如何在矩池云复现开源对话语言模型 ChatGLM
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
今天给大家分享如何在矩池云服务器复现 ChatGLM-6B,用 GPU 跑模型真是丝滑啊。
硬件要求
如果是GPU: 显存需要大于6G。

- ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
- ChatGLM-6B-INT8 是 ChatGLM-6B 量化后的模型权重。具体的,ChatGLM-6B-INT8 对 ChatGLM-6B 中的 28 个 GLM Block 进行了 INT8 量化,没有对 Embedding 和 LM Head 进行量化。量化后的模型理论上 8G 显存(使用 CPU 即内存)即可推理,具有在嵌入式设备(如树莓派)上运行的可能。
- ChatGLM-6B-INT4 是 ChatGLM-6B 量化后的模型权重。具体的,ChatGLM-6B-INT4 对 ChatGLM-6B 中的 28 个 GLM Block 进行了 INT4 量化,没有对 Embedding 和 LM Head 进行量化。量化后的模型理论上 6G 显存(使用 CPU 即内存)即可推理,具有在嵌入式设备(如树莓派)上运行的可能。
如果是CPU: 内存需要大于32G。
云服务器配置
如果你自己没有显卡,或者电脑运行内存不怎么办?很简单,租一个云电脑就可以了,今天将教大家如何在矩池云上复现 ChatGLM。
以下步骤需要在电脑上操作,手机屏幕太小不好操作!
注册账号
直接在矩池云官网进行注册,注册完成后可以关注矩池云公众号可以获得体验金,可租用机器进行测试配置。
上传模型文件
由于 Huggingface 下载不稳定,建议大家本地先下载好相关模型文件。
- FP16 无量化模型下载地址:https://huggingface.co/THUDM/chatglm-6b
- INT8 模型下载地址:https://huggingface.co/THUDM/chatglm-6b-int8
- INT 4模型下载地址:https://huggingface.co/THUDM/chatglm-6b-int4
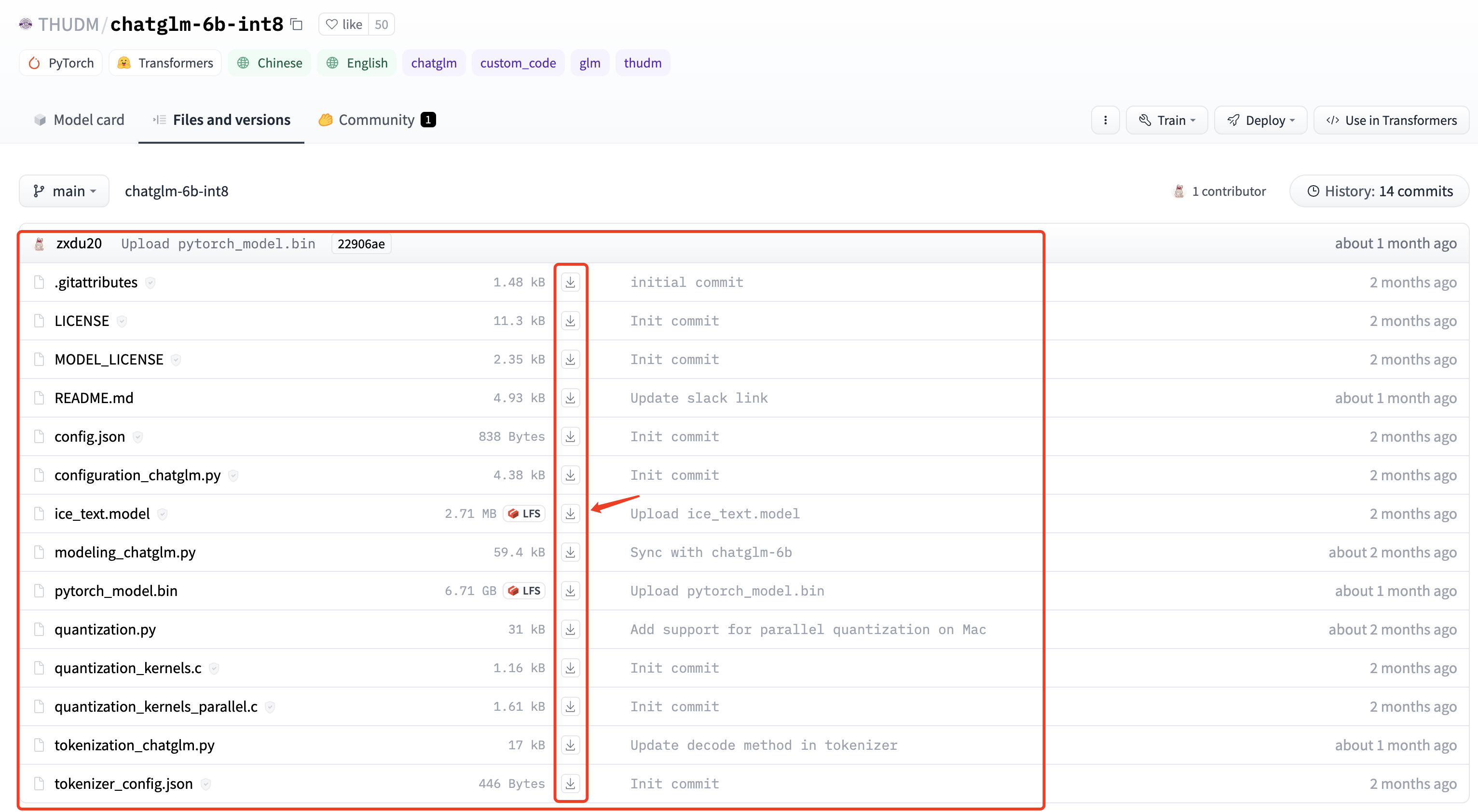
本地下载方法:
- 安装 git
- 安装 git lfs: 直接官网下载安装包安装即可 https://git-lfs.com/
- 使用 git lfs 下载
# 初始化
git lfs install
# 下载
git clone https://huggingface.co/THUDM/chatglm-6b-int4
大家本地下载好后,上传到云平台网盘(可离线上传不花钱)。
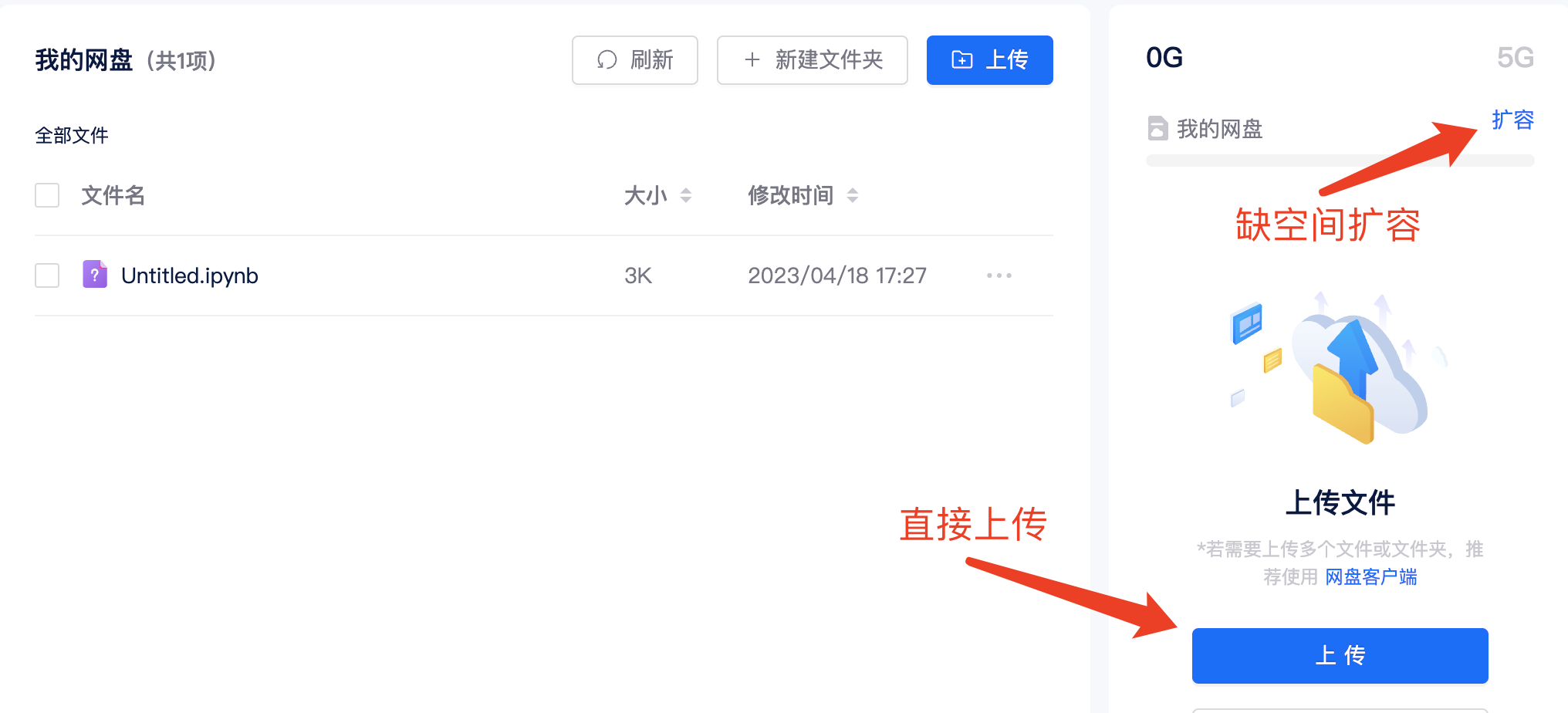
