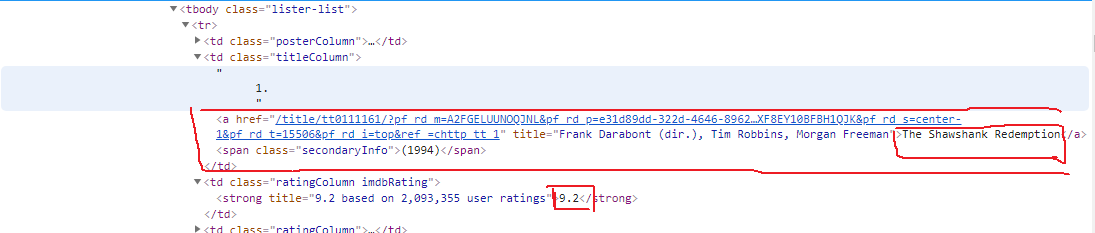
可以看见里面有链接,点击链接可以进入电影详情页面,这可以看见导演,编剧,演员信息

同样查看HTML结构,可以找到相关信息的节点位置

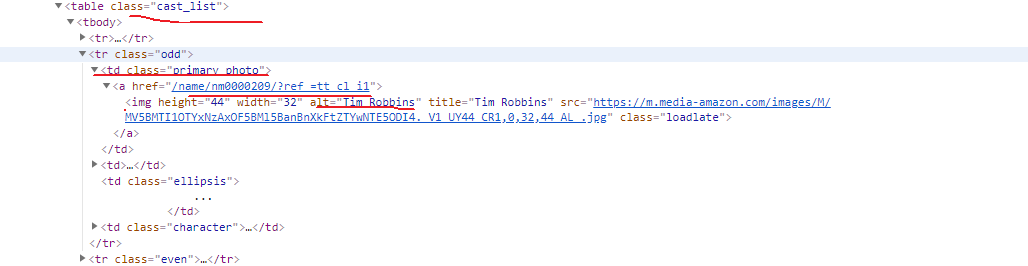
演员信息可以在这个页面的cast中查看完整的信息

HTML页面结构
分析完整个要爬取的数据,现在来获取首页250条电影信息
1.整个爬虫代码需要使用的相关库
import re
import pymysql
import json
import requests
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
2.请求首页的HTML网页,(如果请求不通过可以添加相关Header),返回网页内容
def get_html(url):
response=requests.get(url)
if response.status_code==200:
#判断请求是否成功
return response.text
else:
return None
3.解析HTML
def parse_html(html):
#进行页面数据提取
soup = BeautifulSoup(html, 'lxml')
movies = soup.select('tbody tr')
for movie in movies:
poster = movie.select_one('.posterColumn')
score = poster.select_one('span[name="ir"]')['data-value']
movie_link = movie.select_one('.titleColumn').select_one('a')['href']
#电影详情链接
year_str = movie.select_one('.titleColumn').select_one('span').get_text()
year_pattern = re.compile('\d{4}')
year = int(year_pattern.search(year_str).group())
id_pattern = re.compile(r'(?<=tt)\d+(?=/?)')
movie_id = int(id_pattern.search(movie_link).group())
#movie_id不使用默认生成的,从数据提取唯一的ID
movie_name = movie.select_one('.titleColumn').select_one('a').string
#使用yield生成器,生成每一条电影信息
yield {
'movie_id': movie_id,
'movie_name': movie_name,
'year': year,
'movie_link': movie_link,
'movie_rate': float(score)
}
4.我们可以保存文件到txt文本
def write_file(content):
with open('movie12.txt','a',encoding='utf-8')as f:
f.write(json.dumps(content,ensure_ascii=False)+'\n') def main():
url='https://www.imdb.com/chart/top'
html=get_html(url)
for item in parse_html(html):
write_file(item) if __name__ == '__main__':
main()
5.数据可以看见

