Apache Spark源码走读之5 -- DStream处理的容错性分析
欢迎转载,转载请注明出处,徽沪一郎,谢谢。
在流数据的处理过程中,为了保证处理结果的可信度(不能多算,也不能漏算),需要做到对所有的输入数据有且仅有一次处理。在Spark Streaming的处理机制中,不能多算,比较容易理解。那么它又是如何作到即使数据处理结点被重启,在重启之后这些数据也会被再次处理呢?
环境搭建
为了有一个感性的认识,先运行一下简单的Spark Streaming示例。首先确认已经安装了openbsd-netcat。
运行netcat
nc -lk 9999
运行spark-shell
SPARK_JAVA_OPTS=-Dspark.cleaner.ttl=10000 MASTER=local-cluster[2,2,1024] bin/spark-shell
在spark-shell中输入如下内容
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
val ssc = new StreamingContext(sc, Seconds(3))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap( _.split(" "))
val pairs = words.map(word => (word,1))
val wordCount = pairs.reduceByKey(_ + _)
wordCount.print()
ssc.start()
ssc.awaitTermination()
当ssc.start()执行之后,在nc一侧输入一些内容并回车,spark-shell上就会显示出统计的结果。
数据接收过程
来看一下代码实现层面,从两个角度来说,一是控制层面(control panel),另一是数据层面(data panel)。
Spark Streaming的数据接收过程的控制层面大致如下图所示。
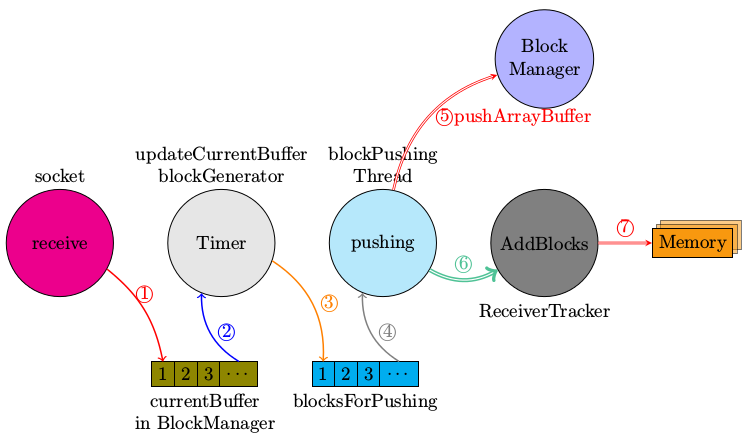
简要讲解一下上图的意思,
- 数据真正接收到是发生在SocketReceiver.receive函数中,将接收到的数据放入到BlockGenerator.currentBuffer
- 在BlockGenerator中有一个重复定时器,处理函数为updateCurrentBuffer, updateCurrentBuffer将当前buffer中的数据封装为一个新的Block,放入到blocksForPush队列中
- 同样是在BlockGenerator中有一个BlockPushingThread,其职责就是不停的将blocksForPush队列中的成员通过pushArrayBuffer函数传递给blockmanager,让BlockManager将数据存储到MemoryStore中
- pushArrayBuffer还会将已经由BlockManager存储的Block的id号传递给ReceiverTracker,ReceiverTracker会将存储的blockId放到对应StreamId的队列中
socket.receive->receiver.store->pushSingle->blockgenerator.updateCurrentBuffer->blockgenerator.keepPushBlocks->pushArrayBufer
->ReceiverTracker.addBlocks
pushArrayBuffer函数的定义如下
def pushArrayBuffer(
arrayBuffer: ArrayBuffer[_],
optionalMetadata: Option[Any],
optionalBlockId: Option[StreamBlockId]
) {
val blockId = optionalBlockId.getOrElse(nextBlockId)
val time = System.currentTimeMillis
blockManager.put(blockId, arrayBuffer.asInstanceOf[ArrayBuffer[Any]],
storageLevel, tellMaster = true)
logDebug("Pushed block " + blockId + " in " + (System.currentTimeMillis - time) + " ms")
reportPushedBlock(blockId, arrayBuffer.size, optionalMetadata)
}
数据结构的变化过程
Spark Streaming数据处理高效的原因之一就是批量的进行数据分析,那么这些批量的数据是如何聚集起来的呢?换种方式来表述这个问题,在某一时刻,接收到的数据是单一的,也就是我们最多只能组成<t,data>这种数据元组,而在runJob的时候是批量的提取和分析数据的,这个批量数据的组成是在什么时候完成的呢?