- 方法1: 直接通过矩池云网盘上传 https://matpool.com/user/matbox
不用租用机器传数据
上传后如果空间不够,需要进行扩容。
- 方法2: 租用机器后,通过 scp 上传数据
需要花钱开机传数据,每次租用都得上传,不方便。
比如你租用机器后显示 ssh 链接为:ssh -p 26378 root@matpool.com
本地打开CMD/PowerShell/终端,输入下面指令进行数据传输:
scp -r -P 26378 本地文件/文件夹路径 root@matpool.com:/home
这样数据会上传到租用机器的 /home 目录下。
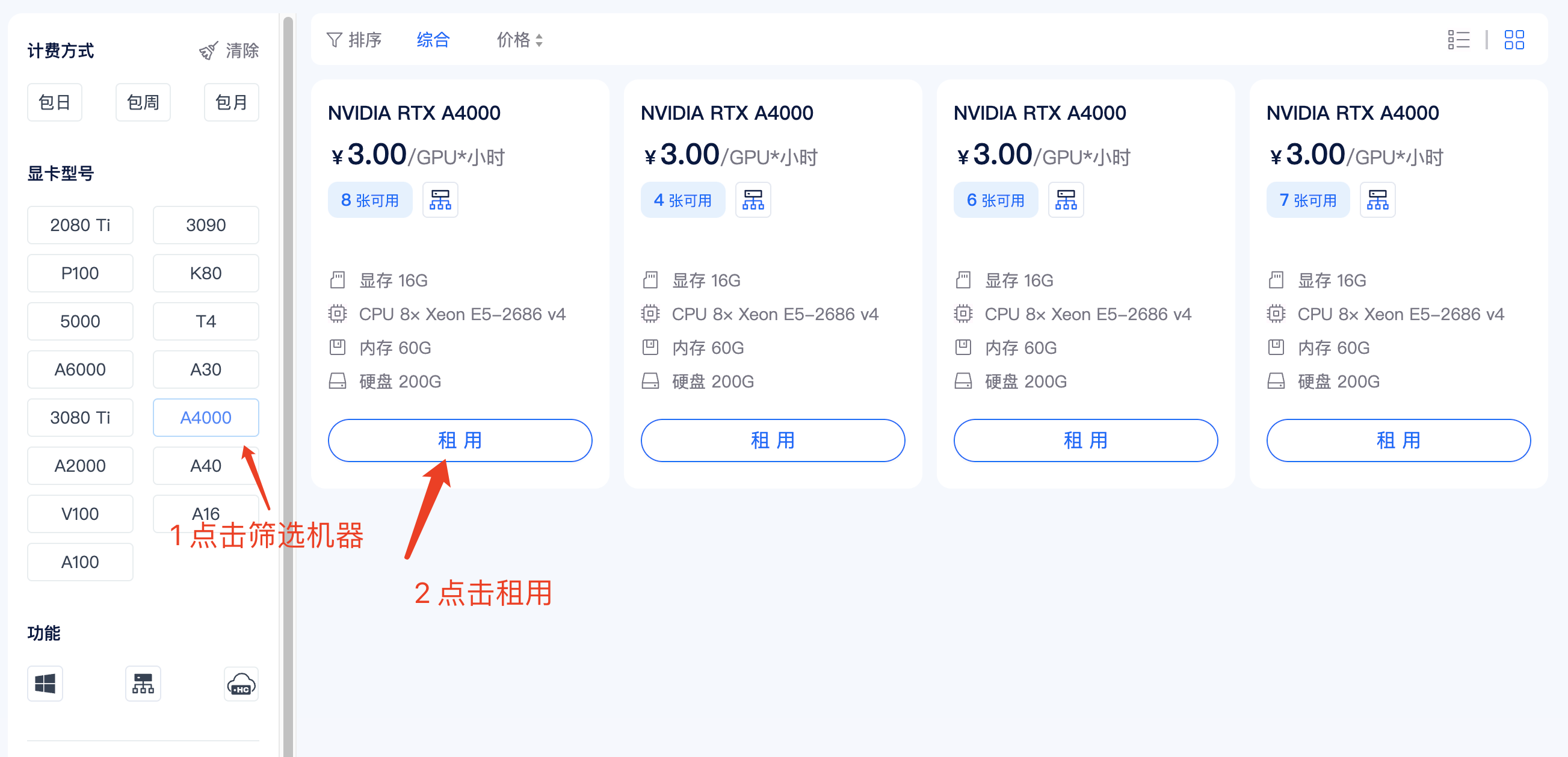
租用机器
在矩池云主机市场:https://matpool.com/host-market/gpu,如果复现 FP16无量化模型,至少需要选择 A4000 显卡;如果复现 INT4或者INT8模型,至少需要选择 A2000 显卡。 然后点击租用按钮。(你选其他显卡也行)
租用页面,搜索 pytorch1.11,选择这个镜像,我就是用这个镜像复现的 ChatGLM-6B。
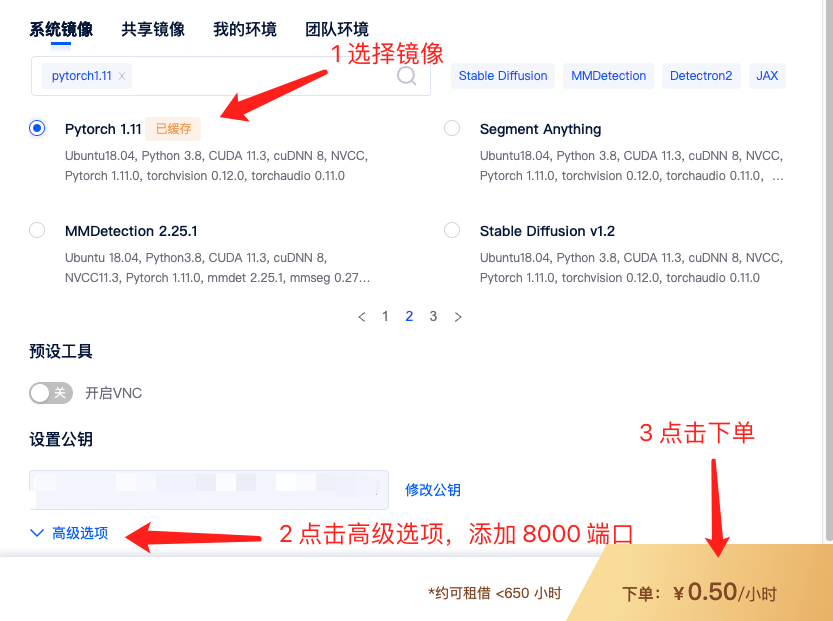
选择镜像后在高级选项里添加一个 8000 端口,后面部署 Web 服务用。