6.如果成功了,可以修改代码保存数据到MySQL,使用Navicat来操作非常方便先连接到MySQL
db = pymysql.connect(host="localhost", user="root", password="********", db="imdb_movie")
cursor = db.cursor()
创建数据表
CREATE TABLE `top_250_movies` (
`id` int(11) NOT NULL,
`name` varchar(45) NOT NULL,
`year` int(11) DEFAULT NULL,
`rate` float NOT NULL,
PRIMARY KEY (`id`)
)
接下来修改代码,操作数据加入数据表
def store_movie_data_to_db(movie_data):
sel_sql = "SELECT * FROM top_250_movies \
WHERE id = %d" % (movie_data['movie_id'])
try:
cursor.execute(sel_sql)
result = cursor.fetchall()
except:
print("Failed to fetch data")
if result.__len__() == 0:
sql = "INSERT INTO top_250_movies \
(id, name, year, rate) \
VALUES ('%d', '%s', '%d', '%f')" % \
(movie_data['movie_id'], movie_data['movie_name'], movie_data['year'], movie_data['movie_rate'])
try:
cursor.execute(sql)
db.commit()
print("movie data ADDED to DB table top_250_movies!")
except:
# 发生错误时回滚
db.rollback()
else:
print("This movie ALREADY EXISTED!!!")
运行
def main():
url='https://www.imdb.com/chart/top'
html=get_html(url)
for item in parse_html(html):
store_movie_data_to_db(item) if __name__ == '__main__':
main()
查看Navicat,可以看到保存到mysql的数据。
IMDB电影排行爬取分析的更多相关文章
- 豆瓣电影信息爬取(json)
豆瓣电影信息爬取(json) # a = "hello world" # 字符串数据类型# b = {"name":"python"} # ...
- scrapy-redis实现爬虫分布式爬取分析与实现
本文链接:http://blog.csdn.net/u012150179/article/details/38091411 一 scrapy-redis实现分布式爬取分析 所谓的scrapy-redi ...
- Scrapy项目 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
通过使Scrapy框架,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,进行数据挖掘和对web站点页面提取结构化数据,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求 ...
- 用Python爬取分析【某东618】畅销商品销量数据,带你看看大家都喜欢买什么!
618购物节,辰哥准备分析一波购物节大家都喜欢买什么?本文以某东为例,Python爬取618活动的畅销商品数据,并进行数据清洗,最后以可视化的方式从不同角度去了解畅销商品中,名列前茅的商品是哪些?销售 ...
- Python 从底层结构聊 Beautiful Soup 4(内置豆瓣最新电影排行榜爬取案例)
1. 前言 什么是 Beautiful Soup 4 ? Beautiful Soup 4(简称 BS4,后面的 4 表示最新版本)是一个 Python 第三方库,具有解析 HTML 页面的功能,爬虫 ...
- python 豆瓣top250电影的爬取
我们先看一下豆瓣的robot.txt 然后我们查看top250的网页链接和源代码 通过对比不难发现网页间只是start数字发生了变化. 我们可以知道电影内容都存在ol标签下的 div class属性为 ...
- 豆瓣电影top250爬取并保存在MongoDB里
首先回顾一下MongoDB的基本操作: 数据库,集合,文档 db,show dbs,use 数据库名,drop 数据库 db.集合名.insert({}) db.集合名.update({条件},{$s ...
- Python爬虫+可视化教学:爬取分析宠物猫咪交易数据
前言 各位,七夕快到了,想好要送什么礼物了吗? 昨天有朋友私信我,问我能用Python分析下网上小猫咪的数据,是想要送一只给女朋友,当做礼物. Python从零基础入门到实战系统教程.源码.视频 网上 ...
- Scrapy项目 - 数据简析 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
一.数据分析截图(weka数据分析截图 ) 本例实验,使用Weka 3.7对豆瓣电影网页上所罗列的上映电影信息,如:标题.主要信息(年份.国家.类型)和评分等的信息进行数据分析,Weka 3.7数据分 ...
随机推荐
- Android多媒体-MediaPlayer唤醒锁及音频焦点
MediaPlayer的唤醒锁 一般使用MediaPlayer播放音频流,推荐使用一个Service来承载MediaPlayer,而不是直接在Activity里使用.可是Android系统的功耗设计里 ...
- 约瑟夫环问题(Josephus)
约瑟夫环:用户输入M,N值,从1至N开始顺序循环数数,每数到M输出该数值,直至最后一个元素并输出该元素的值. 一.循环链表:建立一个有N个元素的循环链表,然后从链表头开始遍历并记数,如果计数值为M,则 ...
- 数据结构 - 希尔排序(Shell's Sort) 具体解释 及 代码(C++)
数据结构 - 希尔排序(Shell's Sort) 具体解释 及 代码(C++) 本文地址: http://blog.csdn.net/caroline_wendy/article/details/2 ...
- Ubuntu 16.04下安装MacBuntu 16.04 TP 变身Mac OS X主题风格
Ubuntu 16.04下安装MacBuntu 16.04 TP 变身Mac OS X主题风格 sudo add-apt-repository ppa:noobslab/macbuntu sudo a ...
- SepicalJudge
原文:http://www.cnblogs.com/chouti/p/5752819.html Special Judge:当正确的输出结果不唯一的时候需要的自定义校验器 首先有个框架 #includ ...
- memcached知识点梳理
Memcached概念: Memcached是一个免费开源的,高性能的,具有分布式对象的缓存系统,它可以用来保存一些经常存取的对象或数据,保存的数据像一张巨大的HASH表,该表以Key-valu ...
- 使Android 自带SDK 完美支持HTML5 之 html5webview
HTML5出来之后,webkit 大部分都支持了,但是由于历史原因,支持限度有限,我在Android 4.0使用 hao123的客户端访问youxi.cn期望可以万网手机HTML5游戏但是有些失望,进 ...
- [Codeforces 623A] Graph and String
[题目链接] http://codeforces.com/contest/623/problem/A [算法] 首先 , 所有与其他节点都有连边的节点需标号为'b' 然后 , 我们任选一个节点 , 将 ...
- 关于Dubbo中一些小众但很实用的功能
dubbo功能非常完善,很多时候我们不需要重复造轮子,下面列举一些你不一定知道,但是很好用的功能: 直连Provider 在开发及测试环境下,可能需要绕过注册中心,只测试指定服务提供者,这时候可能需要 ...
- 洛谷 P1966 火柴排队 —— 思路
题目:https://www.luogu.org/problemnew/show/P1966 首先,一个排列相邻交换变成另一个排列的交换次数就是逆序对数: 随便画一画,感觉应该是排个序,大的对应大的, ...