下图大到勾勒出一条新的message被socketreceiver接收之后,是如何通过一系列的处理而放入到BlockManager中,并同时由ReceiverTracker记录下相应的元数据的。
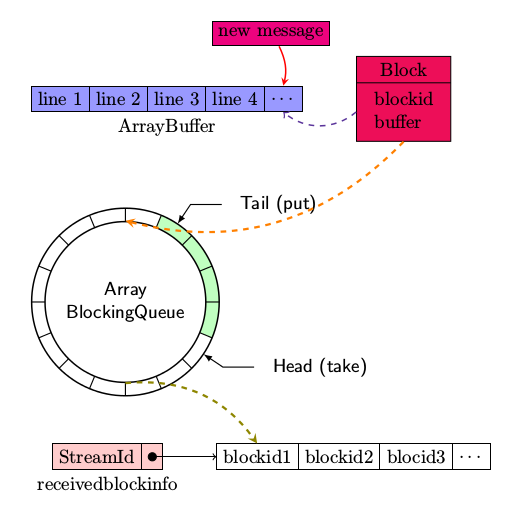
- 首先new message被放入到blockManager.currentBuffer
- 定时器超时处理过程,将整个currentBuffer中的数据打包成一条Block,放入到ArrayBlockingQueue,该数据结构支持FIFO
- keepPushingBlocks将每一条Block(block中包含时间戳,接收到的原始数据)让BlockManager进行保存,同时通知ReceiverTracker已经将哪些block存储到了blockmanager中
- ReceiverTracker将每一个stream接收到但还没有进行处理的block放入到receiverBlockInfo,其为一Hashmap. 在后面的generateJobs中会从receiverBlockInfo提取数据以生成相应的RDD
数据处理过程
数据处理中最重要的函数就是generateJobs, generateJobs会引发下述的函数调用过程,具体的代码就不一一罗列了。
- jobgenerator.generateJobs->dstreamgraph.generateJobs->dstream.generateJob->getOrCompute->compute 生成RDD
- job调用job.func
JobGenerator.generateJobs函数定义如下
private def generateJobs(time: Time) {
SparkEnv.set(ssc.env)
Try(graph.generateJobs(time)) match {
case Success(jobs) =>
val receivedBlockInfo = graph.getReceiverInputStreams.map { stream =>
val streamId = stream.id
val receivedBlockInfo = stream.getReceivedBlockInfo(time)
(streamId, receivedBlockInfo)
}.toMap
jobScheduler.submitJobSet(JobSet(time, jobs, receivedBlockInfo))
case Failure(e) =>
jobScheduler.reportError("Error generating jobs for time " + time, e)
}
eventActor ! DoCheckpoint(time)
}
我们先来谈一谈数据处理阶段是如何与上述的接收阶段中存储下来的数据挂上钩的。
假设上一次进行RDD处理发生在时间点t1,现在是时间点t2,那么在<t2,t1>之间有哪些blocks没有被处理呢?
想必你已经知道答案了,没有被处理的blocks全部保存在ReceiverTracker的receiverBlockInfo之中
在generateJob时,每一个DStream都会调用getReceivedBlockInfo,你说没有跟ReceiverTracker中的receivedBlockInfo连起来啊,别急!且看数据输入的源头ReceiverInputDStream中的getReceivedBlockInfo是如何定义的。代码列举如下。
private[streaming] def getReceivedBlockInfo(time: Time) = {
receivedBlockInfo(time)
}
那么此处的receivedBlockInfo(time)是从何而来的呢,这个要看ReceivedInputDStream中的compute函数实现
override def compute(validTime: Time): Option[RDD[T]] = {
// If this is called for any time before the start time of the context,
// then this returns an empty RDD. This may happen when recovering from a
// master failure
if (validTime >= graph.startTime) {
val blockInfo = ssc.scheduler.receiverTracker.getReceivedBlockInfo(id)
receivedBlockInfo(validTime) = blockInfo
val blockIds = blockInfo.map(_.blockId.asInstanceOf[BlockId])
Some(new BlockRDD[T](ssc.sc, blockIds))
} else {
Some(new BlockRDD[T](ssc.sc, Array[BlockId]()))
}
}
至此终于看到了receiverTracker中的getReceivedBlockInfo被调用,也就是说将接收阶段的数据和目前处理阶段的输入通道打通了
函数调用路径,从generateJobs到sparkcontext.submitJobs. 这个时候要注意注册为DStreamGraph中的OutputStream上的操作会引发SparkContext.runJobs被调用。我们以print函数为例看一下调用过程。
def print() {
def foreachFunc = (rdd: RDD[T], time: Time) => {
val first11 = rdd.take(11)
println ("-------------------------------------------")
println ("Time: " + time)
println ("-------------------------------------------")
first11.take(10).foreach(println)
if (first11.size > 10) println("...")