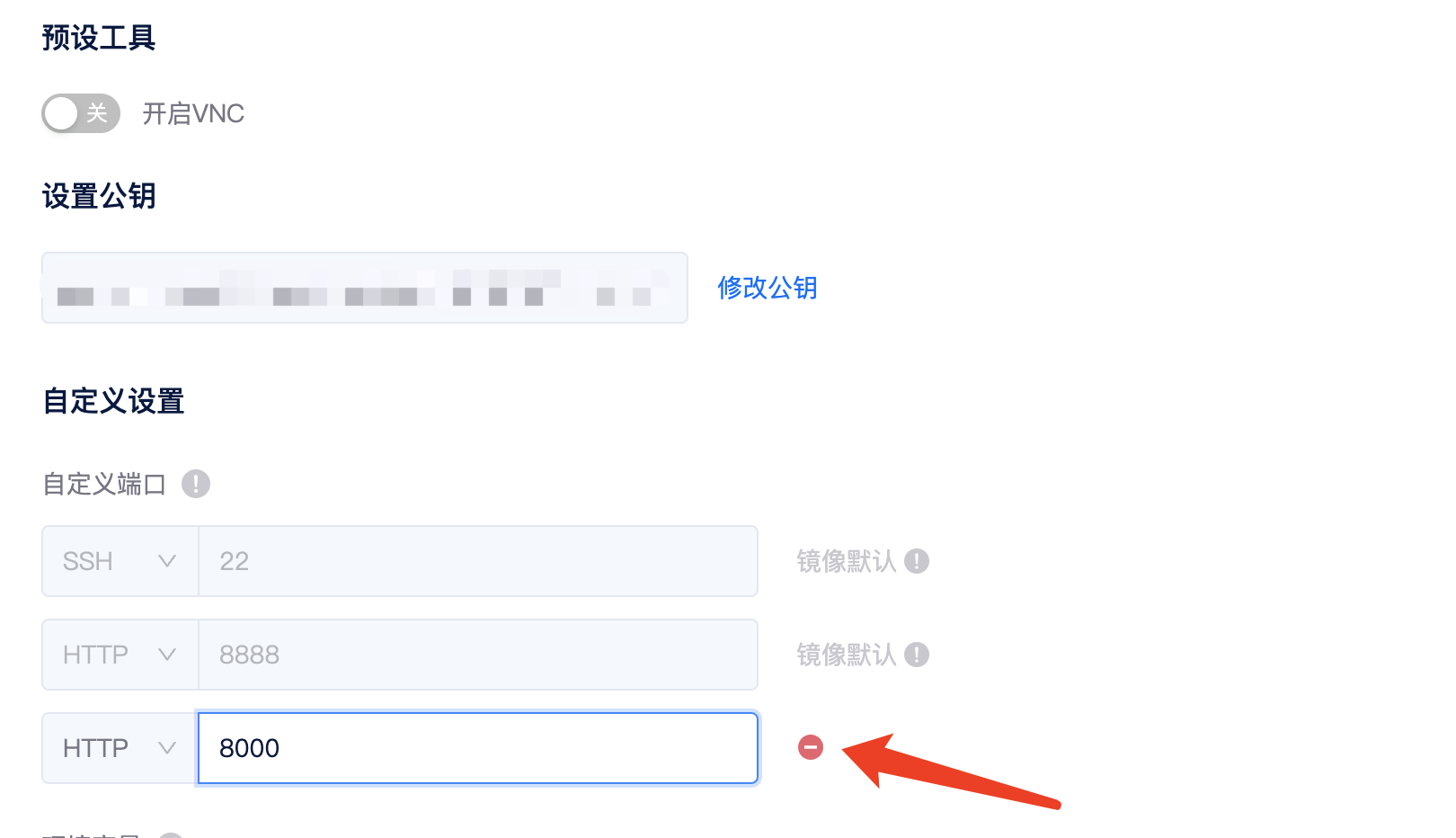
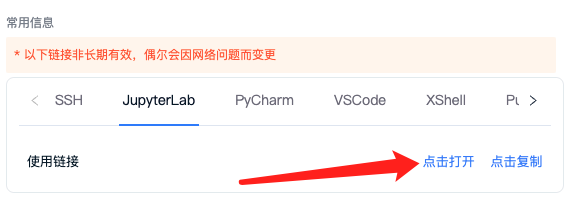
机器租用成功后点击 Jupyterlab 点击打开,即可快速打开 Jupyterlab,开始运行代码了。
环境配置+代码运行
在自己电脑配置进行的安装 miniconda和安装 Python3.9以及安装Nvidia驱动+Cuda都不用操作,因为矩池云已经帮我们配置好了。
1> Clone项目代码
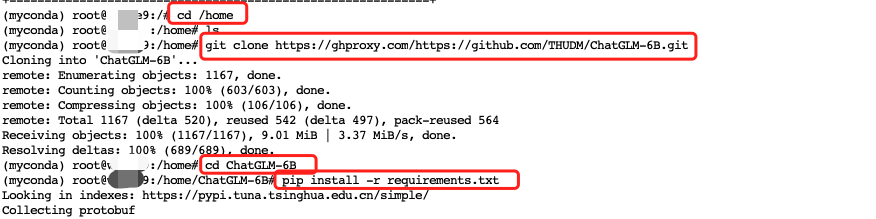
你也可以自己 clone 代码,代码我们存到 /home 下。
cd /home
git clone https://ghproxy.com/https://github.com/THUDM/ChatGLM-6B.git
项目目录结构:
.
├── PROJECT.md
├── README.md
├── README_en.md
├── api.py # 应用层:GLMAPI 版本
├── cli_demo.py # 应用层:GLMCLI 版本
├── examples
├── limitations
├── ptuning
├── requirements.txt # 依赖:项目Python依赖
├── resources
├── utils.py
├── web_demo.py # 应用层:GLMWEB 版本
├── web_demo2.py # 应用层:GLMWEB2 版本
└── web_demo_old.py # 应用层:GLMWEB3 版本
2> 安装项目依赖包
# 进入项目目录
cd ChatGLM-6B
# 安装依赖
pip install -r requirements.txt
3> 下载模型文件
在最开始你应该就已经下载好模型,并把相关文件上传到服务器了。
将网盘模型文件夹复制到项目文件夹下,按以下操作创建:
mkdir /home/ChatGLM-6B/THUDM
cd /home/ChatGLM-6B/THUDM
# 将网盘下的 chatglm-6b-int4 模型文件夹复制到当前目录(/home/ChatGLM-6B/THUDM)
cp -r /mnt/chatglm-6b-int4 ./
测试运行
在 /home/ChatGLM-6B 下新建一个 notebook,
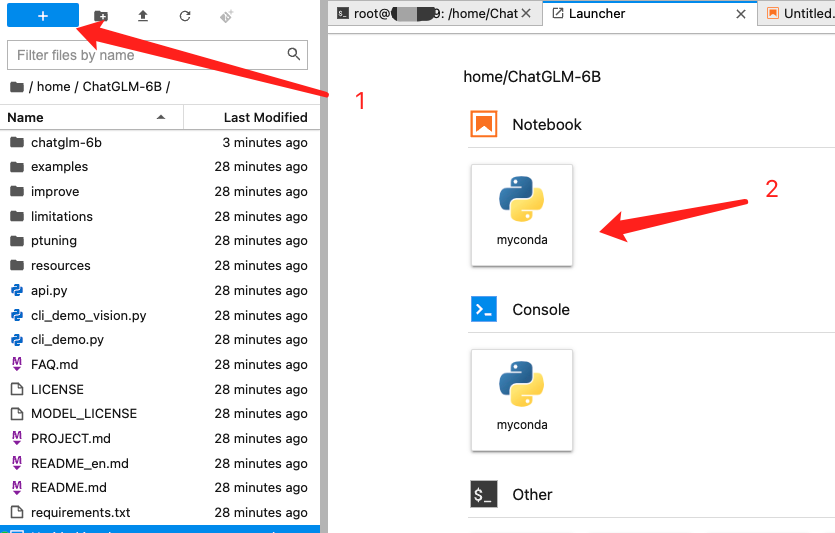
- 测试运行
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True)
# CPU
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True).float()