println()
}
new ForEachDStream(this, context.sparkContext.clean(foreachFunc)).register()
}
注意rdd.take,这个会引发runJob调用,不信的话,我们可以看一看其定义中调用runJob的片段。
val left = num - buf.size
val p = partsScanned until math.min(partsScanned + numPartsToTry, totalParts)
val res = sc.runJob(this, (it: Iterator[T]) => it.take(left).toArray, p, allowLocal = true)
res.foreach(buf ++= _.take(num - buf.size))
partsScanned += numPartsToTry
} 小结一下数据处理过程
- 用time为关键字去取出在此时间之前加入的所有blockIds
- 真正提交运行的时候,rdd中的blockfetcher以blockId为关键字去blockmanagermaster获取真正的数据,即从socket上接收到的原始数据
容错处理
JobGenerator.generateJobs函数的最后会发出DoCheckpoint通知,该通知会让相应的actor将DStreamCheckpointData写入到hdfs文件中,我们来看一看为什么需要写入checkpointdata以及哪些东西是包含在checkpointdata之中。

在数据处理一节,我们已经分析到在generateJobs的时候会生成多个jobs,它们会通过sparkcontext.runJob接口而发送到cluster中被真正执行。
假设在t2,worker挂掉了,挂掉的worker直到t3才完全恢复。由于挂掉的原因,上一次generateJobs生成的job不一定被完全处理了(也许有些已经处理了,有些还没有处理),所以需要重新再提交一次。这里有一个问题,那就是可能导致针对同一批数据有重复处理的情况发生,从而无法达到exactly-once的语义效果。
问题2: 在<t2,t3>这一段挂掉的时间之内,没有新的数据被接收,所以Spark Streaming的SocketReceiver适合用来充当client侧而不是server侧。SocketReceiver读取到的数据应该存在一个具有冗余备份机制的内存数据库或缓存队列里,如kafaka. 对问题2, Spark Streaming本身是解决不了的。当然这里再往下细究的话,会牵出负载均衡的问题。
checkpointData
checkpoint的成员变量有哪些呢,我们看一看其结构定义就清楚了。
val master = ssc.sc.master
val framework = ssc.sc.appName
val sparkHome = ssc.sc.getSparkHome.getOrElse(null)
val jars = ssc.sc.jars
val graph = ssc.graph
val checkpointDir = ssc.checkpointDir
val checkpointDuration = ssc.checkpointDuration
val pendingTimes = ssc.scheduler.getPendingTimes().toArray
val delaySeconds = MetadataCleaner.getDelaySeconds(ssc.conf)
val sparkConfPairs = ssc.conf.getAll
generatedRDDs是被包含在graph里面。所以不要突然之间惊惶失措,发觉没有将generatedRDDs保存起来。
checkpoint的数据是通过CheckpointwriteHandler真正的写入到hdfs,通过CheckPiontReader而读入。CheckpointReade在重启的时候会被使用到,判断是第一次干净的启动还是因错误而重启,判断的依据全部在cp这个变量。
为了达到重启之后而自动的检查并载入相应的checkpoint数据,那么在创建StreamingContext的时候就不能简单的通过调用new StreamingContext来完成,而是利用getOrCreate函数,代码示例如下。
// Function to create and setup a new StreamingContext
def functionToCreateContext(): StreamingContext = {
val ssc = new StreamingContext(...) // new context
val lines = ssc.socketTextStream(...) // create DStreams
...
ssc.checkpoint(checkpointDirectory) // set checkpoint directory
ssc
}
// Get StreaminContext from checkpoint data or create a new one
val context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _)
// Do additional setup on context that needs to be done,
// irrespective of whether it is being started or restarted
context. ...
// Start the context
context.start()
context.awaitTermination()
小结
本文中讲述数据接收过程中所使用的两幅图使用tikz完成,里面包含的信息很丰富,有志于了解清楚Spark Streaming内部处理机制的同仁,不妨以此为参考进行详细的代码走读。
如果有任何不对或错误之处,欢迎批评指正。
参考资料
- Spark Streaming源码分析 checkpoint http://www.cnblogs.com/fxjwind/p/3596451.html
- Spark Streaming Introduction http://jerryshao.me/architecture/2013/04/02/spark-streaming-introduction/
- deep dive with Spark Streaming http://www.meetup.com/spark-users/events/122694912/
Apache Spark源码走读之5 -- DStream处理的容错性分析的更多相关文章
- Apache Spark源码走读之4 -- DStream实时流数据处理
欢迎转载,转载请注明出处,徽沪一郎. Spark Streaming能够对流数据进行近乎实时的速度进行数据处理.采用了不同于一般的流式数据处理模型,该模型使得Spark Streaming有非常高的处 ...