# GPU
# model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True).half().cuda()
model = model.eval()
response, history = model.chat(tokenizer, "你好, 自我介绍下,我可以用你做什么", history=[])
print(response)
首先会检查模型是否正确~

简单问个问题,2-3s 可以出答案:

response, history = model.chat(tokenizer, "Python写一个Excel表合并脚本", history=[])
print(response)
问代码的话运行稍微慢点~得10-20s左右。
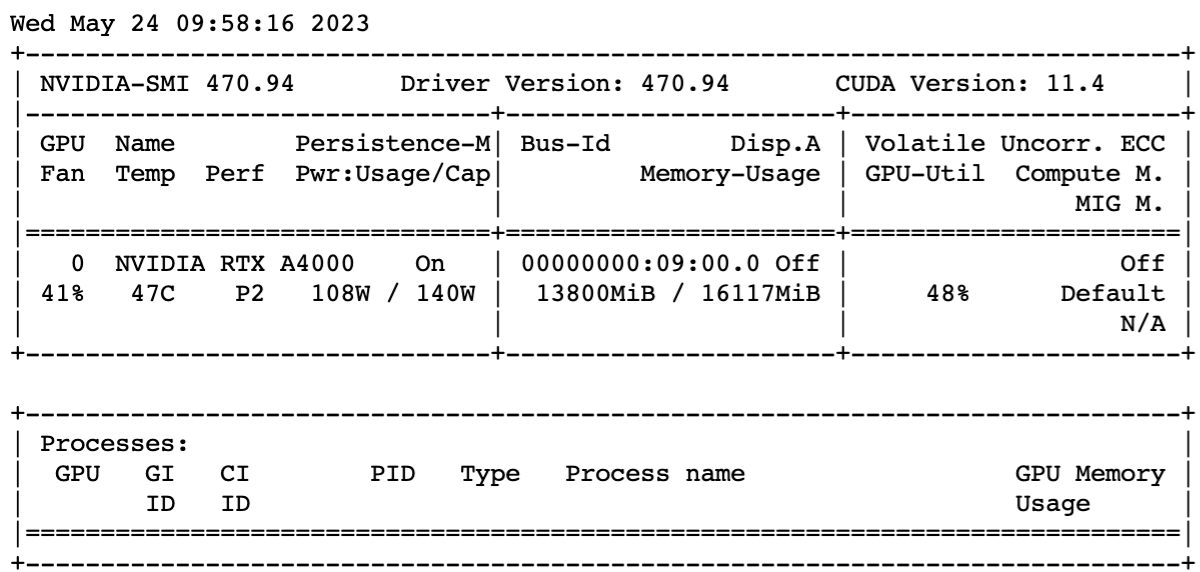
GPU使用情况:
response, history = model.chat(tokenizer, "我现在有个csv数据表, 表头是:用户手机号 上次登录时间 超出空间,需要统计指定日期前登录用户超出空间总和,并打印这些用户手机号;另外还需要统计超出指定容量用户的总超出空间数,并打印这些用户手机号,使用python pandas 实现,假设数据文件为:123.csv", history=[])
print(response)
对于复杂问题,等待时间更长40s左右,回复的代码里参数命名竟然还有中文!!!