- Apache Spark源码走读之7 -- Standalone部署方式分析
欢迎转载,转载请注明出处,徽沪一郎. 楔子 在Spark源码走读系列之2中曾经提到Spark能以Standalone的方式来运行cluster,但没有对Application的提交与具体运行流程做详细 ...
- Apache Spark源码走读之16 -- spark repl实现详解
欢迎转载,转载请注明出处,徽沪一郎. 概要 之所以对spark shell的内部实现产生兴趣全部缘于好奇代码的编译加载过程,scala是需要编译才能执行的语言,但提供的scala repl可以实现代码 ...
- Apache Spark源码走读之13 -- hiveql on spark实现详解
欢迎转载,转载请注明出处,徽沪一郎 概要 在新近发布的spark 1.0中新加了sql的模块,更为引人注意的是对hive中的hiveql也提供了良好的支持,作为一个源码分析控,了解一下spark是如何 ...
- Apache Spark源码走读之23 -- Spark MLLib中拟牛顿法L-BFGS的源码实现
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文就拟牛顿法L-BFGS的由来做一个简要的回顾,然后就其在spark mllib中的实现进行源码走读. 拟牛顿法 数学原理 代码实现 L-BFGS算法中使 ...
- Apache Spark源码走读之18 -- 使用Intellij idea调试Spark源码
欢迎转载,转载请注明出处,徽沪一郎. 概要 上篇博文讲述了如何通过修改源码来查看调用堆栈,尽管也很实用,但每修改一次都需要编译,花费的时间不少,效率不高,而且属于侵入性的修改,不优雅.本篇讲述如何使用 ...
- Apache Spark源码走读之6 -- 存储子系统分析
欢迎转载,转载请注明出处,徽沪一郎. 楔子 Spark计算速度远胜于Hadoop的原因之一就在于中间结果是缓存在内存而不是直接写入到disk,本文尝试分析Spark中存储子系统的构成,并以数据写入和数 ...
- Apache Spark源码走读之17 -- 如何进行代码跟读
欢迎转载,转载请注明出处,徽沪一郎 概要 今天不谈Spark中什么复杂的技术实现,只稍为聊聊如何进行代码跟读.众所周知,Spark使用scala进行开发,由于scala有众多的语法糖,很多时候代码跟着 ...
- Apache Spark源码走读之11 -- sql的解析与执行
欢迎转载,转载请注明出处,徽沪一郎. 概要 在即将发布的spark 1.0中有一个新增的功能,即对sql的支持,也就是说可以用sql来对数据进行查询,这对于DBA来说无疑是一大福音,因为以前的知识继续 ...
随机推荐
- input框颜色修该
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- java equals 和 "==" 比较
java中的数据类型,可分为两类: 1.基本数据类型,也称原始数据类型.byte,short,char,int,long,float,double,boolean 他们之间的比较,应用双等号(== ...
- centos 截图命令 screenshot
[root@ok ~]# gnome-screenshot#全屏截图 [root@ok ~]# gnome-screenshot --interactive#自定义截图
- Java vararg(动态参数)的应用
可变参数在JDK 1.5添加,刚才知道的. 以下来自<Java泛型和集合>一书. 将参数打包成一个数组传入方法中是一件让人讨厌的事,在jdk1.5中加入了一个新的功能称为vararg(动态 ...
- Linux查看硬件配置信息
转自:http://blog.163.com/yang_jianli/blog/static/1619900062010391127338/ 一:查看cpu more /proc/cpuinfo | ...
- C#.NET ObjectDumper
demo: using System; using System.Collections.Generic; using System.Linq; using System.Text; using Sy ...
- SQL 替换指定列中的指定字符串
Update 表名 Set 列名 = Replace(列名,‘被替换的字符’,‘要替换的字符’) Demo: UPDATE BPM_DailySET Workstation = REPLACE(Wor ...
- Android调用WebService(转)
Android调用WebService WebService是一种基于SOAP协议的远程调用标准,通过 webservice可以将不同操作系统平台.不同语言.不同技术整合到一块.在Android SD ...
- Ubuntu 11.10升级Ruby (1.8.7 --> 1.9.3或者其他任意版本)
使用apt-get install ruby,安装的默认版本为1.8.7.想要使用更高版本,只能采用手工升级的方式. 方式1 使用RVM(推荐方式) 1 安装RVM http://rvm.io/rvm ...
- Xamarin Anroid开发教程之验证环境配置是否正确
Xamarin Anroid开发教程之验证环境配置是否正确 经过前面几节的内容已经把所有的编程环境设置完成了,但是如何才能确定所有的一切都处理争取并且没有任何错误呢?这就需要使用相应的实例来验证,本节 ...