- GLMCLI 版本 运行
# 进入项目目录
cd /home/ChatGLM-6B
# 启动脚本
python cli_demo.py
效果如图所示:

- GLMAPI 版本 运行
# 进入项目目录
cd /home/ChatGLM-6B
# 启动脚本
python api.py

启动成功后,服务在 8000 端口,你需要发送POST请求。前面租用机器我们自定义了 8000 端口,在租用页面可以获得对应的公网链接:
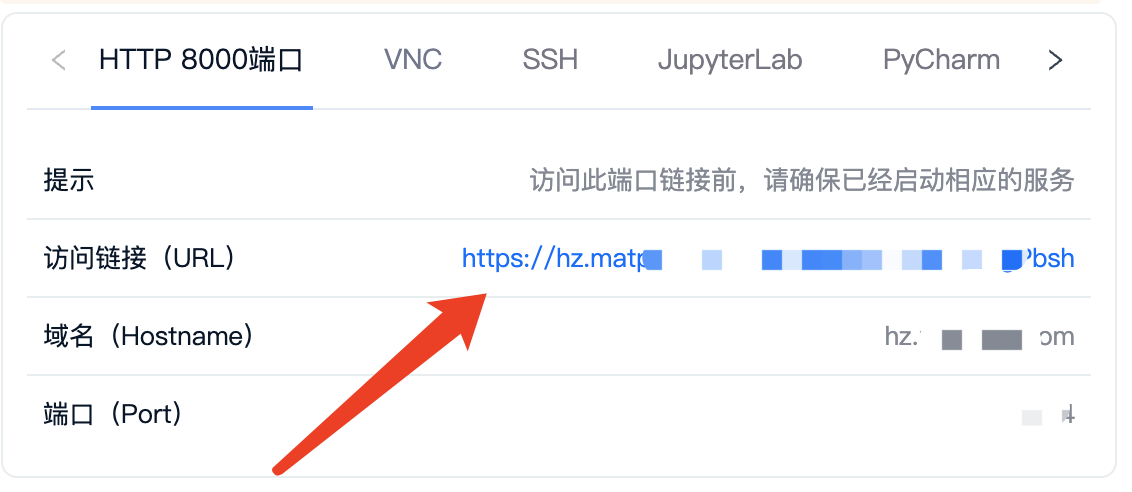
比如:https://hz.xxxx.com:xxxx/?token=xxxxx
需要注意,实际我们请求不需要 token,所以直接用:https://hz.xxxx.com:xxxx 这段即可。
curl请求:
curl -X POST "https://hz.xxxx.com:xxxx" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
Python请求:
import requests
import json
def getGLM(prompt, history):
'''
curl -X POST "https://hz.xxxx.com:xxxx" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
'''
url = 'https://hz.xxxx.com:xxxx'
# 设置请求头
headers = {
'Content-Type': 'application/json'
}
data = {
'prompt': prompt,
'history': history
}
# 发送请求并获取响应
response = requests.post(url, headers=headers, data=json.dumps(data))
# 检查响应状态码
if response.status_code == 200:
# 获取响应数据
rsp = response.json()
return rsp
else:
print('请求失败,状态码:', response.status_code)
# 测试请求
history=[]
prompt = "假设你是一位Python高手,请用Python Pandas 模块实现一个Excel文件批量合并脚本"
getGLM(prompt, history)
和服务器上直接请求速度差不多,30s左右。
- GLMWEB3 版本 运行
# 进入项目目录
cd /home/ChatGLM-6B
# 安装依赖
pip install streamlit streamlit_chat
# 启动脚本
streamlit run web_demo2.py --server.port 8000 --server.address 0.0.0.0

运行后服务会启动到 8000端口,host 设置成0.0.0.0,这样我们访问租用页面 8000 端口链接即可访问到对应服务了。
前面租用机器我们自定义了 8000 端口,在租用页面可以获得对应的公网链接:
比如:https://hz.xxxx.com:xxxx/?token=xxxxx
需要注意,实际我们请求不需要 token,所以直接用:https://hz.xxxx.com:xxxx 这段即可。

这个第一次运行可能比较慢,它是提问的时候才开始加载检查模型。
说实话,这个问题的回答有点出乎意料,给了一个用 pygame 写的猜数游戏,一般都会回复那种 cmd 版本。

如何在矩池云复现开源对话语言模型 ChatGLM的更多相关文章
- 在矩池云上复现 CVPR 2018 LearningToCompare_FSL 环境
这是 CVPR 2018 的一篇少样本学习论文:Learning to Compare: Relation Network for Few-Shot Learning 源码地址:https://git ...
- 如何使用 PuTTY 远程连接矩池云主机
PuTTY 是一款开源的连接软件,用来远程连接服务器,支持 SSH.Telnet.Serial 等协议. 矩池云的主机支持 SSH 登录,以下为使用 PuTTY 连接矩池云 GPU 的使用教程. 如您 ...
- 矩池云 | Tony老师解读Kaggle Twitter情感分析案例
今天Tony老师给大家带来的案例是Kaggle上的Twitter的情感分析竞赛.在这个案例中,将使用预训练的模型BERT来完成对整个竞赛的数据分析. 导入需要的库 import numpy as np ...
- 矩池云上使用nvidia-smi命令教程
简介 nvidia-smi全称是NVIDIA System Management Interface ,它是一个基于NVIDIA Management Library(NVML)构建的命令行实用工具, ...
- 矩池云里查看cuda版本
可以用下面的命令查看 cat /usr/local/cuda/version.txt 如果想用nvcc来查看可以用下面的命令 nvcc -V 如果环境内没有nvcc可以安装一下,教程是矩池云上如何安装 ...
- 矩池云上安装yolov4 darknet教程
这里我是用PyTorch 1.8.1来安装的 拉取仓库 官方仓库 git clone https://github.com/AlexeyAB/darknet 镜像仓库 git clone https: ...
- 用端口映射的办法使用矩池云隐藏的vnc功能
矩池云隐藏了很多高级功能待用户去挖掘. 租用机器 进入jupyterlab 设置vnc密码 VNC_PASSWD="userpasswd" ./root/vnc_startup.s ...
- 矩池云上安装ikatago及远程链接教程
https://github.com/kinfkong/ikatago-resources/tree/master/dockerfiles 从作者的库中可以看到,该程序支持cuda9.2.cuda10 ...
- 矩池云上编译安装dlib库
方法一(简单) 矩池云上的k80因为内存问题,请用其他版本的GPU去进行编译,保存环境后再在k80上用. 准备工作 下载dlib的源文件 进入python的官网,点击PyPi选项,搜索dilb,再点击 ...
- 如何在矩池云上运行FinRL-Libray股票交易策略框架
FinRL-Libray 项目:https://github.com/AI4Finance-LLC/FinRL-Library 选择FinRL镜像 在矩池云-主机市场选择合适的机器,并选择FinRL- ...
随机推荐
- [转帖]kubelet 原理解析六: 垃圾回收
https://segmentfault.com/a/1190000022163856 概述 在k8s中节点会通过docker pull机制获取外部的镜像,那么什么时候清除镜像呢?k8s运行的容器又是 ...
- 一次w3wp出现crash的简单解决方案
1. 前几天同事求助, 说一台服务器iis出现多次崩溃的现象,重启iis就可以了. 具体原因不明. 之前遇到过类似的问题 感觉最彻底的解决方案是 抓dump然后使用windbg 进行分析. 但是自 ...
- [译]深入了解现代web浏览器(四)
本文是根据Mariko Kosaka在谷歌开发者网站上的系列文章https://developer.chrome.com/blog/inside-browser-part4/翻译而来,共有四篇,该篇是 ...
- CS231N Assignment3 笔记(更新中)
在这项作业中,将实现语言网络,并将其应用于 COCO 数据集上的图像标题.然后将训练生成对抗网络,生成与训练数据集相似的图像.最后,您将学习自我监督学习,自动学习无标签数据集的视觉表示.本作业的目标如 ...
- diff算法是如何比较的,保证让你看的明明白白的!
更新dom节点,最小力度去跟新 index.html <body> <h1>你好啊!</h1> <button id="btn">该 ...
- justify-content: space-between能够对齐的解决办法
解决办法一 .main{ display: flex; justify-content: space-around; flex-wrap: wrap; } .son{ width:100px } // ...
- git提交出现running pre-commit hook: lint-staged
现象 今天提交代码的时候出现了 > running pre-commit hook: lint-staged Stashing changes... [started] Stashing cha ...
- 时不我待,拥抱趋势,开源IM项目OpenIM技术简介
坚持开源 开源的理念是基于共享.合作和透明的原则,将软件.代码等知识资源公开并允许他人使用.修改和重新分发,以促进创新和发展.以下是几个开源的优点: 创新:开源可以促进创新,通过让其他人改进或扩展已有 ...
- Similarities:精准相似度计算与语义匹配搜索工具包,多维度实现多种算法,覆盖文本、图像等领域,支持文搜、图搜文、图搜图匹配搜索
Similarities:精准相似度计算与语义匹配搜索工具包,多维度实现多种算法,覆盖文本.图像等领域,支持文搜.图搜文.图搜图匹配搜索 Similarities 相似度计算.语义匹配搜索工具包,实现 ...
- 7.3 C/C++ 实现顺序栈
顺序栈是一种基于数组实现的栈结构,它的数据元素存储在一段连续的内存空间中.在顺序栈中,栈顶元素的下标是固定的,而栈底元素的下标则随着入栈和出栈操作的进行而变化.通常,我们把栈底位置设置在数组空间的起始 ...